Artículos
Recuperación de la información sobre la producción de la investigación científica de la Universidad Nacional Autónoma de México en Scopus y Web of science
Information retrieval on the production of scientific research of the National Autonomous University of Mexico in Scopus and Web of Science
Recuperación de la información sobre la producción de la investigación científica de la Universidad Nacional Autónoma de México en Scopus y Web of science
Biblioteca Universitaria, vol. 18, núm. 2, 2015
Dirección General de Bibliotecas de la UNAM
Resumen: Conocer la producción científica de los investigadores de la Universidad Nacional Autónoma de México (UNAM) es una prioridad en la Coordinación de la Investigación Científica. Con esta finalidad la Dirección General de Bibliotecas (DGB) de la UNAM realizó una investigación teniendo como base a 1 614 investigadores, para conocer su producción científica consultando las bases de datos Scopus y Web of Science. Se analiza la problemática en la búsqueda y recuperación de información bajo el nombre de los investigadores, situación que da origen al Catálogo de Artículos - Coordinación de la Investigación Científica, UNAM (CIC). El CIC contiene las referencias bibliográficas y textos completos de la producción científica de los investigadores pertenecientes a la Coordinación de la Investigación y la normalización (control de autoridad) de los nombres de cada uno de los investigadores e instituciones a las que están afiliados
Palabras clave: Producción científica, Coordinación de la Investigación Científica, Universidad Nacional Autónoma de México, Control de autoridad, Scopus, Web of Science.
Abstract: Knowing the scientific production of researchers from UNAM is of high priority in the Coordination of Scientific Research. To this end the General Directory for Libraries at UNAM conducted an investigation on 1 614 scientific researchers to know their production, by searching Scopus and Web of Science data bases. The problem is analyzed in the retrieval of information when searching by the name of researchers, a situation that gave rise to the creation of the Paper Index - Coordination of Scientific Research UNAM (CIC). CIC contains bibliographic references and full texts of the scientific production of researchers from the Coordination of Scientific Research and the standardization (authority control) of the names of each of the researchers and institutions they are affiliated to
Keywords: Scientific production, Coordination of Scientific Research, National Autonomous University of Mexico, Authority control, Scopus, Web of Science.
Introducción
A petición de la Coordinación de la Investigación Científica de la Universidad Nacional Autónoma de México (UNAM), la Dirección General de Bibliotecas realizó una investigación de 1 614 autores para conocer su producción científica y saber con cuáles instituciones nacionales o internacionales colaboran. Ésta se llevó a cabo en las bases de datos internacionales Scopus y Web of Science y posibilitó, además, la creación de una nueva base de datos que contiene la producción científica de los investigadores pertenecientes a dicha Coordinación.
Las bases de datos Scopus y Web of Science contienen resúmenes y referencias bibliográficas de literatura científica revisada por pares y juntas reúnen más de 27 mil títulos de revistas. Permiten conocer lo que se publica en el área de la investigación científica, proporcionan información de los autores, su afiliación y la citación de sus trabajos. Las opciones de búsqueda son por autor, título del artículo, título de la revista, afiliación y temas. Son instrumentos de apoyo a la investigación que aportan, en algunos casos, información en texto completo siempre y cuando la biblioteca tenga la suscripción a las revistas.
A fines de 2012 se inició el desarrollo de la base de datos que lleva el nombre de "Catálogo de Artículos - Coordinación de la Investigación Científica, UNAM" (CIC), la cual contiene las referencias obtenidas de Scopus y Web of Science.
Esta base de datos contenía 21 882 registros proporcionados por la Coordinación de la Investigación Científica y venían con elementos mínimos como el autor, título del artículo, título de la revista, volumen, número de la revista, páginas, en mayúsculas compactas las cuales fueron convertidas en altas y bajas. Estos registros fueron investigados en fuentes internacionales y complementados con los demás autores participantes, su función, temas proporcionados por los mismos autores, y se normalizó la o las afiliaciones de los autores. Más adelante se tomó la decisión de agregar a la nueva base otros documentos tales como los libros publicados y las tesis donde los investigadores hayan tenido alguna participación en la creación o realización de las obras.
Durante el proceso se observó la falta de uniformidad de los nombres de los autores en las bases de datos consultadas. Las inconsistencias generan dispersión de la información, aunada a la falta de un catálogo de autoridad que normalice las diferentes formas del nombre de una persona.
La recuperación de la información se realizó por la afiliación del autor, en este caso por la Universidad Nacional Autónoma de México y por todas las variables del nombre que se detectaron durante la búsqueda, todo lo cual, de inicio, parecía una labor prácticamente imposible.
Inicialmente, se desarrollaron los registros de autoridad de los nombres de 1 614 investigadores de la UNAM y, posteriormente, de otros autores que fueron recuperados en la búsqueda del periodo de 1960 a 2013. Adicionalmente se relacionó el catálogo de autoridad de LIBRUNAM con todos los registros de la base de datos CIC.
Obtención de los registros bibliográficos
Para obtener la mayor parte de la producción científica de los investigadores de la UNAM se determinaron las siguientes acciones:
- 1. La selección de las bases de datos Scopus y Web of Science, las cuales cuentan con las principales publicaciones periódicas científicas revisadas por pares, además de la citación de los trabajos indizados.
- 2. La recuperación de los registros del periodo 1960 a 2013
- 3. La definición de los identificadores: autores, título del artículo, fuente, año de publicación y volumen, entre otros, los cuales deberían estar declarados y ser compatibles con los elementos de la plantilla de la base de datos CIC.
- 4. La determinación de la afiliación, como la opción de búsqueda más factible para obtener los datos, realizándola por las diferentes variantes de la Universidad Nacional Autónoma de México.
- 5. La selección del formato Excel, para la salida de los registros y poder transferirlos a la base de datos CIC.
- 6. Agregar los registros bibliográficos de libros y tesis que se encuentran en los catálogos LIBRUNAM y TESIUNAM, respectivamente.
Obtención de los registros en SCOPUS
En la base de datos Scopus se utilizó la opción "Affiliation search", la cual permite buscar en el identificador (afiliación) el nombre de una institución relacionada con los autores de los artículos; se ingresa el nombre de la institución y automáticamente se resolverán las variantes de nombre. (Imagen 1)

Imagen 1
Opción de búsqueda affiliation search.
Se muestra una lista de todas las instituciones afiliadas en la que puede seleccionarse la institución de interés. Los resultados incluyen el número de documentos que ha publicado una institución y el vínculo. Se puede elegir entre visualizar los resultados por número de documentos, ciudad o país. (Imagen 2)

Imagen 2
Presentación de los resultados por afiliación.
Se eligió visualizar el número de documentos por institución para transferirlos al formato de salida Excel. Una limitante de Scopus es que no permite bajar los registros en forma global, por lo que se hizo en bloques de 2 mil registros delimitados con los siguientes identificadores: año de publicación y dentro del año, por área temática, seleccionando solamente aquellos campos que correspondan a la investigación científica. (Imágenes 3 y 4 )
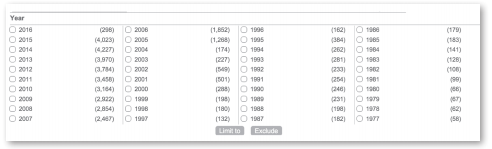
Imagen 3
Opción para limitar los resultados por año de publicación.

Imagen 4
Áreas temáticas para delimitar los resultados de la búsqueda.
Con el propósito de que la transferencia fuera lo más transparente, se seleccionaron los datos comunes entre las bases Scopus y CIC. (Imagen 5)

Imagen 5
Selección de los campos comunes entre Scopus y CIC.
Por último, se determinó el CSV (Excel) como el formato de salida de los registros para después analizarlos, prepararlos y transferirlos a la base de datos CIC. (Imágenes 6 y 7 )

Imagen 6
Opción para seleccionar el formato de salida de los registros.

Imagen 7
Presentación de los archivos en formato Excel para analizarlos, prepararlos y transferirlos a la base de datos CIC.
Obtención de los registros en Web of Science
Para obtener los registros en Web of Science se siguió el mismo procedimiento que en la base de datos anterior. En Web of Science se utilizó la opción "Organizaciones-Nombre preferido", que permite buscar el nombre preferido o variantes de una institución. Posteriormente se delimitó la búsqueda a Science Citation Index Expanded (SCI-EXPANDED) 1900-presente, para obtener registros que correspondan a la investigación científica. (Imagen 8)
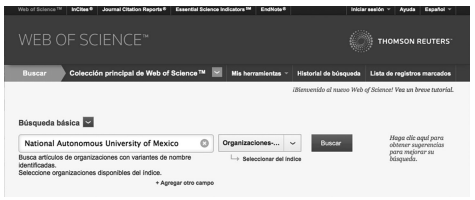
Imagen 8
Opción de búsqueda Organizaciones-Nombre preferido.
En la siguiente lista se muestra el número de resultados obtenidos y la forma de cómo se realizó la búsqueda, refinando los resultados por año de publicación. (Imagen 9)

Imagen 9
Presentación de los resultados por Organizaciones-Nombre preferido.
Todos los registros bibliográficos que aparecen en la página de resultados son registros fuente. Éstos proceden de revistas, libros, conferencias y patentes que se indexaron. Cada registro fuente tiene un registro completo al que se puede acceder. Se seleccionó el formato de salida (Formato delimitado por tabulador (win, utf-8)) para exportar los registros. Una limitante de Web of Science es que no permite exportar los registros en forma global, por lo cual se tuvo que limitar en bloques de 500 registros. (Imágenes 10 y 11 )

Imagen 10
Opción para seleccionar el formato de salida de los registros.

Imagen 11
Aviso de advertencia que indica la cantidad de registros que pueden exportarse.
Se obtiene un archivo.txt que se convirtió en Excel para ser modificado con los datos comunes entre las bases de datos. (Imagen 12)

Imagen 12
Archivo.txt con los registros exportados de Web of Science.
Los archivos de salida en formato Excel, con los elementos comunes, son enviados para ser analizados y preparados para transferirlos a la base de datos CIC. (Imagen 13)

Imagen 13
Presentación en formato Excel de los archivos para ser analizados y preparados para transferirlos a CIC.
Análisis y preparación de los archivos para su importación a CIC
Antes de almacenar los registros bibliográficos en la base de datos CIC se realizó la normalización de los datos en los archivos Excel de las bases de datos Scopus y Web of Science. El proceso de normalización consistió en determinar las etiquetas marc21 para cada uno de los elementos que se encontraban en los archivos de salida (archivo Excel). Para realizar la normalización se desarrollaron las siguientes actividades:
- 1. Diseño de una base de datos en el gestor "MYSQL", con el propósito de almacenar temporalmente la información de los registros bibliográficos para normalizarlos antes de agregarlos al gestor.
- 2. Desarrollo de una aplicación para la lectura de los archivos con formato Excel y comparación de los registros almacenados en la base de datos a través de los datos de título, tema y DOI.
- 3. Desarrollo de aplicaciones para transformar la información de la base de datos temporal considerando diversos procesos:
- 1. Agregar etiquetas de acuerdo al formato MARC, así como códigos de sub-campo.
- 2. Generar elementos con información fija requerida por el gestor.
- 3. Establecer claves de acuerdo a catálogos.
- 4. Separar autores, domicilios, instituciones y temas.
Previo a la importación de los registros a CIC se desarrollaron también aplicaciones para normalizar la información contenida en los archivos Excel mencionados anteriormente, ya que su formato no tenía la estructura adecuada para su ingreso.
En el proceso de normalización se diseñó una base de datos temporal con el propósito de realizar las revisiones pertinentes antes de almacenar la información en forma definitiva en la base de datos CIC. De las observaciones detectadas la más importante es la referente a la duplicidad de los registros de los artículos, alcanzando un porcentaje del 12 % aproximadamente, aunque por la forma del contenido había pocas probabilidades de reducirlos ya que no eran iguales. Algunos títulos diferían hasta en 8 caracteres, con patrones diferentes entre los que destacan los siguientes: signo ἄλφα y la leyenda "alfa" o "α"; signo βῆτα y la leyenda "beta" o "β"; números romanos y texto del número; números arábigos y texto del número; errores de tecleo y signos especiales.
La solución para reducir los registros de artículos duplicados de acuerdo a los puntos antes señalados se realizó a través del desarrollo de una aplicación con diversos módulos que efectuaron los siguientes procesos:
-
Eliminación de los espacios en el campo de título del artículo.
-
Eliminación de los siguientes caracteres: "'.,;:[]{}+?%&/-¡*+´'=_!-|#$()<>.
-
Conversión a letras mayúsculas.
-
Clasificación alfabética de la cadena resultante de las etapas anteriores.
-
Aplicación del algoritmo de distancia de Levenshtein (1965), que consiste en que dadas dos secuencias de caracteres debe medir cuáles son los cambios mínimos para que a partir de una cadena de caracteres obtengamos la otra. En el caso de la duplicidad de los títulos de los artículos se tomó la cadena del nombre del artículo y se comparó con los siguientes cinco registros de cadenas de artículos, respetando el orden en el que fueron establecidos por el proceso de clasificación y, además, definiendo parámetros acerca de cuántos fallos se permitirían en las comparaciones.

Normalmente los procesos de comparación de cadenas de caracteres se realizan contra un directorio o índice, pero el resultado concluye determinando únicamente si son o no iguales. En el caso de los títulos de los artículos era importante verificar que hubiera el mínimo de duplicidad, con el propósito de proporcionar servicios de búsqueda adecuados.
A continuación se presentan algunos ejemplos de las cadenas de caracteres que fueron detectadas en el proceso de comparación.
Problemática
Una vez que los registros de Scopus y Web of Science fueron importados a la base de datos CIC se detectaron una serie de problemas en los índices de autor y afiliación de la CIC. Esta situación provocó que los resultados en la búsqueda no fueran confiables. Entre éstos destacan:
-
Las diferentes formas de registrar a las instituciones afiliadas de los autores.
-
Las diferentes formas de registrar a los autores de los artículos.
-
El cambio de orden de los autores de acuerdo al documento original.
-
Autores diferentes bajo una misma forma del nombre.
Como ejemplo, el caso del nombre de la Universidad Nacional Autónoma de México. La forma variante UNAM se encontró con puntos y espacios, con puntos sin espacios, diferentes formas abreviadas del nombre completo, con errores de digitación, con forma variante del nombre en otro idioma (inglés):
U. N. A. M.
U.N.A.M.
Univ. Nac. Auton.
Univ. Nac. Auton. de México
Univ. Nac. Auton. Mexico
Univ. Nac. Auton., Mexico
National Autonomous University, Mexico
National Autonomous University, Mexico City, Mexico
Con respecto a las entidades subordinadas en el índice de CIC, por afiliación se detectaron una gran variedad de formas variantes. Otro problema fue el de los códigos postales y direcciones de las diferentes afiliaciones, las cuales aparecían con inconsistencias de digitación, en abreviaturas y en puntuación. Este problema se corrigió directamente en el archivo de las afiliaciones, se eliminaron las direcciones y se unificaron los organismos; además, se detectaron autores sin o con diferentes afiliaciones. (Imagen 14)

Imagen 14
Archivo en el que se unificaron las formas variantes del nombre de la UNAM, entidades subordinadas y eliminación de dirección.
Una vez realizados los cambios de los casos mencionados se ingresaron a la base de datos CIC en la forma correcta, mostrándose ahora una sola forma autorizada del nombre de la UNAM y de sus entidades subordinadas. (Imagen 15)

Imagen 15
Índice de afiliación unificada del nombre de la UNAM.
El índice de afiliación incluye las instituciones de educación superior extranjeras; en el caso de los artículos en colaboración la afiliación de los otros autores. (Imagen 16)

Imagen 16
Índice de afiliación de las instituciones de educación superior extranjeras (artículos en colaboración).
Otro problema que afectaba la recuperación de información fue la sinonimia en la forma de los nombres de los autores, por ejemplo: Cuevas, S (Cuevas, Salvador, y Cuevas, Sergio). En ambos casos el sistema juntó los artículos de autores diferentes bajo una misma forma; una vez hechos los respectivos registros de autoridad se determinó su atribución uno a uno. (Imágenes 17 y 18 )
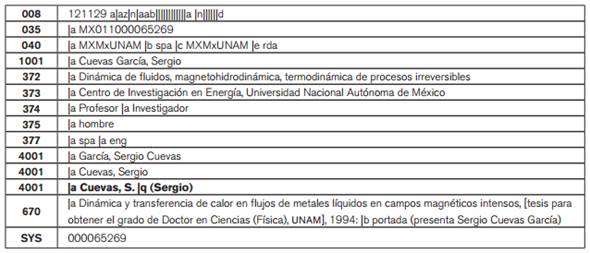
Imagen 17
Registro de autoridad para evitar conflicto de sinonimia en la forma de un nombre (Cuevas, Sergio).

Imagen 18
Registro de autoridad para evitar conflicto de sinonimia en la forma de un nombre (Cuevas, Salvador).
Los registros de autoridad que permiten la identificación de una persona incluyen los siguientes elementos: nombre preferido, nombre variante, lugar de nacimiento, fechas asociadas, campo de actividad, afiliación, género, idioma y la fuente que se consultó para obtener los datos. (Imagen 19)

Imagen 19
Registro de autoridad con los elementos núcleo para la identificación de una persona.
También se incluyó el ISNI (International Standard Name Identifier), con el fin de que se le identifique unívocamente en procesos como catalogación y localización de documentos. (Imagen 20)

Imagen 20
Número ISNI asignado y agregado al registro de autoridad del investigador.
Otra finalidad de crear registros de autoridad para los nombres de los investigadores es permitir la recuperación de un artículo sin que importe la forma que haya elegido el autor como nombre preferido, por ejemplo, el investigador Pérez Ramírez José G., utiliza el seudónimo Xim Bokhimi para firmar sus trabajos. (Imagen 21)

Imagen 21
Registro de autoridad que ayuda al usuario a buscar a una persona sin que importe la forma que elija para su nombre preferido.
La importancia de los catálogos de autoridad radica en permitir la recuperación bajo cualquier forma del nombre del autor (preferida o variante) y guiar al usuario a sus obras. Además, en esta base de datos se desarrollaron registros de autoridad para las afiliaciones de los autores de todas las entidades académicas existentes, incluyendo las entidades subordinadas.
Obtención de los registros en LIBRUNAM y TESIUNAM
Con el propósito de tener completa la producción científica de los 1 614 investigadores de la Coordinación de la Investigación Científica se consideró apropiado agregar otros recursos a la base de datos CIC.
Los registros de los nuevos recursos se tomaron de los catálogos desarrollados por la DGB:
-
De los libros en los que el investigador tuviera una participación como creador o como colaborador y se encuentren registrados en el catálogo LIBRUNAM. (Imagen 22)
-
De las tesis en las que el investigador tuviera participación como asesor, director o sinodal, entre otras modalidades, además de su propia tesis, y se encuentren registradas en el catálogo TESIUNAM. (Imagen 23)

Imagen 22
Registro LIBRUNAM agregado a la base de datos CIC.

Imagen 23
Registro TESIUNAM agregado a la base de datos CIC.
La base de datos CIC Algunos datos importantes de la base de datos CIC:

La base de datos CIC tiene varias opciones de búsqueda que permiten al usuario satisfacer sus necesidades de información: ya sea por palabras o por índice específico. (Imagen 24)

Imagen 24
Opciones de búsqueda de la base de datos CIC, por palabras o por índice.
En la opción de búsqueda Otros índices el usuario puede recuperar información de elementos más específicos, tales como título de la revista y afiliación del investigador. (Imagen 25)

Imagen 25
Opciones de búsqueda específicas disponibles en CIC.
Una de las ventajas de la base de datos CIC es la relación que tiene con los catálogos de autoridad (temas, personas y entidades corporativas), que permite la unificación de las formas autorizadas o variantes. (Imágenes 26 y 27 )
![Índice de autor donde se muestra la relación con el catálogo de autoridad [Registro de autoridad] para la normalización del nombre de una persona.](../0187-750X-biblioteca-18-02-00112-gf26.png)
Imagen 26
Índice de autor donde se muestra la relación con el catálogo de autoridad [Registro de autoridad] para la normalización del nombre de una persona.
![Índice de temas donde se muestra la relación con el catálogo de autoridad [Registro de autoridad] para la normalización de los temas que tratan los documentos.](../0187-750X-biblioteca-18-02-00112-gf27.png)
Imagen 27
Índice de temas donde se muestra la relación con el catálogo de autoridad [Registro de autoridad] para la normalización de los temas que tratan los documentos.
Una vez realizada la búsqueda, en los registros se pueden visualizar elementos básicos para su identificación. (Imagen 28)

Imagen 28
Visualización de un registro en CIC con los elementos básicos para su identificación.
Conclusiones Las bases de datos de Scopus y Web of Science conjuntamente son una herramienta de información científica de gran valor para los investigadores de la Universidad Nacional Autónoma de México ya que permite conocer toda su producción. El haber completado las formas abreviadas de los nombres de las entidades subordinadas le dio consistencia a la base de datos de artículos de investigación científica. En la base CIC se puede recuperar información por diferente afiliación de los autores y por entidades subordinadas como institutos y centros de investigación y direcciones generales. Los catálogos de autoridad representan una buena alternativa para proporcionar uniformidad y consistencia en la recuperación de los principales puntos de acceso de los artículos de investigación científica debido a que con una sola búsqueda recupera las formas variantes del nombre del autor a través del nombre preferido. Sería conveniente que Scopus y Web of Science vincularan los registros de autoridad de autor con los que cuentan con los registros de los artículos, esto les permitiría una mejor recuperación de información. Además, la base CIC se puede actualizar semestralmente o anualmente.
Referencias
Scopus. Scopus [en línea]. [Consulta: 4 septiembre 2015].
Web of Science. Web of Science [en línea]. [Consulta: 4 septiembre 2015].