Emergência de Tato e Precisão da Fala via Instrução por Múltiplos Exemplares em Crianças com Pouco Repertório Verbal1
Emergência de Tato e Precisão da Fala via Instrução por Múltiplos Exemplares em Crianças com Pouco Repertório Verbal1
Acta Comportamentalia: Revista Latina de Análisis de Comportamiento, vol. 32, núm. 3, pp. 423-447, 2024
Universidad de Guadalajara

Esta obra está bajo una Licencia Creative Commons Atribución-NoComercial-CompartirIgual 4.0 Internacional.
Recepción: 19 Febrero 2024
Aprobación: 24 Mayo 2024
Resumo: O papel indutor da Instrução por Múltiplos Exemplares (MEI) sobre a emergência e integração de operantes de ouvinte e falante é de interesse científico e social. Este estudo verificou os efeitos do MEI sobre a emergência de tatos após treino de ouvinte em quatro crianças com pouco repertório verbal. O procedimento foi realizado em fases: Pré-teste - avaliou os operantes de ouvinte, ecoico e tato (três conjuntos de estímulos); Treino de ouvinte e teste de tato demonstrou a independência funcional entre os operantes (conjunto 1); MEI ensinou os operantes de ouvinte, ecoico e tato (conjunto 2); Treino de ouvinte e teste de tato verificou o potencial indutor do MEI sobre a emergência do tato (conjunto 1); Treino de ouvinte e teste de tato verificou os efeitos do MEI com um conjunto novo de estímulos (conjunto 3); Pós-testes e follow-up verificaram manutenção (três conjuntos). O ecoico foi sistematicamente monitorado. Após o MEI obteve-se altas porcentagens de acertos nos três operantes (conjunto 2) e emergência de tatos após o treino de ouvinte (conjunto 3), com variabilidade persistente, mas superior ao nível dos pré-testes. Os componentes do MEI e número de exposições necessárias são variáveis que devem ser investigadas na emergência de tato.
Palavras-chave: acurácia da fala, Instrução por Múltiplos Exemplares, tato.
Abstract: The inductive role of Multiple Exemplar Instruction (MEI) in the emergence and integration of listener and speaker operants is of scientific and social interest. This study verified whether the emergence of tacts after listening training would be induced by MEI in four children who did not emit tacts initially. Three participants with diagnoses of autism spectrum disorder, two boys, and one girl at six to eight years old. One participant was diagnosed with hard of hearing and used a cochlear implant. The participants were evaluated VB-MAPP scored Level 1 in tact, and had different diagnoses. The procedure was carried out in phases. The pre-test assessed the listener, echoic, and tact and selected three sets of stimuli for the next phases. Listener training and tact test demonstrated functional independence between the operants (set 1). The MEI taught the operants of listener, echoic, and tact (set 2). Repeating the listener training and tact test verified the inductive potential of the MEI on the emergence of tact (set 1). Listener training and tact testing verified the effects of MEI with a new set of stimuli (set 3). The three post-tests and three follow-ups evaluated maintenance (three sets). The echoic behavior was systematically monitored during testing. Before MEI listener training was not a condition for the emergence of tact; the percentage of correct responses in tact was very low or null for all participants. After MEI (set 2) there was an increase in the percentage of correct in three operants and tact emergence after listener training for set 1 and set 3 (new set). The variability was persistent but all measures in post-tests and follow-ups were at a level above the major level of baseline. The speech accuracy is better in the post-test than pretest. Except for one participant (Julie) the error type no response or complex errors decreased and correct answers or simple errors increased. The MEI components and number of exposures required are variables that must be investigated in the tact emergency.
Keywords: speech accuracy, Multiple-Example Instruction, tact.
Pessoas com heterogeneidade no funcionamento cognitivo e com repertório compatível com algumas condições diagnósticas podem apresentar repertório verbal limitado na comunicação espontânea e no uso de palavras faladas se comparadas a indivíduos com desenvolvimento típico, demandando uma programação explícita de contingências de ensino para desenvolver repertório verbal funcional (Kedar & Bauminger-Zviely, 2023), como o Transtorno do Espectro Autista - TEA e a Desordem do Espectro da Neuropatia Auditiva – DENA.
O indivíduo com características de repertório compatíveis com o TEA pode apresentar déficits na comunicação, dificuldades na compreensão de gestos, e com contato visual. Conjuntamente, há a manifestação de padrões restritos e repetitivos de comportamento, restrições e fixação de interesses e atividades, uso repetitivo de objetos, e apresentação de comportamentos motores ou vocais estereotipados (APA, 2013). Os comportamentos restritos e repetitivos podem dificultar a ampliação e variabilidade do repertório comportamental, prejudicando a aquisição de habilidades fundamentais e se constituindo em obstáculos para uma boa qualidade de vida, pois se uma resposta não ocorrer não poderá ser selecionada, e se não houver variabilidade não poderá tornar-se mais complexa (Rodriguez & Thompson, 2015). Considerando a necessidade dessa população aprender ou expandir repertório, as condições sob as quais indivíduos com TEA aprendem comportamento verbal funcional demandado em contextos sociais e acadêmicos têm sido alvo de investigações (Greer & Ross, 2008; Gomes & de Souza, 2016; Silva et al., 2020; Souza & Calandrini, 2022).
A DENA caracteriza-se por uma alteração na sincronia neural envolvida no processamento auditivo. As principais consequências dessa dissincronia são a alteração do processamento da estimulação sonora (i.e., detecção, discriminação, reconhecimento e compreensão) prejudicando o reconhecimento de sons da fala em situações com ruído concomitante e incidindo sobre a compreensão e a produção da fala de maneira importante (Costa et al., 2012; Norrix & Velenovsky, 2014). Medidas audiométricas têm demonstrado que as respostas comportamentais auditivas são variáveis em casos de DENA; essa variabilidade ou flutuação nos limiares de audição, característica marcante, pode resultar em dificuldades de compreensão e no desenvolvimento da fala. Uma alternativa de intervenção é pelo implante coclear (IC), um dispositivo biomédico inserido cirurgicamente na cóclea (parte interna do ouvido). O IC capta os sons do ambiente e os converte em estímulos elétricos e estimulam diretamente o nervo auditivo, substituindo de forma parcial as funções das células sensoriais e beneficiando a sincronia neural (Fernandes et al., 2015). Embora o IC restabeleça a detecção de sons do ambiente, a compreensão dos mesmos e a produção da fala com acurácia são repertórios que requerem aprendizagem (Fernandes et al., 2015).
Considerando que o comportamento verbal é estabelecido e mantido via contingências de reforço e que as relações de interdependência entre os comportamentos de ouvinte e de falante requerem planejamento, o protocolo baseado no Multiple Exemplar Instruction (MEI; Greer et al., 2005; Hawkins et al., 2018) é uma estratégia que tem sido utilizada para o estabelecimento do controle compartilhado entre estímulos que controlam comportamentos de ouvir e de falar. Envolve a apresentação de uma sucessão de tarefas em que os indivíduos respondem como ouvinte e como falante, com vários conjuntos de estímulos, até que responda como ouvinte e como falante (nomeação bidirecional) a um conjunto de estímulos novos (Greer & Ross, 2008; Greer & Speckman, 2009; LaFrance & Tarbox, 2019; Sivaraman et al., 2023). Além da nomeação bidirecional, a exposição a protocolos de MEI tem favorecido aprendizagem de relações de interdependência de repertórios verbais em população com pouco ou nenhum repertório verbal funcional, como no caso de crianças com TEA (Fiorile & Greer, 2007; NuzzoloGomez & Greer, 2004; Olaff et al., 2017) e crianças com DENA e IC (Merlin et al., 2019; Pereira et al., 2018). A literatura registra muita flexibilidade para programar o MEI e eleger os operantes envolvidos na sua programação (Mascotti & AlmeidaVerdu, 2020).
A literatura também faz uma distinção entre o comportamento vocal sob controle de objetos ou eventos (tato) daquele que combina os comportamentos de falante e de ouvinte no mesmo indivíduo como a nomeação bidirecional ou bidirectional naming (Horne & Lowe, 1996; Miguel, 2016). A integração entre falante e ouvinte ocorre quando as contingências de reforço requerem da criança topografias distintas tais como a baseada em seleção (i.e., ouvir o que outros dizem e apontar para objetos) ou a topografia vocal para a mesma modalidade de estímulo auditiva (i.e., repetir o que outros dizem), caracterizando uma história de reforço de ouvinte e de ecoico, respectivamente (Horne & Lowe, 1996; Queiroz & Souza, 2021). No quotidiano, uma criança que é ensinada a apontar para um girassol quando um adulto diz “girassol” e que, alternadamente, repete a palavra “girassol” logo após o adulto emiti-la, pode passar a emitir a palavra “girassol” quando olhar novamente em direção à mesma flor ou outras semelhante, sem que a relação nome-objeto tenha sido diretamente reforçada. No laboratório, a simulação dessas contingências de reforço podem induzir a nomeação bidirecional, assim como favorecer a emergência de um operante de falante como o tato, após o treino de ouvinte. Uma taxonomia da nomeação foi proposta por Hawkins et al. (2018) a depender do repertório inicial dos participantes, das contingências de ensino (envolvendo reforçamento direto ou incidental de repostas de falante e/ou ouvinte) e das respostas avaliadas (comportamento de falante e/ou de ouvinte). O alvo desse trabalho foi o subtipo nomeação unidirecional de falante na qual ensina-se diretamente o comportamento e ouvinte e testa-se comportamento de falante (Hawkins et al., 2018).
Fiorile e Greer (2007) verificaram se o MEI seria condição para emergência de nomeação em quatro crianças de dois anos de idade, com TEA e que não tinham repertório de ouvinte e de falante estabelecidos. O MEI envolveu unidades de aprendizagem alternadas nas quais se demandava respostas de emparelhar estímulos visuais condicional ao estímulo visual baseado na similaridade física (“match”), selecionar estímulos auditivos falados pelo experimentador (“point to,” ouvinte baseado em seleção), e tato puro, totalizando 18 unidades de aprendizagem para cada tipo de resposta. Após atingir o critério de 17 acertos em duas sessões consecutivas ou 100% em uma sessão, sondas de tato e de respostas de ouvinte foram conduzidas. Como estímulos foram adotadas palavras dissílabas sem correspondência convencionada a estímulos visuais, emparelhadas com itens não usuais (como grampos e parafusos). A exposição apenas ao treino de tato ou de ecoico-para-tato, conduzida antes do MEI, não foi uma condição suficiente para a emergência do repertório de nomeação e seus componentes de ouvinte e falante. Todavia, após passar pelo MEI, todas as crianças apresentaram respostas não ensinadas dos componentes da nomeação e a capacidade de adquirir este repertório após o treino de tato com um novo conjunto de estímulos. Todos os participantes foram expostos a mais de um conjunto de estímulos e demonstraram emergência do repertório de nomeação. Contudo, a nomeação realmente avaliada por Fiorile e Greer (2007) foi a nomeação unidirecional de ouvinte, na qual se treina o repertório de falante e testa-se o de ouvinte (cf. Hawkins et al., 2018 e Santos & Souza, 2020).
O ecoico é um importante repertório para aquisição de outros operantes verbais por ser uma cúspide e um pré-requisito (Conceição et al.2022). Ouvir e dizer o que ouviu torna possível usar o ecoico como prompt para colocar o comportamento vocal sob controle de outros estímulos discriminativos verbais (i.e., textual, intraverbal), não verbal (i.e., tato) ou motivacionais (i.e., mando) (Guerra et al., 2019). A despeito da importância do operante ecoico (vocal ou subvocal)1para a emergência de repertórios verbais (Olaff & Holth, 2020), são raros os estudos que colocam o ecoico em rotatividade nos protocolos de MEI (Pereira et al., 2018; Mascotti & Almeida-Verdu, 2020; Queiroz & Souza, 2021). Na literatura internacional (cf. Queiroz & Souza, 2021; Olaff & Holth, 2020) foram identificados três estudos que incluíram o ecoico como componente do MEI na investigação da nomeação bidirecional (Hawkins et al., 2009; Greer & Longano, 2010 ao relatar Logano, 2008; Olaff et al., 2017).
Um dos estudos preliminares em nosso laboratório (Merlin et al., 2019) incluiu o ecoico no protocolo de MEI. A resposta demandada aos estímulos eram tatos com autoclíticos (e.g., boneca rosa, carro verde), em três crianças com 6 anos, com DENA e IC que não apresentavam esse repertório na linha de base. O MEI consistiu no ensino da resposta de ouvinte baseado em seleção, da resposta ecoico e do tato com autoclítico para um conjunto com três estímulos. Inicialmente o MEI foi linear e demandou os três tipos de resposta para um estímulo do conjunto (e.g., ouvinte, ecoico e tato para “lobo marrom”, então para “boneca rosa” e, por fim, para “casa azul”). Atingido o critério de 80% ou mais de acertos, o MEI randomizava os tipos de respostas e os estímulos (ouvinte para “lobo marrom”, seguido de ecoico para “boneca rosa”, seguido de tato para “casa azul” e assim sucessivamente). Pré e pós testes avaliaram os três operantes para a recombinação dos estímulos (i.e., lobo azul, boneca azul, casa rosa, etc). A porcentagem de acertos foi maior nos pós-testes se comparada com os pré-testes. Foi observada uma variabilidade substancial intra e entre os participantes, além de uma falta de controle adequado para a estabilidade da linha de base. O tato emergente após treino de ouvinte também não foi avaliado.
Para verificar os efeitos do MEI sobre a variabilidade nas porcentagens de acertos é necessário tomar várias medidas dos comportamentos alvo, antes e depois do ensino. Tanto em casos de TEA quanto em casos de DENA, a variabilidade das respostas e a baixa acurácia da fala são condições presentes. A medida de estabilidade (em contraponto com a variabilidade) pode ser compreendida como um padrão que mostra pouca oscilação ao longo de um período de tempo (Kazdin, 2011; Byers et al., 2012). Já a acurácia da fala é a precisão com a qual um aprendiz produz os sons da fala quando comparado com um adulto típico (Yoder et al., 2005); é calculada pela transcrição da fala do participante e comparação desta com a transcrição da fala de um adulto típico; a partir da correspondência ponto a ponto calcula-se a porcentagem (Barreto & Ortiz, 2008). Então, obter mais de uma medida de linha de base, de pós-testes e follow-up é importante, pois é uma forma de avaliar a oscilação dos dados, constituindo-se em uma referência para a comparação do comportamento do participante após intervenção (Kazdin, 2011; Byers et al., 2012).
No presente estudo o alvo foi a verificação da emergência do comportamento de tato após o ensino do comportamento de ouvinte, portanto avaliou a nomeação unidirecional de falante (cf. taxionomia de Hawkins et al., 2018). Santos e Souza (2020) identificaram em uma revisão de literatura apenas quatro estudos que avaliaram a nomeação unidirecional de falante. Três estudos tiveram como participantes crianças típicas (Bandini et al., 2012; Horne et al., 2004; Horne et al., 2006) e um estudo crianças com TEA (Kobari-Wright & Miguel, 2014). O delineamento envolveu múltiplas sondagens apenas no estudo com TEA e o procedimento adotado foi o ensino de ouvinte. Não foi relatado o uso do MEI e nem participantes com DENA nos os estudos identificados.
O objetivo deste estudo foi verificar os efeitos do MEI sobre a emergência de tato após treino de ouvinte (nomeação unidirecional de falante) em crianças com pouco repertório verbal. Este estudo também verificou se há redução da variabilidade em tato considerando a acurácia da fala nos pós-testes e na manutenção dos resultados no follow-up. Nos estudos anteriores que adotaram o MEI envolvendo ecoico a variabilidade da acurácia da fala não foi controlada (Hawkins et al., 2009; Greer & Longano, 2010 ao relatar Logano, 2008; Olaff et al., 2017). Elucidar as condições sob as quais o tato pode emergir após o treino de ouvinte em crianças que não emitem tato (i.e., em características diagnósticas como o TEA e a DENA) e conhecer os efeitos do MEI que inclua o ensino de ecoico sobre a fala mais acurada, monitorando a sua variabilidade, tem relevância científica e social para o desenvolvimento de programas de reabilitação.
Método
Participantes
Participaram quatro crianças com idades entre cinco e oito anos, três com diagnóstico de TEA (Julie: 8 anos e 6 meses; David: 5 anos e 2 meses; e Felix: 6 anos e 3 meses) e uma com diagnóstico de DENA (Alex: 7 anos e 4 meses), todas com pouco repertório verbal funcional de acordo com avaliação realizada pelo Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP), não ultrapassando o Nível 1 para tato, ecoico e ouvinte; somente Alex obteve Nível 2 em ouvinte. Todos matriculados em escola regular e com atendimento em serviço especializado. Em acréscimo, os dados do prontuário hospitalar onde ALEX realizava o acompanhamento do implante coclear reportou pontuação 2 na categoria de linguagem (MUSS) e 1 na de audição (IT-MAIS) a partir de protocolos fonoaudiológicos. Todos os procedimentos éticos foram adotados (CAAE: 68500517.0.0000.5398).
Instrumentos de Avaliação
Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP). O VB-MAPP (Sundberg, 2008) permite a mensuração de repertórios verbais e outros relacionados à linguagem e a elaboração de um plano de ensino individualizado. O VB-MAPP é dividido em três níveis: Nível 1 (0 até 18 meses) com escore máximo de 45; Nível 2 (18 até 30 meses) com escore máximo de 105; e Nível 3 (30 até 48 meses) com escore máximo de 170. No presente estudo, foi avaliado somente o ecoico, tato, e ouvinte, sendo que o ecoico possui o escore máximo de 10 e tato e ouvinte o escore máximo de 15.
Análise de Prontuário.
Do prontuário de Alex foram extraídas as categorias de linguagem e audição obtidas por instrumentos aplicados anteriormente ao estudo por fonoaudióloga da instituição onde Alex recebia acompanhamento pós cirurgia de IC. A categoria de audição possui pontuação de 1 (menor grau de reconhecimento auditivo) a 6 (maior grau), é atribuída por meio da aplicação das escalas InfantToddler Meaningful Auditory Integration Scale(IT-MAIS) (Zimmerman-Phillips et al., 1997), e Speech Perception Tests (i.e., Glendonald Auditory Scale Procedure – GASP, Bevilacqua & Tech, 1996; Lista de Palavras, Delgado & Bevilacqua, 1999) e objetiva avaliar a percepção auditiva, como respostas auditivas espontâneas em situações cotidianas. A categoria de linguagem tem pontuação de 1 (menor nível de produção de fala) a 5 (maior nível), é obtida por meio Meaningful Use of Speech Scale(MUSS), conduzido por entrevista com os pais e visa avaliar o uso da linguagem oral pela criança (Pinto et al., 2008). As escalas não foram aplicadas aos demais participantes porque foram recrutados de outra instituição e porque não usavam o dispositivo do IC.
Ambiente
As sessões de Julie, David, e Felix ocorreram na clínica escola da universidade sede da pesquisa. Na sala havia um espelho unidirecional, uma mesa redonda com cadeiras para a pesquisadora e participante, materiais para condução da coleta, armários e computadores. Para Felix e Alex, os atendimentos também ocorreram nas residências dos participantes. As sessões eram feitas na sala de estar da residência. Em todos os casos foram mantidos a organização do ambiente de forma a reduzir estímulos distratores. As sessões ocorriam duas (David), três (Felix e Alex) a cinco (July) vezes por semana, com duração de 20 a 30 minutos, cada sessão.
Variáveis Independente e Dependente
A variável independente foi o protocolo de MEI constituído pelo treino dos operantes de ouvinte baseado em seleção (“point to”), tato impuro (“what is this?”), e ecoico (“repeat it”). A variável dependente consistiu na emergência de repertório de tato após treino de ouvinte com um conjunto novo de estímulos (conjunto 3, fase e, descrita a seguir) ou, de acordo com a taxonomia mais recente, nomeação unidirecional de falante (c.f., Hawkins et al., 2018). Também foi sondada a emissão de ecoico. Na análise das vocalizações de tato e de ecoico foi considerada a precisão da fala, definida pela porcentagem de correspondência ponto a ponto entre o estímulo auditivo apresentado em tarefas de ouvinte e a resposta emitida (Yoder et al., 2005) e a variabilidade em sucessivas medidas em comparação à linha de base.
Materiais e Estímulos
Foram utilizados estímulos para consequenciar diferencialmente as respostas corretas. Os estímulos foram selecionados por meio de avaliações de preferência realizadas no início de cada sessão (Multiple Stimulus Without Replacement, MSWO) (Carr et al., 2000). Os estímulos adotados na avaliação de preferência foram indicados previamente pelos pais a partir de uma entrevista. Como resultado da avaliação, para Julie e David foram utilizados comestíveis (chocolate, bolacha) e brinquedos (pelúcias, bonecas, e pedaços de tecidos) e, para Felix e Alex, comestíveis (chocolates e salgadinhos), brinquedos (carros, bonecos e bola) e vídeos no celular, além de elogios e aprovação (como “Muito bem!” “Legal!” “Excelente!”) para todos os participantes.
Os estímulos utilizados para sondagens e ensino foram escolhidos a partir de uma avaliação realizada com base em uma lista prévia que continha 39 estímulos. Eram palavras dissílabas, sem dificuldade de articulação de acordo com avaliação fonoaudiológica, extraídas do estudo de Guerra (2020). Após uma avaliação inicial foram escolhidos para o estudo, os estímulos que os participantes não souberam responder ou responderam incorretamente nas tentativas de tato. Os estímulos foram organizados em três conjuntos de três estímulos cada (estímulos auditivos e visuais), conforme apresentado na Figura 1, exceto para David e Alex, que utilizaram quatro conjuntos. As tentativas foram organizadas por meio do software PowerPoint® da Microsoft Office® e apresentadas em formato PDF em um notebook, exceto para Alex, em que foi utilizado um tablet. Entre todas as tentativas, de sondagem e de ensino, havia a apresentação de uma tela cinza para demarcar o término de uma tentativa e início da seguinte. Durante os procedimentos de ensino e sondagem, foi utilizado um gravador e um diário para anotação dos dados.

Figura 1
Estímulos Discriminativos
Delineamento
Após a seleção de três conjuntos de estímulos, a sequência geral do procedimento envolveu a interposição de sondas (e.g., Nuzzolo-Gomes & Greer, 2004). Iniciou com a realização de três sondas repetidas que avaliou a estabilidade da linha de base; uma sonda foi realizada antes de cada passo do treino e antes da introdução da variável independente; ao final do último treino, três sondas foram repetidas como pós-teste e, depois de um mês, como follow-up. Desta forma avaliou-se se a nomeação unidirecional de falante (tato emergente) ocorreria após o treino de ouvinte ou se seria induzido após o MEI.
Procedimento
A coleta de dados consistiu na aplicação, pela primeira autora, de procedimentos de avaliação e ensino, realizados individualmente e divididos em fases que intercalavam avaliações de tato com os conjuntos de estímulos, ensino pelo MEI e treino de ouvinte. As sessões de ensino consistiram na apresentação das instruções, nas respostas apresentadas pelo participante, e pelas consequências diferenciais para acerto e erro fornecidas pela pesquisadora. Nas sessões de testes não havia consequências programadas para acerto ou erro e respostas inadequadas ou ausência de respostas eram ignoradas e depois de 5 segundos iniciava-se nova tentativa.
Procedimento de Análise dos Dados
Nas tarefas de ouvinte os dados foram analisados quantitativamente pelo número de blocos de ensino necessários em cada etapa até a obtenção do critério de aprendizagem e pela porcentagem de respostas emitidas corretamente pelo participante. Nas tarefas de tato e ecoico, os registros de fala gravados durante as sessões foram transcritos e foi realizada uma avaliação da acurácia por análise fonêmica (Barreto & Ortiz, 2008), com análise da correspondência ponto a ponto que a produção oral compartilhava com os estímulos auditivos adotados e obteve-se a porcentagem de acertos. Os dados de fala foram analisados de acordo com categorias de erros (Souza et al., 2013) cuja finalidade foi identificar os erros cometidos pelos participantes bem como as mudanças na qualidade das respostas nas tarefas de produção oral. Para as categorias de omissão, troca, distorção, acréscimo e inversão foram classificadas como erros simples. Para as categorias ausência de resposta, palavra sem sentido e outra palavra o participante recebeu a pontuação zero e foram classificadas como erros complexos.
Tipos de Tentativas
Uma tentativa de ouvinte consistia na exposição do participante a três estímulos, de forma sistemática e com randomização da posição, com solicitação para que a criança apontasse o item específico (“Aponte __”); a resposta deveria ser apontar para o item correspondente ao ditado. Por exemplo, a criança era exposta a uma tela com as figuras mala, pote e dino; diante da instrução “Aponte mala'', a resposta correta seria apontar a figura correspondente ao estímulo verbal vocal “mala.” Uma tentativa de ecoicoconsistia na emissão pela pesquisadora de uma resposta verbal vocal (“Diga __”) a qual a criança deveria vocalizar, com correspondência ponto a ponto, em até três segundos. Por exemplo, se a instrução da pesquisadora fosse “Diga bola,” a resposta correta seria a repetição do estímulo verbal “bola”. Na tentativa de tato, a pesquisadora apresentava os estímulos individualmente e solicitava que a criança os nomeasse após a instrução (“O que é isso?”) em até três segundos. Por exemplo, se a criança era exposta a uma tela com a figura de uma nave e era dada a instrução “O que é isso?” a resposta correta seria a criança nomear a figura, “nave.” Consequências diferenciais para acertos e erros eram apresentadas em tentativas de ensino e não eram apresentadas em tentativas de teste.
Fases
Avaliação Inicial
Foram conduzidas tentativas de ecoico, de ouvinte baseado em seleção e de tato para 39 estímulos iniciais. Uma tentativa iniciava com a apresentação de um estímulo auditivo pela experimentadora e era solicitado que o participante repetisse (“Diga ____”). Após a resposta do participante eram apresentados dois estímulos visuais, um à esquerda e um à direita, na tela do computador e era solicitado que o participante apontasse para o estímulo ecoado previamente (“Aponte ____”). Após apontar para um dos estímulos visuais, era solicitado que o participante nomeasse o outro (“O que é isso?’). Não foram apresentadas consequências para acertos ou erros nessa etapa. Foram selecionados estímulos para os quais os participantes apresentaram pouca acurácia na resposta de tato.
Após a avaliação inicial para seleção dos estímulos experimentais, foi iniciada a sequência de ensino e testes da fase experimental:(a) três sucessivos pré-testes dos repertórios de ouvinte e de falante (tato e ecoico) com os três conjuntos de estímulos; (b) treino de ouvinte baseado em seleção e teste de tato e de ecoico (conjunto 1); (c) MEI (conjunto 2); (d) retomada do treino de ouvinte baseado em seleção e teste de tato e de ecoico (conjunto 1); (e) treino de ouvinte baseado em seleção e teste de tato e de ecoico (conjunto 3); (f) três pós-testes (três conjuntos); (g) follow-up.
Para Alex, após o término do follow-up com os conjuntos 1, 2, e 3, foi feita uma replicação intra participante com MEI com estímulos do conjunto três seguido de ensino de ouvinte e testes de falante com estímulos do conjunto 4, incluindo pré e pós-testes com este conjunto. Para David, houve substituição do conjunto de estímulos no decorrer do estudo.
Pré-testes: Ouvinte, Ecoico e Tato (fase a)
Três pré-testes avaliaram o repertório de entrada dos participantes e cada sessão foi realizada em um dia diferente. Não havia consequência programada para acerto ou erro; ausência de respostas era considerado erro e respostas inadequadas (i.e., chamar pela pesquisadora, iniciar uma conversa, tocar em outra parte do computador que não fosse um dos estímulos apresentados) eram ignoradas. Eram compostos de três blocos, cada qual com nove tentativas, avaliando os repertórios de ouvinte, ecoico e tato, sendo um bloco para cada um dos três conjuntos de estímulos. Os operantes avaliados foram apresentados de forma rotativa dentro de cada bloco e, em cada medida de pré-teste, os blocos foram apresentados em uma ordem diferente. A mesma constituição de blocos foi apresentada nos pós-testes e follow-up, estes realizados entre 15 e 20 dias após o encerramento do experimento.
Treino de Ouvinte Baseado em Seleção e Testes de Ecoico e Tato (Conjunto 1) (fase b)
O ensino do repertório de ouvinte ocorreu pelo procedimento de matching-tosample em que um estímulo auditivo era apresentado pela experimentadora e três figuras eram apresentadas como estímulos de comparação; era constituído por um bloco de nove tentativas sendo três com cada um dos três estímulos do conjunto 1. Os itens de preferência selecionados previamente foram apresentados após respostas corretas. Respostas incorretas ou ausência de resposta foram seguidas de ajuda física (total, parcial ou leve) ou de dica gestual (apontar o item correto), conforme a necessidade do participante. Por exemplo, se após uma dica física leve, como encostar no braço do participante, o movimento de mover o cursor do mouse fosse iniciado, então era deixado que concluísse a seleção; se o movimento não fosse iniciado, então imprimia-se mais intensidade à dica física que poderia culminar com ajuda total. Após a tentativa de correção, a criança era exposta a mesma tentativa, sem ajuda. Se um erro ou ausência de resposta ocorresse novamente estes eram seguidos pela retirada dos estímulos, um intervalo de cinco segundos e a apresentação de uma nova tentativa. O treino de ouvinte era repetido até a obtenção de, no mínimo, 88% de respostas corretas independentes em dois blocos consecutivos de nove tentativas cada (era permitido até uma resposta incorreta) ou após duas sessões consecutivas sem mudanças no número de respostas corretas. A sondagem de ecoico e de tato após o treino de ouvinte com o conjunto 1 foi idêntica ao pré-teste, exceto que nesta avaliação um bloco era constituído por três tentativas de cada um dos três estímulos, sendo nove tentativas de ecoico e nove de tato, totalizando 18 tentativas. As sondas foram realizadas na mesma sessão, após o término do treino de ouvinte. A mesma constituição dos blocos e critérios foi semelhante na repetição do treino de ouvinte e teste de falante com estímulos do conjunto 1 e com estímulos do conjunto 3, ambos após o MEI.
MEI de Ouvinte, Ecoico e Tato (Conjunto 2) (fase c)
O protocolo de MEI estruturou, em um mesmo bloco, tentativas de ouvinte (“Aponte ___”), de ecoico (“Diga ____”), e de tato (“O que é isso?”). Respostas incorretas eram seguidas por procedimentos de correção como dica ecoica com pista orofacial. Era composto por 27 tentativas: cada estímulo foi apresentado três vezes para cada operante. Em um primeiro momento, os operantes para um mesmo estímulo eram apresentados de forma linear/sequnecial (e.g., Nuzzolo-Gomes & Greer, 2004); apresentava-se uma tentativa de seleção, seguida de uma de ecoico, e uma tentativa de tato para o mesmo estímulo “mola” e assim por diante com os outros dois estímulos que constituíram um bloco de MEI. Atingido o critério de aprendizagem, os participantes eram expostos ao ensino randomizado, no qual havia total randomização entre os operantes e estímulos (e.g., Speckman et al., 2012). Tanto no MEI linear quanto randomizado, o critério era emitir no mínimo 90% de respostas corretas independentes em dois blocos consecutivos ou seria encerrado após dois blocos consecutivos sem mudança importante na porcentagem de acertos.
Treino de Ouvinte Baseado em Seleção e Testes de Ecoico e Tato (Conjunto 1) (fase d)
Após a obtenção do critério de acertos no MEI com estímulos do conjunto 2 os participantes eram expostos novamente ao treino de ouvinte e teste de falante com estímulos do conjunto 1. Após a revisão de ensino e testes com o conjunto 1 de estímulos os participantes eram expostos ao ensino de ouvinte e testes de ecoico e tato com estímulos do conjunto 3, um conjunto novo de estímulos (fase e) e que seguia os mesmos critérios das fases b e d. Após os testes de ecoico e tato com estímulos do conjunto 3, os participantes eram expostos aos pós-testes (fase f) e follow-up (fase g), tendo passado um mês da realização dos pós-testes e seguia os mesmos critérios dos pré-testes.
Concordância Entre Observadores
As respostas dos participantes nas tarefas de vocalização em ecoico e tato foram analisadas por uma observadora, do grupo de pesquisa do mesmo laboratório, a fim de verificar a concordância. Foi considerado concordância transcrições com correspondência pontual de uma mesma vocalização. Transcrições com correspondência diferente de 100% eram consideradas não concordância. Foi utilizada a fórmula: números de concordâncias/números de concordâncias + números de discordâncias X 100 (Kazdin, 2011). Foram analisados 40% dos dados das sondagens e 40% das sessões de ensino com concordância de 86,44% a 98,78%.
Percentage of Nonoverlapping Data
Foi calculado o Percentage of Nonoverlapping Data– PND (Scruggs & Mastropieri, 2001), para verificar a magnitude do efeito de intervenção (MEI) sobre medidas de tato (nomeação unidirecional de falante) com os conjuntos 1 e 3. O PND é determinado pela porcentagem de número de pontos que excedem o maior valor de linha de base. O número de pontos nos pós-testes que excede o maior valor de linha de base é dividido pelo número total de testes realizados pós-testes. Foi considerado como linha de base todos os pré-testes ou os testes realizados antes do MEI. Para calcular o PND foram adotados os valores que excederam o maior ponto da linha de base e que cuja medida foi tomada após a exposição ao MEI, inclusive após o treino de ouvinte com o conjunto 3. Essa medida foi calculada apenas para tato emergente (nomeação unidirecional de falante). Valores de p (probabilidade de significância) foi calculada pelo site http://ktarlow.com/stats/pnd/ (Tarlow & Penland, 2016). Escores acima de 90% representam um tratamento muito efetivo; entre 70% a 90% representam um tratamento efetivo; entre 50% a 70% referem-se a um tratamento questionável; e escores menores de 50% referem-se a um tratamento não efetivo.
Resultados
Durante o pré-teste, os quatro participantes apresentaram variabilidade nas porcentagens de respostas corretas para os operantes de ouvinte e ecoico durante as três medidas de linha de base com os três conjuntos de estímulos e entre as sucessivas sondas com acertos, predominantemente, inferiores a 50%. O tato foi o operante com menor porcentagem de acertos para todos os participantes. Julie, Felix, e Alex não apresentaram acertos para tato nos sucessivos pré-testes; David não apresentou resultados superior a 20% de acertos. Apenas o treino de ouvinte com estímulos do conjunto 1 não foi suficiente para o aumento de acertos em tato de figuras com estímulos do mesmo conjunto, permanecendo nos níveis de linha de base para todos os participantes.
Os participantes foram expostos ao MEI com estímulos do conjunto 2 (Tabela 1). No início do MEI os operantes de falante e de ouvinte tinham porcentagens de acertos muito diferentes como ouvinte superiores a 80% de acertos e ecoico e tato com porcentagens muito baixas, inferiores a 40% de acertos. Como resultado do MEI todos os participantes aumentaram a porcentagem de acertos nos três operantes e a diferença entre as porcentagens de acertos diminuiu. As medidas de tato foram superiores a 60% de acertos em um máximo de 10 sessões considerando o MEI linear e randômico. Para David foi necessário adotar um conjunto 4 de estímulos, pois não demonstrou mudança nas porcentagens de acertos com estímulos do conjunto 2.
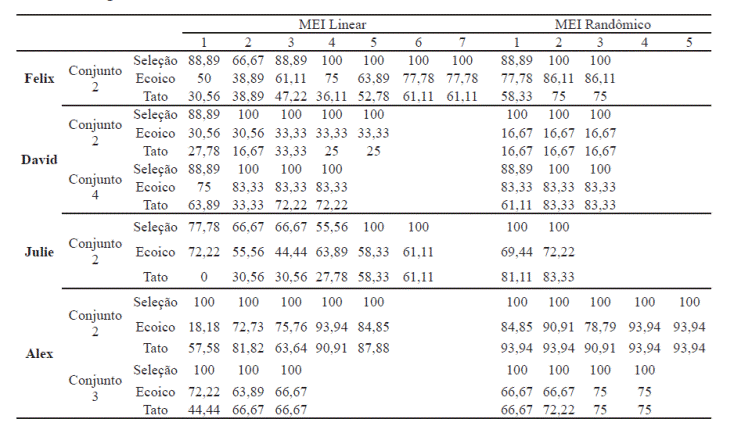
Tabela 1
Número de Exposições aos Blocos de Ensino no MEI (Linear e Randômico) e Porcentagens de Acertos Obtidas
O aumento da porcentagem de acertos em tato de figuras ocorreu apenas após ensino por MEI com estímulos do conjunto 2 (Figura 2, à esquerda). Nas sondas de tato e ecoico com estímulos do conjunto 1 e que sucederam ao MEI, as porcentagens de acertos foram superiores às da linha de base e em ecoico os resultados foram superiores a tato (dados não ilustrados).
Após o MEI com estímulos do conjunto 2, o ensino de ouvinte com estímulos do conjunto 3 (conjunto novo) foi condição para o aumento na porcentagem de acertos em tato. A porcentagem de respostas corretas nas sucessivas sondas com estímulos do conjunto 3 está na Figura 2, à esquerda. De acordo com a figura, as porcentagens de acertos foram superiores às da linha de base com Félix (20% de acertos, David (30% de acertos) e Alex (40% de acertos) em tato. No caso de Alex, o ensino e teste também foram conduzidos com mais um conjunto novo de estímulos, o conjunto 4, e o resultado superior à linha de base em tato foi repetido.
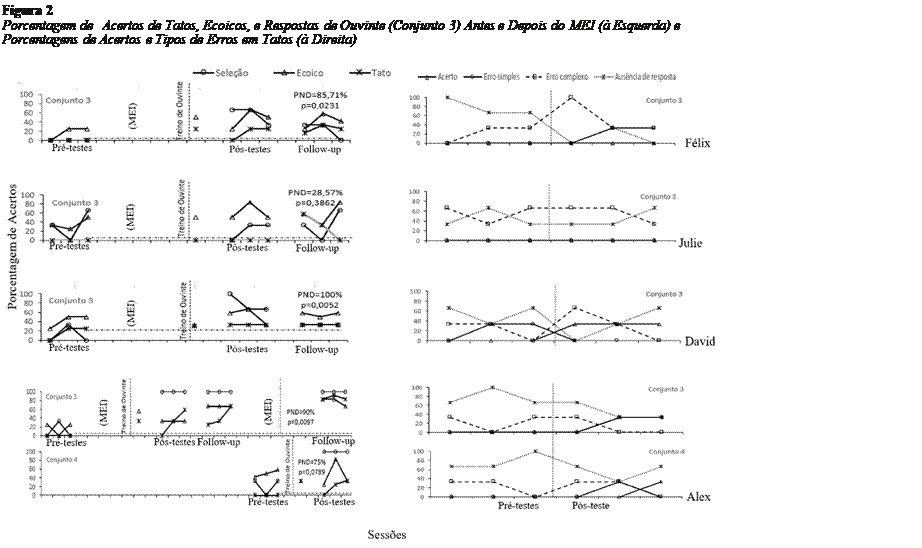
Figura 2
Nas medidas de pós-testes e follow-ups foi demonstrado manutenção dos resultados. A única exceção foi para Julie que teve oscilação nas porcentagens de acertos para todos os operantes e os resultados não se mantiveram nos follow-ups e, em tato, chegaram a zero. Embora também seja observada variabilidade na porcentagem de acertos nos pós-testes, essa se apresenta em níveis superiores aos do pré-testes para os demais participantes.
A porcentagem de acertos em tentativas de comportamento de falante (tato e ecoico) no presente estudo foram computadas com base na acurácia da fala. Na Figura 2, à direita, são apresentadas as porcentagens de acertos e os tipos de erros (simples, erros complexos e ausência de respostas) dos participantes ao longo das sondagens em tato com estímulos do conjunto 3. Ao se considerar a precisão da fala em tato (triângulo branco, na figura), os participantes Julie, Felix, e Alex não emitiram nenhum tato preciso nos sucessivos pré-testes. Somente David emitiu porcentagens inferiores a 40% de acertos em tatos na segunda e terceira avaliações. A porcentagem de erros simples também é nula (círculos brancos) para todos os participantes. Os erros complexos (quadrados brancos) ou ausência de respostas (asteriscos), embora ocorressem com bastante variabilidade, os níveis eram frequentemente superiores a 50% chegando a 100% em muitos casos, principalmente se considerar sucessivas testagens nos pré-testes. Após a exposição ao protocolo MEI, todos os participantes aumentaram a porcentagem de tatos precisos e a porcentagem de erros simples começou a se elevar, ambos marcados com linhas contínuas. Em contraste, a porcentagem de não resposta e de erros complexos, embora ocorressem com muita variabilidade, passam a ocorrem em níveis inferiores aos da linha de base, ambos marcados com linhas tracejadas.
Os resultados de PND em tato estão exibidos na Figura 2, à esquerda (linha tracejada horizontal). As medidas de PND foram entre 75% e 100% para David, Felix e Alex, com valores de p < 0,05 (exceto para Alex em tato com o conjunto 4, p=0,0789).
Discussão
O presente estudo demonstrou o efeito do MEI sobre a emergência de tato após o treino de ouvinte em quatro crianças que não emitiam tatos. Os resultados apresentaram uma tendência semelhante independente do diagnóstico e da variabilidade de desempenhos intra e entre participantes. Considerando a emergência do tato após treino de ouvinte, constitui-se em uma replicação no caso das três crianças com TEA e uma extensão para a criança com DENA e IC, especificamente, da indução da nomeação unidirecional de falante após o MEI se considerar que foram emitidas respostas vocais diferenciadas para os estímulos discriminativos do conjunto 3. O protocolo de MEI adotado neste estudo incluiu o ensino de ecoico que também foi monitorado durante todas as fases. Nos pós-testes, a porcentagem de acertos em ecoico foi superior à de tato para todos os participantes. Embora as porcentagens em tato emergente nos pós-testes tenham sido superiores às da linha de base, foram inferiores a 50% de acertos. Permanece o questionamento sobre a efetividade da exposição ao ensino com apenas um conjunto de estímulos por meio do MEI e a inclusão do ecoico na estrutura de ensino. O presente estudo contribui também com a tomada de medidas de manutenção, tanto em três medidas de pós-testes como em medidas de follow-ups, estas últimas não encontradas na literatura (Mascotti & Almeida-Verdu, 2020).
Este estudo se diferencia do anterior realizado com crianças com DENA em nosso laboratório (i.e., Merlin et al., 2019) porque avaliou a emergência de tato antes do MEI e verificou que o ensino de ouvinte foi condição para o aumento na porcentagem de acertos em tato emergente (i.e., nomeação unidirecional de falante) somente após a exposição dos participantes ao protocolo do MEI (cf. Fiorile & Greer, 2007; Nuzzolo-Gomez & Greer, 2004). No caso de Alex (DENA), a exposição ao MEI foi realizada com dois conjuntos distintos de estímulos até obter a emergência do tato. No caso da participante Julie (TEA), a exposição ao MEI apenas com um conjunto de estímulos não foi suficiente para a emergência de tato com um conjunto novo (conjunto 3) após o treino somente de ouvinte. Este estudo se assemelha a outros da literatura que registram que alguns participantes, especialmente com diagnóstico de TEA, podem requerer a exposição ao MEI com dois, três ou mais conjuntos de estímulos até observar a integração de operantes e, então, a emergência de repertórios não diretamente ensinados (Fiorile & Greer, 2007; Greer & Yuan, 2008; Santos & Souza, 2016). David necessitou de duas exposições ao MEI até demonstrar a integração de operantes verbais (maior que 70% de acertos nos três operantes). Futuros estudos podem realizar a intervenção com a exposição de mais conjuntos de estímulos ao MEI para averiguar quantas exposições a esse procedimento auxiliaria na emergência do repertório de falante após o treino somente de ouvinte com DENA e com TEA e quais os repertórios pré-requisito necessários.
As porcentagens de acertos em comportamento de falante (tato e ecoico) foram contabilizadas de acordo com uma análise fonêmica e, ainda que as porcentagens de tato após o MEI tenham sido superiores às da linha de base, sua emissão não foi precisa sendo observada pouca diferença entre as porcentagens de acertos obtidas nos pré e pós-testes, sobretudo em tato. A análise fonêmica da topografia vocal e a análise dos tipos de erros podem explicar a diferença reduzida, pois nos pré-testes, à exceção de David, não havia emissão de tatos (sem respostas) ou a porcentagem de fonemas emitidos corretamente era muito baixa ou zero (erros complexos) (cf. lado direito da Figura 2). Nos pós-teste, embora as porcentagens de acurácia da fala fossem suficientes para se configurar as vocalizações em operantes discriminados, ainda não eram totalmente precisas. Se em uma mesma palavra ou forma de comportamento verbal (i.e., “boca) os componentes menores podem ser aprendidos separadamente (i.e., “lobo” e “casa”), aprender o comportamento de ouvinte pode não resultar no tato sem instrução direta (Delgado & Greer, 2009; Greer & Yuan, 2008). Sob essa análise, a exposição apenas do treino de ouvinte melhorou somente o repertório de ecoico, ambos controlados pelo estímulo auditivo, mas não melhorou o repertório de tato, controlado pelo estímulo visual. E, ainda que o tato tenha sido refinado durante o MEI, não foi obtida a precisão.
A superexposição ao estímulo auditivo e a sobreposição destes em tarefas de seleção e de ecoico (em ambos operantes o controle se dá pelo estímulo auditivo) podem explicar o aumento na porcentagem de acertos em ecoico. No entanto, o ensino de ecoico não garantiu a precisão em tato. Em tarefas de tato, a vocalização deve ser controlada pela relação entre a figura e a palavra ditada, porém nas contingências de tato a palavra ditada não está mais presente. Porém a mudança na precisão da topografia de tato foi demonstrada; de não respostas e erros complexos (linhas tracejadas na Figura 2, à direita) para erros simples e respostas corretas (linhas contínuas, Figura 2, à direita). Condições que levam à precisão necessitam, portanto, ser mais bem exploradas. A pesquisa nesse caso poderia examinar a possibilidade de cadeias mais complexas entre os operantes envolvidos tais como 1) iniciar com a apresentação de uma tentativa de ecoico com o estímulo “a”, seguida de 2) uma tarefa de seleção com o mesmo estímulo e dois estímulos de escolha (S+ e S-); após a seleção do S+, 3) o S- seria removido e, então, esta se configuraria em uma contingência de tato a partir do prompt de uma dica (prompt) intraverbal “O que (quem) é isso?”. Essas contingências de ensino, presentes no MEI linear/sequencial do presente estudo, podem ser exploradas se, de forma gradual e encadeada (McIlvane & Stoddard, 1981) a fala passaria a ser controlada pela figura a partir de estruturas como de “ouvinte a ecoico” e “de ecoico a tato”, uma vez que a emissão de ecoicos durante o treino de ouvinte pode criar as contingências necessárias para o estabelecimento do tato (Horne & Lowe, 1996; Miguel, 2016).
A variabilidade de desempenho observada nos pré-testes poderia ser entendida como possível erro de mensuração, o que comprometeria a fidedignidade dos dados coletados e qualidade da linha de base (Kazdin, 2011; Byers et al., 2012). De acordo com Byers et al. (2012), além da tendência e da mudança de nível, a variabilidade é uma medida que deve ser observada e analisada em um delineamento de medidas repetidas. Diferentemente do estudo anterior de Merlin et al., (2019) com crianças com DENA a variabilidade foi colocada sob análise com as repetidas medidas de pré- e pós-testes. Embora a variabilidade ainda fosse percebida nos pós-testes para todos os participantes, ocorreu com menor magnitude. Embora a porcentagem de acertos não tenha atingido a precisão, os níveis foram superiores aos obtidos na linha de base para todos os participantes. Uma análise compreensiva dos dados deve incluir não somente a observação de uma mudança de nível da performance, mas também os efeitos sobre a tendência e a variabilidade dos comportamentos analisados (Byers et al., 2012) e a performance geral tendeu a melhorar (Figura 2, à direita), aparentemente, pela intervenção. Então, esse aumento na variabilidade não sugere resultados negativos, mas a possibilidade de melhora se o treino continuasse.
Outro aspecto que merece melhor investigação são os operantes que compuseram o MEI. A literatura revela que o pareamento de identidade, o pareamento auditivovisual, e tato são mais frequentemente adotados nos protocolos de MEI (Fiorile & Greer, 2007; Greer, et al., 2005; Gilic & Greer, 2011; Pereira et al., 2018; Santos & Souza, 2016) e o ecoico incluindo protocolos de MEI é menos recorrente (cf. Queiroz & Souza, 2021). Todavia, ainda que o presente estudo tenha adotado pareamento auditivo-visual, ecoico, e tato, o que representa mais oportunidades de emissão vocal (seja controlada pelo estímulo auditivo como no ecoico, ou controlada pela figura como no caso do tato), essa condição não foi suficiente para a emergência do tato, sendo condição, apenas para a emergência parcial do ecoico.
A variabilidade nos resultados de tato com estímulos novos (conj. 3) após o MEI que incluiu ecoico também foi observada em outro estudo (i.e., Olaff et al., 2017) com participantes com TEA, assim como três participantes do presente estudo. No estudo de Olaff et al. (2017) a porcentagem de acertos aumentou após o MEI com estímulos do mesmo conjunto.
A estrutura de ensino de MEI requer análise, pois quando envolve pareamento por identidade, pareamento auditivo-visual, e tato, a resposta do participante é controlada pela figura nos três operantes (seleção da figura controlada pelo estímulo visual no pareamento por identidade, seleção da figura controlada pelo estímulo auditivo no pareamento auditivo-visual, e somente pela figura, e cuja topografia de resposta é vocal, no tato). Se a quantidade de operantes controlados pela figura, seja por seleção ou por vocalização, é uma condição relevante para a emergência do tato, essa variável deve ser controlada em futuros estudos e um delineamento de contrabalanceamento de condições ou de tratamento alternado (Byers et al., 2012) e pode auxiliar a determinar a melhor condição. Como exemplo, pode ser planejado em uma condição 1, o MEI com operantes que requerem controle pela figura (i.e., pareamento por identidade e tato) com um conjunto de estímulos. Contrabalanceada a esta, uma condição 2 pode envolver o MEI com operantes controlados pela figura em uma densidade menor de tentativas e adicionar operantes com controle pelo auditivo (i.e., ecoico e tarefas de pareamento auditivo-visual), tal como no presente experimento.
O MEI no presente estudo teve potencial indutor da nomeação unidirecional de falante. Em outras palavras, embora o tato tenha sido emitido com porcentagens de acertos superiores às da linha de base, o potencial clínico desta condição no ensino (Grow & Kodak, 2010) e expansão de vocabulário com acurácia da fala em pessoas com pouco repertório verbal funcional com diferentes diagnósticos deve ser explorado em futuros estudos.
Referências
American Psychiatric Association (2013, 5ª ed.). Diagnostic and statistical manual of mental disorders – DSM - 5. Washington: American Psychiatric Association.
Bandini, C. S. M., Sella, A. C., Postalli, L. M. M., Bandini, H. H. M., & Silva, E. T. P. (2012). Effects of selection tasks on naming emergence in children. Psicologia: Reflexão e Crítica, 25(3), 568-577. doi: 10.1590/S010279722012000300017
Barreto, S. dos S., & Ortiz, K. Z. (2008). Medidas de inteligibilidade nos distúrbios da fala: revisão crítica da literatura. Pró-fono Revista de Atualização Científica, 20(3), 201-206. doi.org/10.1590/S0104-56872008000300011
Bevilacqua, M. C., & Tech, E. A. (1996). Elaboração de um procedimento de avaliação de percepção de fala em crianças deficientes auditivas profundas a partir de cinco anos de idade. In: I. Q. I. Marchesan, J. L. Zorzi & I. C. Gomes (Orgs.) Tópicos em Fonoaudiologia. Lovise, pp. 411-433.
Byers, B. J., Reichle, J., & Symons, F. J. (2012). Single-subject experimental design for evidence-based practice. American Journal Speech Language Pathology, 21(4), 397-414. doi.org/10.1044/1058-0360(2012/11-0036.
Carr, J. E., Nicolson, A. C., & Higbee, T. S. (2000). Evaluation of a brief multiplestimulus preference assessment in a naturalistic context. Journal of Applied Behavior Analysis, 33(3), 353–357. doi.org/10.1901/jaba.2000.33-353
Conceição, D. B., Greer, R. B., & Moschell, L. B. (2022). A general outline of the Verbal Behavior Developmental Theory. Revista Brasileira de Terapia Comportamental e Cognitiva, 24, 1–39. doi.org/10.31505/rbtcc.v24i1.164
Costa, N. T. O., Martinho-Carvalho, A. C., Cunha, M. C., & Lewis, D. R. (2012). Habilidades auditivas e comunicativas no espectro da neuropatia auditiva e mutação no gene Otoferlin: estudo de casos. Jornal da Sociedade Brasileira de Fonoaudiologia, 24(2), 181-187.
Delgado, E. M. C., & Bevilacqua, M. C. (1999). Lista de palavras como procedimento de avaliação da percepção dos sons da fala para crianças deficientes auditivas. Pró-Fono Revista de Atualização Científica, 11(1), 59-64.
Delgado, J. A. P. D., & Greer, R. D. (2009). The effects of peer monitoring training on the emergence of the capability to learn from observing instruction received by peers. The Psychological Record, 59(3), 407-434.
Fernandes, N. F., Morettin, M., Yamaguti, E. H., Costa, O. A., & Bevilacqua, M. C. (2015). Resultados do desempenho das habilidades auditivas em crianças com o espectro da neuropatia auditiva usuárias de implante coclear: revisão sistemática. Brazilian Journal of Otorhinolaryngology, 81(1), 85-96. doi. org/10.1016/j.bjorl.2014.10.003
Fiorile, C. A., & Greer, R. D. (2007). The induction of naming in children with no prior tact responses as a function of multiple exemplar histories of instruction. The Analysis of Verbal Behavior, 23, 71-87. doi.org/10.1007/BF03393048
Gilic, L., & Greer, R. D. (2011). Establishing naming in typically developing two-year-old children as a function of multiple exemplar speaker and listener experiences. Analysis of Verbal Behavior, 27(1), 157-77. doi.org/10.1007/ BF03393099
Gomes, C. G. S., & de Souza, D. G. (2016). Leitura combinatória e leitura com compreensão para aprendizes com autismo. Revista Brasileira de Educação Especial, 22(2), 233-252. doi.org/10.1590/S1413-65382216000200007
Greer, R. D., & Longano, J. (2010). A rose by naming: How we may learn how to do it. The Analysis of Verbal Behavior, 26(1), 73-106. doi.org/10.1007/ BF03393085
Greer, R. D., & Ross, D. E. (2008). Verbal behavior analysis: Inducing and expanding new verbal capabilities in children with language delays. New York: Pearsons Education.
Greer, R. D., & Speckman, J. (2009). The integration of speaker and listener responses: A theory of verbal development. The Psychological Record, 59, 449-488. doi.org/10.1007/BF03395674.
Greer, R. D., Stolfi, L., Chavez-Brown, M., & Rivera-Valdes, C. (2005). The emergence of the listener to speaker component of naming in children as a function of multiple exemplar instruction. The Analysis of Verbal Behavior, 21, 123-134. doi.org/10.1007/BF03393014
Greer, R. D., & Yuan, L. (2008). How kids learn to say the darndest things: The effect of multiple exemplar instruction on the emergence of novel verb usage. Analysis of Verbal Behavior, 24, 103-210. doi.org/10.1007/BF03393060
Guerra, B. T., Santo, L. A. A. do e., Barros, R. da S., & Almeida-Verdu, A. C. M. (2019). Ensino de Ecoico em Pessoas com Transtorno do Espectro Autista: Revisão Sistemática de Literatura. Revista Brasileira De Educação Especial, 25(4), 691–708. doi.org/10.1590/s1413-65382519000400010
Hawkins, E., Kingsdorf, S., Charnock, J., Szabo, M., & Gautreaux, G. (2009). Effects of multiple exemplar instruction on naming. European Journal of Behavior Analysis, 10, 265-273. doi.org/10.1080/15021149.2009.11434324.
Horne, P., Hughes, C., & Lowe, F. (2006). Naming and categorization in young children: IV: Listener behavior training and transfer of function. Journal of the Experimental Analysis of Behavior, 85(2), 247-273. doi:10.1901/ jeab.2006.125-04
Horne, P. J., & Lowe, F. C. (1996). On the origins of naming and other symbolic behavior. Journal of the Experimental Analysis of Behavior, 65(1), 185-241. doi.org/10.1901/jeab.1996.65-185
Horne, P., Lowe, F., & Randle, V. (2004). Naming and categorization in young children: II. Listener behavior training. Journal of the Experimental Analysis of Behavior, 81(3), 267-288. doi: 10.1901/jeab.2004.81-267
Kazdin, A. E. (2011). Single case research designs: Methods for clinical and applied settings. New York: Oxford, 2a. Edition.
Kedar, M., & Bauminger-Zviely, N. (2023). Predictors of individual differences in minimally verbal peer communication exchanges following peer-oriented social intervention. Autism Research: Official Journal of the International Society for Autism Research, 16(1), 230-244. https://doi.org/10.1002/aur.2852
Kobari-Wright, V., & Miguel, C. (2014). The effects of listener training on the emergence of categorization and speaker behavior in children with autism. Journal of the Experimental Analysis of Behavior, 47(2), 431-436.doi: 10.1002/jaba.115.
LaFrance, D. L., & Tarbox, J. (2019). The importance of multiple exemplar instruction in the establishment of novel verbal behavior. Journal of Applied Behavior Analysis, 22, 1-15. 10.1002/jaba.611.
Mascotti, T. S., & Almeida-Verdu, A. C. M. (2020). Diferenças entre o ensino por múltiplos exemplares e o treino por múltiplos exemplares: Revisão de literatura. Acta Comportamentalia, 28(3), 321-338.
McIlvane, W. J., & Stoddard, T. (1981). Acquisition of matching-to-sample performances in severe retardation: Learning by exclusion. Journal of Mental Deficiency Research, 25(1), 33-48. doi.org/10.1111/j.1365-2788.1981.tb00091.x
Merlin, A. M. B., Almeida-Verdu, A. C. M., Neves, A. J., Silva, L. T. N., & Moret, A. L. M. (2019). Ensino por múltiplos exemplares e integração de comportamentos de ouvinte e falante com unidades sintáticas substantivo-adjetivo em crianças com DENA e IC. CODAS, 31(3), 1-11, e20180135 doi.org/10.1590/23171782/20182018135.
Miguel C. F. (2016). Common and Intraverbal Bidirectional Naming. The Analysis of Verbal Behavior, 32(2), 125–138. https://doi.org/10.1007/s40616-0160066-2
Norrix, L. W., & Velenovsky, D. S. (2014). Auditory neuropathy spectrum disorder: A review. Journal of Speech, Language, and Hearing Research, 57, 15641576.
Nuzzolo-Gomez, R., & Greer, R. D. (2004). Emergence of untaught mands or tacts of novel adjective-object pairs as a function of instructional history. Analysis of Verbal Behavior, 20, 63-76. doi.org/10.1007/BF03392995
Olaff, H. S., & Holth, P. (2020). The emergence of bidirectional naming through sequential operant instruction following the establishment of conditioned social reinforcers. The Analysis of Verbal Behavior, 36, 21-48. doi.org/10.1007/ s40616-019-00122-0
Olaff, H. S., Ona, H. N., & Holth, P. (2017). Establishment of naming in children with autism through multiple response-exemplar training. Behavioral Development Bulletin, 22, 67-85. doi.org/10.1037/bdb0000044
Pereira, F. D., Assis, G. J. A., Palheta Neto, F. X. P., & Almeida-Verdu, A. C. (2018). Emergência de nomeação bidirecional em criança com implante coclear via instrução com múltiplos exemplares (MEI). Revista Brasileira de Terapia Comportamental e Cognitiva, 20(2), 23-36. doi.org/10.18542/rebac. v12i1.4023
Pinto, E. S. M., Lacerda, C. B. F., & Porto, P. R. C. (2008). Comparação entre os questionários IT-MAIS e MUSS com vídeo-gravação para avaliação de crianças candidatas ao implante coclear. Revista Brasileira de Otorrinolaringologia, 74(1), 91-98. doi.org/10.1590/S0034-72992008000100015
Queiroz, A. G., & Souza, C. B. A. (2021, 20 de dezembro). Echoic requirement in multiple exemplar instruction and naming in children with autism. https:// www.researchgate.net/publication/357280218
Rodriguez, N. M., & Thompson, R. H. (2015). Behavioral variability and autism spectrum disorder. Journal of Applied Behavior Analysis, 48(1), 167-187. doi.org/10.1002/jaba.164
Santos, E., & Souza, C. B. A. (2020). Uma Revisão Sistemática de Estudos Experimentais sobre Nomeação Bidirecional. Revista Brasileira de Análise do Comportamento, 16(2). dx.doi.org/10.18542/rebac.v16i2.9605
Santos, E. L. N., & Souza, C. B. A. (2016). Teaching naming with objects and figures for children with autism. Psicologia: Teoria e Pesquisa, 32(3), 1-10. doi.org/10.1590/0102-3772e32329.
Schlinger, H. D. (2008). Listening is behaving verbally. The Behavior Analyst, 31, 145-161. doi.org/10.1007/BF03392168
Scruggs, T. E., & Mastropieri, M. A. (2001). How to summarize single-participant research: ideas and applications. Exceptionality, 9(4), 227-244. doi. org/10.1207/S15327035EX0904_5
Silva, E. de C., Caixeta, L. M., & Elias, N. C. (2020). Emergência de respostas de ouvinte após ensino de intraverbais em um menino com Autismo. Perspectivas em Análise do Comportamento, 11(2), 152–161. doi.org/10.18761/PAC.2020. v11.n2.03
Sivaraman, M., Barnes-Holmes, D., Greer, R. D., Fienup, D. M., & Roeyers, H. (2023). Verbal behavior development theory and relational frame theory: Reflecting on similarities and differences. Journal of the Experimental Analysis of Behavior, 119(3), 539-553. doi.org/10.1002/jeab.836
Skinner, B. F. (1957). Verbal behavior. New York: Appleton-Century-Crofts
Souza, F. C., Almeida-Verdu, A. C. M., & Bevilacqua, M. C. (2013). Ecoico e nomeação de figuras em crianças com deficiência auditiva pré-lingual com implante coclear. Acta Comportamentalia, 21(3), 325-339.
Souza, C. B. A., & Calandrini, L. (2022). Pareamento de estímulos e aquisição de comportamento verbal em crianças com TEA1. Acta Comportamentalia, 30(1), 159-177.
Speckman, J., Greer, R. D., & Rivera-Valdes, C. (2012). Multiple exemplar instruction and the emergence of generative production of suffixes as autoclitic frames. Analysis of Verbal Behavior, 28(1), 83-99. doi.org/10.1007/BF03393109
Sundberg, M. L. (2008). Verbal behavior milestones assessment and placement program: The VB-MAPP. Concord, CA: AVB Press.
Tarlow, K. R., & Penland, A. (2016). Percentage of Nonoverlapping Data (PND) Calculator. http://www.ktarlow.com/stats/pnd
Yoder, P., Camarata, S., & Gardner, E. (2005). Treatment effects on Speech intelligibility and length of utterance in children with specific language and intelligibility impairments. Journal of Early Intervention, 28(1), 34-49. doi. org/10.1177/105381510502800105
Zimmerman-Phillips, S., Osberger, M. J., & Robbins, A. M. (1997). Assessment of auditory skills in children two years of age or younger. Presented at the 5th International Cochlear Implant Conference, New York, NY.
Grow, L. L., & Kodak, T. (2010). Recent research on emergent verbal behavior: Clinical applications and future directions. Journal of Applied Behavior Analysis, 43(4), 775-778. doi.org/10.1901/jaba.2010.43-775
Hawkins, E., Gautreaux, G., & Chiesa, M. (2018). Deconstructing common bidirectional naming: A proposed classification framework. The Analysis of Verbal Behavior, 34(1-2), 44–61. doi.org/10.1007/s40616-018-0100-7.