Articles

Esta obra está bajo una Licencia Creative Commons Atribución-NoComercial 4.0 Internacional.
Recepción: 17 Octubre 2019
Aprobación: 21 Octubre 2020
DOI: https://doi.org/10.38191/iirr-jorr.21.007
Resumen: El trabajo propone incorporar técnicas de Inteligencia Artificial a las herramientas disponibles para el análisis de coyuntura regional. Se comparan las estimaciones realizadas con Redes Neuronales (en concreto, mediante la utilización de redes con larga memoria de corto plazo, LSTM por sus siglas en inglés) con los instrumentos más habituales en el análisis de coyuntura (series temporales, indicadores sintéticos y factores dinámicos). Los resultados muestran que los avances en redes neuronales pueden ser incorporados al análisis de coyuntura mejorando las estimaciones. Son herramientas complementarias, con mayor flexibilidad para captar la diversidad de situaciones en la economía real y con una capacidad de estimación superior (menor error cuadrático medio). El documento propone la utilización de este tipo de técnicas para solucionar una diversidad de problemas en economía regional.
Palabras clave: predicción regional, redes neuronales, inteligencia artificial, LSTM.
Abstract: This paper studies the incorporation of Artificial Intelligence techniques to the set of tools available for the analysis of the regional situation. The estimates using long-short-term memory, LSTM, neural networks are compared with the most common instruments in the analysis of conjuncture (time series, synthetic indicators and dynamic factors). Results show that advances in neural networks can be incorporated into the tools used in regional economic analysis reducing the estimation error. They are complementary tools, with greater flexibility to capture the diversity of situations in the real economy and with a higher estimation capacity (lower mean square error). The document suggests the use of these types of techniques to solve a variety of problems in regional research.
Keywords: regional analysis, neural networks, artificial intelligence, LSTM.
1. Introducción
El seguimiento en tiempo real de la evolución de una economía es una tarea de interés y en constante mejora dadas las dificultades que conlleva. Cuando se realiza con detalle territorial el problema se multiplica, no solo por el mayor número de cálculos sino también por la menor disponibilidad de información y la necesidad de cuadrar los resultados obtenidos en un número mayor de dimensiones1.
Las motivaciones para realizar análisis de coyuntura a escala regional son diversas. En primer lugar, la mayor parte de los agentes económicos se ven más afectados por su entorno local que por la evolución conjunta de un país2. En segundo lugar, muchas de las medidas de política económica se toman de manera descentralizada; en este sentido, el seguimiento regional puede orientar las decisiones sobre actuaciones de gestión de la coyuntura macroeconómica (pe. política fiscal). Finalmente, dadas las características idiosincráticas de los territorios, el análisis de coyuntura económica regional es necesario para entender el comportamiento local y comprender así la evolución agregada3.
Las herramientas clásicas para llevar a cabo el análisis regional, de ciclos y coyuntura, realizan un trabajo bastante satisfactorio que con el tiempo ha ido mejorando. Podemos señalar los modelos de series temporales (Ramajo, Márquez y Hewings; 2015) los modelos de ecuaciones puente que ponen en relación un conjunto de indicadores con una determinada variable de interés, generalmente el PIB, habitualmente desarrollando indicadores sintéticos (Trujillo, Benítez y López, 1999; López y Castro, 2004; Pinkwart, 2018) mediante técnicas de componentes principales o similares y, finalmente, merecen un apunte las versiones más modernas y sofisticadas de los mismos, como son los modelos de factores dinámicos (Cuevas y Quilis, 2015; Gil et al., 2018; Casares, 2017).
Técnicas más utilizadas en predicción regional según frecuencia de los datos y plazo de predicción
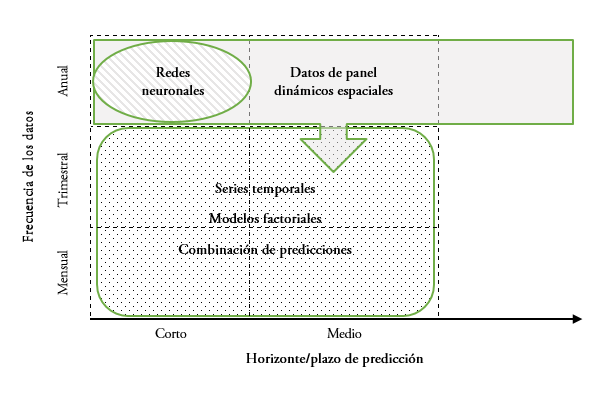
Fuente: deLucio y Cardenete (2019) a partir de Lehmann y Wohlrabe (2014).
Los resultados de la revisión internacional de los modelos de seguimiento y predicción regional realizada por Lehmann y Wohlrabe (2014) se ilustra en el diagrama 1; presenta los resultados de su trabajo en lo relativo a dos dimensiones: horizonte de predicción y la dimensión temporal de los datos utilizados. Lehmann y Wohlrabe (2014) concluyen que las técnicas más frecuentes son; series temporales, modelos factoriales y la combinación de diversos modelos. Señalan la escasa utilización de Redes Neuronales (RRNN, en adelante) a la par que recomiendan su uso.
Las técnicas de inteligencia artificial y el uso de redes neuronales en economía se remontan a décadas. Por ejemplo, Stock y Watson (2001) realizan una comparación de la capacidad predictiva de diversos modelos univariantes incluyendo RRNN de propagación hacia adelante. Moshiri y Cameron (2000) y Hill et al. (1994) mostraron que las redes neuronales con propagación hacia atrás pueden pronosticar tan bien como los métodos econométricos tradicionales. Varios autores Zhang et al. (1998), Huang et al. (2007), Crone et al. (2011) y Makridakis et al. (2018) señalan importantes mejoras de las RRNN en tareas de predicción y apuntan un avance significativo de estas técnicas. Podemos destacar también las revisiones del uso de estas técnicas en los mercados financieros por Chatterjee et al. (2000) y en gestión de empresas Tkáč y Verner (2016).
Sin embargo, a pesar del creciente interés que suscitan estas herramientas, como se ha señalado anteriormente, su utilización ha sido limitada para el análisis regional. Los únicos trabajos que identifican Lehmann y Wohlrabe (2014) de utilización redes neuronales son para las regiones alemanas (Patuelli et al, 2008; Patuelli et al, 2007 y Longhi et al, 2005). En estos trabajos se utilizan redes no recurrentes con datos anuales para el mercado de trabajo. En España únicamente conocemos el trabajo de Claveria et al. (2018) para la demanda de turismo regional. En ninguno de estos trabajos se utilizan RRNN recurrentes con memoria tal y como se propone en este documento. Adicionalmente, los documentos mencionados incorporan únicamente una variable mientras que este ejercicio propone un diseño multivariante. Como ampliación de estos trabajos, este documento utiliza redes recurrentes con memoria sobre datos trimestrales de un conjunto de variables para realizar seguimiento en tiempo real del PIB regional.
La utilización de RRNN se hace con el tiempo más accesible. La mejora en la capacidad de procesamiento de datos y el intenso desarrollo de estas técnicas ligado a otros campos (lenguaje, imagen, etc) facilita la extensión de la utilización de estas herramientas4. El desarrollo en otros campos del conocimiento muestra la calidad de los resultados proporcionados por estas herramientas y el potencial de las mismas para abordar nuevas preguntas de investigación. Así lo pone de manifiesto Varian (2014) que destaca el papel de las nuevas posibilidades que ofrece la Inteligencia Artificial (IA, en adelante) poniendo especial énfasis en la predicción. La OCDE (Woloszko, 2018) está explorando las posibilidades que ofrece la IA. Abadie y Kasy (2019) apuntan que: “The interest in adopting machine learning methods in economics is growing rapidly.” 5 Las RRNN son una metodología de IA que consigue identificar patrones complejos que permiten resolver un problema específico Mullainathan y Spiess (2017). Igualmente, estas herramientas pueden ser útiles, por ejemplo, para evitar los problemas derivados de un sobreajuste paramétrico (Abadie y Kasy6, 2019) y permiten enfocarse más en el objetivo de predicción. En general, estos modelos tienen como principal objetivo arrojar una estimación o previsión. En este sentido, la calidad de la estimación o previsión es el principal objetivo y no lo es la identificación de los parámetros que subyacen a la relación estimada. En IA, los problemas de predicción siguen una estrategia de minimizar el error de predicción frente al tradicional enfoque de generar estimadores insesgados7. Las técnicas de inteligencia artificial se enfocan en la predicción, y por ello resultan interesantes para el análisis de coyuntura, frente a la econometría clásica más centrada en la identificación de los parámetros específicos que definen de manera inequívoca las relaciones estructurales subyacentes entre variables.
La utilización de las técnicas que ofrece la IA coincide con el resto de las herramientas de análisis en que descansa en la teoría económica en, al menos, los siguientes aspectos: primero, la formulación de los problemas a analizar; segundo, la incorporación de los datos relevantes para el análisis y; tercero, la interpretación de los resultados obtenidos. Además, la IA destaca por ser más flexible en las relaciones susceptibles de gobernar el funcionamiento del sistema8. En consecuencia, estas herramientas son adecuadas para adaptarse a la complejidad de las relaciones económicas y a la velocidad con la que cambian las mismas.
Este documento propone la incorporación de los avances en materia del IA relativos a las RRNN recurrentes. De manera específica, aborda el análisis utilizando las redes de “larga memoria de corto plazo” (LSTM, por sus siglas en ingles Long Short-Term Memory) propuestas por Hochreiter y Schmidhuber (1997). Es una de las arquitecturas de aprendizaje profundo más avanzadas y exitosas para predicción de series temporales, reconocimiento de escritura y análisis de discurso. El trabajo estudia las posibilidades de las mismas aplicadas a modelos multivariantes para el seguimiento del PIB regional.
Finalmente, debemos señalar la conveniencia de utilizar modelos alternativos de estimación en el análisis de coyuntura. Bates y Granger (1969) señalan en un trabajo seminal que la combinación de distintas previsiones permite mejorar la capacidad predictiva. Stock y Watson (2001) apuntan en la misma dirección incorporando, entre otros métodos de estimación, las técnicas de redes neuronales9. A nivel regional, para España, López (2016) recomienda igualmente la agregación de varios modelos. En este contexto, este documento intenta mostrar la capacidad de estimación de los modelos de RRNN sumando así una nueva herramienta de análisis y modelización.
El trabajo muestra la utilidad de las técnicas de RRNN-LSTM y ofrece una comparación con otros modelos tradicionales. Adicionalmente, pone de manifiesto algunas posibilidades de análisis adicionales que se abren con el uso de estos nuevos instrumentos.
El resto del trabajo se estructura de la siguiente manera. La siguiente sección ilustra el funcionamiento de las RRNN y, en concreto, de las LSTM. Se dedica la tercera sección a presentar los modelos alternativos. Los datos y otros aspectos relativos a los soportes informáticos que exigen este tipo de técnicas se comentan en la sección 4. Los resultados se presentan en la sección 5. El documento finaliza con una sección de conclusiones y una exploración de las vías de investigación futuras.
2. Redes neuronales
Las redes neuronales se caracterizan por su flexibilidad y capacidad predictiva de fenómenos complejos. Permiten, por ejemplo, replicar el comportamiento de funciones no lineales y comportamientos asimétricos a lo largo del ciclo. Una red neuronal sencilla, con una única capa intermedia, como la de la ecuación (1), permite relacionar “n” variables de entrada, xn, con una variable de salida, H. La capa intermedia tendría pesos de entrada, wjn, y de salida, wj. Las variables de entrada xn se conectan con las “𝑗” neuronas de la capa intermedia, y está con la variable de salida, H, a través de los pesos y las funciones de activación, 𝜑𝑗 y ψ , respectivamente.
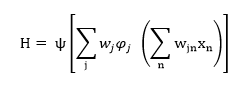 [1]
[1]Los pesos se modifican en cada iteración con objeto de reducir las diferencias entre el valor observado en la variable de salida y la estimación obtenida. Las funciones de activación, 𝜑𝑗 y ψ , utilizadas con mayor frecuencia son la sigmoidal (logística) 10 y la tangente hiperbólica11 aunque existen multitud de alternativas.
La figura 1 propone una representación gráfica de una red neuronal sencilla como la ilustrada en la ecuación (1). Tiene una capa de entrada de variables y otra capa de salida. Ambas se relacionan, en este caso, a través de una única capa intermedia oculta. Los pesos de salida, wj, y de entrada, wji, se modifican en cada iteración. El comportamiento de la red ilustrada en la figura 1 está gobernado por los parámetros y funciones de activación.
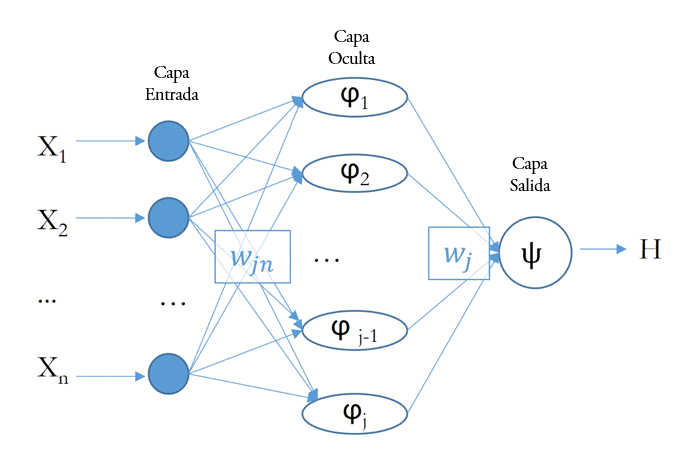
Figura 1.
Red neuronal estándar
Fuente: Elaboración propia.
Esta red neuronal sencilla no es capaz de pasar información de la fase actual a la siguiente. Es decir, este tipo de estructura no es capaz de conservar información previa como input. Las Redes Neuronales Recurrentes (RNN en adelante, por sus siglas en inglés, Recurrent Neural Networks) reciben como entrada la salida de una o varias de las etapas anteriores. Podemos representar una red neuronal recurrente como copias múltiples de la misma red, en la que cada red pasa un mensaje a la siguiente (Olah, 2015). Las RNN tienen bucles internos que permiten que la información persista. La figura 2 representa, a la izquierda, una RNN y, a la derecha, su representación desarrollada; cuando se presentan de manera independiente las distintas fases del bucle. En cada una de las fases la información de entrada X1 … X𝑡 se transforma en salidas, H1 … H𝑡 mediante una red neuronal. Entre las distintas etapas se traslada información.
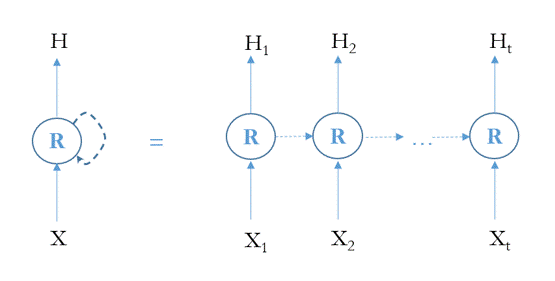
Figura 2.
Red neuronal recurrente. Representación compacta y desarrollada
Fuente: Elaboración propia.
Las RNN han sido exitosas en una variedad de problemas: reconocimiento de voz, tratamiento de imagen, traducción, entre otras. En general, son especialmente útiles en tareas que tienen un componente secuencial. Precisamente, esta característica, la capacidad de predicción de secuencias (pe. lenguaje), tiene especial interés en el ámbito de la economía (pe. en el ámbito de las series temporales). Tanto en la estimación de secuencias de lenguaje como en los análisis de la evolución de la economía es conveniente recordar una serie de características pasadas. En lenguaje pueden ser de carácter gramatical (tiempo, genero, número). En economía, pueden estar relacionadas con la fase cíclica, la amplitud del ciclo y duración de una determinada etapa del mismo. Esta información contenida en la serie puede ser tenida en cuenta para calcular estimaciones y previsiones.
Dado que en economía la información del pasado inmediato es relevante, el desempeño de las RNN puede ser muy adecuado. Sin embargo, en determinadas circunstancias también puede ser oportuno recordar información de un pasado más lejano. Bengio et al. (1994) identifican algunas razones por las que las RNN no son eficientes para modelos que necesitan mayor memoria a largo plazo, principalmente ponen de manifiesto el trade-off entre recordar información durante periodos de tiempos largos y el entrenamiento adecuado de la red12. En los modelos económicos necesitamos información que puede estar disponible más allá de los datos recientes. En economía puede ser oportuno ligar sucesos pasados al comportamiento actual y futuro. Para solventar este problema de aprendizaje a largo plazo que presentan las RNN, Hochreiter y Schmidhuber (1997) desarrollaron las redes con larga memoria de corto plazo (Long Short-Term Memory - LSTM en adelante). Las LSTM son un tipo de RNN, capaces de aprender las dependencias a largo plazo. Mantienen una capa de memoria en la que almacenan información relevante en el proceso de cálculo.
En una RNN, como la representada en la figura 2, la estructura de la función R sería una estructura simple similar a la de la figura 1 y la ecuación 1. En una LSTM el módulo R de la figura 2 tiene tres compuertas interaccionando, Alcocer et al. (2018). La estructura de las redes LSTM estaría representada por la figura 3 y las ecuaciones (2), (3) y (4), correspondientes a las compuertas de: memoria (olvidar-recordar), copiar y salida.
En todas las compuertas se utiliza la información de salida de la etapa anterior, ℎ𝑡−1, y los datos de entrada en el momento 𝑡, X𝑡, a través de los vectores de pesos, 𝑊 y 𝑈. En todas las funciones se incorpora una constante, 𝑏.
La función ftecuación (2), determina en cada momento del tiempo la información que resulta necesario borrar o almacenar en la capa de memoria. Con este fin, se utiliza una función sigmoide, 𝜎
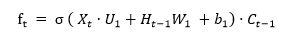 [2]
[2]En un segundo paso, la función Ct, ecuación (3), se decide qué información copiar en la capa de memoria Para ello se utiliza una función multiplicativa de manera que una función tangente decide la relevancia de la información y la función sigmoidea decide si se debe actualizar la información o ignorar. Esta información se suma a la obtenida en el paso previo, ft.
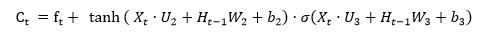 [3]
[3]Finalmente, ecuación (4), se decide qué información ofrecer como salida. Para ello, una función tangente que actúa sobre la información anterior, Ct, para considerar la relevancia de la misma, se multiplica por una función sigmoidea que actúa con los pesos correspondientes sobre la información de entrada.
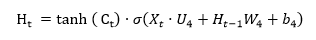 [4]
[4]Las tres etapas mencionadas se ilustran en la figura 3, en la parte inferior aparecen las tres funciones que acabamos de presentar. Cada una de estas tres etapas se separa con líneas verticales. Las anexiones de información (multiplicativas o aditivas) están representadas por el signo correspondiente recuadrado. Así, la clave en una red neuronal LSTM es el almacén de memoria que permite que la información pasada se vaya actualizando13 de acuerdo va llegando nueva información. La capa de memoria viene representada por la ecuación (3) y la línea horizontal superior de la figura 3.

Figura 3.
Caracterización de una de las etapas de las redes LSTM
Fuente: Elaboración propia.
A continuación, se aplica esta técnica al seguimiento económico de carácter coyuntural regional y se compara su desempeño con otras técnicas habituales.
3. Modelos de referencia
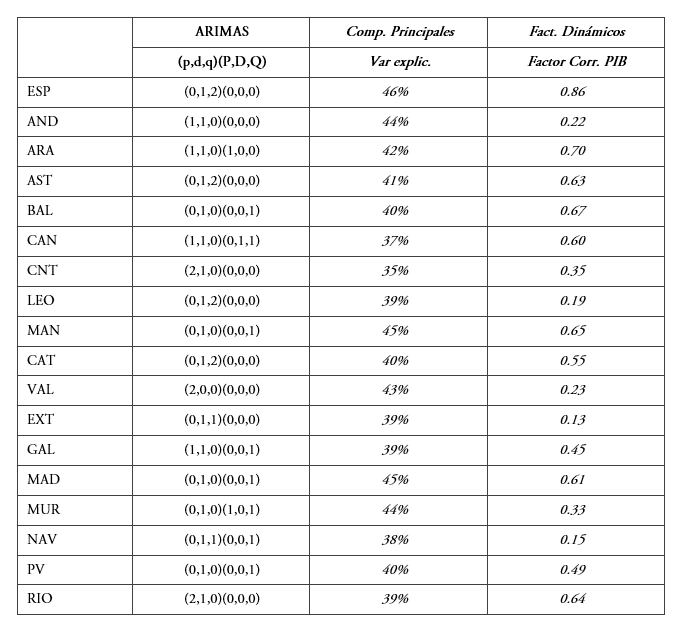
Para analizar la validez de las LSTM para el análisis coyuntural se comparan los resultados obtenidos con las estimaciones derivadas de otros modelos frecuentemente utilizados en el análisis de coyuntura. En concreto, se utilizan modelos ARIMA uniecuacionales, modelos de ecuaciones puente y de factores dinámicos14.
Modelos ARIMA con componente estacional se desarrollan a partir del trabajo seminal de Box y Jenkins (1970). La representación formal del modelo ARIMA estacional (p,d.q)·(P,D,Q), de la variable H, se corresponde con la ecuación (5). En donde p es el orden del operador autoregresivo, 𝜙. El orden del operador media móvil, 𝜃, es q. Los órdenes de los operadores estacionales, Φ y Θ, son P y Q, respectivamente. Las diferencias regulares y estacionales son de orden, d y D respectivamente, y están representadas en la ecuación por, 𝑦. El término de error ruido blanco es 𝜀𝑡.
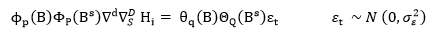 [5]
[5]Para el análisis de series temporales se ha utilizado X-13ARIMA-SEATS a través del paquete de Python Statsmodels, Seabold y Perktold (2010)15. Esta librería permite la selección automática de los parámetros del modelo que mejor ajustan a cada una de las series, seleccionando aquellos parámetros que minimizan el ECM. En la tabla 3 en el anexo se proporciona la especificación final de cada uno de los modelos utilizados.
Ecuaciones puente con indicadores sintéticos, ver una aplicación reciente en Pinkwart (2018), ponen en relación las variables explicativas con la variable a explicar. La opción más sencilla sería la utilización directa en la regresión de las variables independientes. Versiones más elaboradas extraen la información de las variables explicativas construyendo indicadores sintéticos de diverso tipo. En este trabajo se ha utilizado componentes principales y factores dinámicos. La formulación matemática de estos modelos viene representada por la ecuación (6):
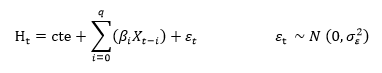 [6]
[6]En donde la variable dependiente, 𝐻𝑡, se hace depender del valor contemporáneo y los retardos de las variables explicativas, 𝑋𝑡−𝑖. Siendo 𝑖 el número de retardos, q el orden de los mismos. 𝛽𝑖 son los parámetros a estimar. 𝜀𝑡 es el término de error ruido blanco.
Así, para extraer la información sintética de las variables explicativas se ha elaborado un análisis de componentes principales16 con la librería de Statsmodels para Python, Seabold, S., y Perktold, J. (2010). El primer componente principal se utiliza como variable explicativa del modelo. La relación finalmente estimada no incorpora retardos17. La tabla 3 en el anexo muestra el porcentaje de varianza explicado por el primer componente.
Factores dinámicos alcanzan popularidad gracias al trabajo de Giannone, Reichlin y Small (2008). En general, un modelo de factores dinámico se describe de acuerdo con (7) donde X𝑡 es un conjunto de variables, ft son los factores inobservados (que pueden tener un comportamiento de un vector autorregresivo de orden p, ecuación (8), más un ruido blanco ηt), Λ es la matriz de factores de carga y ut es el término de error; ruido blanco con una matriz de covarianzas diagonal 𝑅.
 [7]
[7]
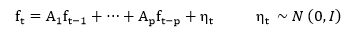 [8]
[8]De la misma forma que en el caso anterior los factores se incorporan en un modelo de regresión. La principal diferencia es que en el modelo de factores dinámicos los factores se reestiman a través de la representación de espacio estado (8). Para la realización de las estimaciones se ha utilizado un solo factor calculado con la librería Statsmodels18. La tabla 3 en el anexo muestra la correlación entre el factor y el crecimiento del PIB.
4. Datos
La Contabilidad Regional de España (CRE) se elabora por el INE en el marco de las Cuentas Nacionales. Esta fuente estadística facilita datos anuales, pero no proporciona datos trimestrales necesarios para el análisis de coyuntura. Por su parte, no todos los institutos de estadística regionales publican cuentas trimestralizadas ni utilizan metodologías homogéneas. La única institución oficial que proporciona datos trimestralizados del PIB regional es la AIReF; utiliza la metodología elaborada por Cuevas y Quilis (2015) y toma como referencia las Cuentas Nacionales del INE. Las series trimestrales que proporcionan para el PIB regional constituye las variables de salida, H, a estimar por el modelo19.
Las variables de entrada, X, se han seleccionado siguiendo criterios económicos y metodológicos. Desde el punto de vista económico es oportuno que las variables seleccionadas sean similares a los indicadores utilizados por el INE (1993) en la elaboración de las cuentas trimestrales nacionales. Las cuentas nacionales es la estadística de referencia para calcular el crecimiento regional trimestral de la AIReF. Además, es oportuno que los indicadores mantengan relación con el PIB, con los principales sectores de actividad (perspectiva de la oferta), con las variables de demanda y con el mercado de trabajo.
Desde el punto de vista metodológico es necesario que sean indicadores homogéneos para todas las CCAA y que puedan ser utilizados en las distintas técnicas. Otros criterios de calidad estadística, disponibilidad (pe. desfase, puntualidad en la difusión, accesibilidad) y frecuencia también han sido tenidos en consideración.
La tabla 1 refleja los indicadores finalmente seleccionados, así como algunas características de estos; como la frecuencia, la fecha de inicio de disponibilidad de la información, la fuente y la transformación realizada para el análisis. La fecha de actualización de la base de datos ha sido 31 de diciembre de 2019. El último dato disponible para el crecimiento regional corresponde al tercer trimestre del año 2019. La base de datos resultante es de datos trimestrales (en algunos casos construidos a partir de datos mensuales, las transformaciones realizadas vienen reflejadas en la columna correspondiente) desde el primer trimestre de 2002 al tercero de 2019.
Variables utilizadas y transformaciones
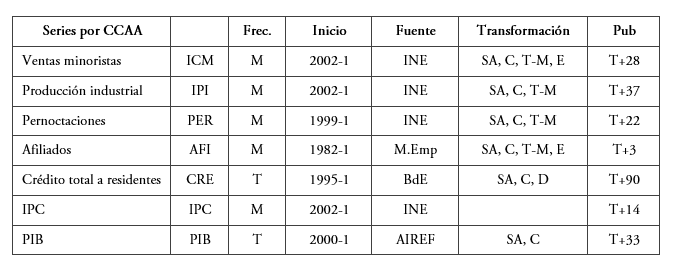
Frecuencia, códigos: M: Mensual, T: Trimestral.
Transformación, códigos: SA: Ajuste Estacional, C: Crecimiento, T-M: Trimestralizada a partir de datos mensuales, T-A: Trimestralizada a partir de datos anuales. D: Deflación de variables nominales por IPC. E: Serie enlazada. Pub (publicación) días de retraso en relación con el periodo de referencia (T). Se trabaja con variables normalizadas en los modelos de ecuaciones puente, factores dinámicos y redes neuronales.
Software
El análisis se ha realizado con Python 3.5. Se han utilizado los paquetes numpy (Van Der Walt et al, 2011), pandas (McKinney, 2010) y matplotlib (Hunter, 2007) para visualizar datos y statsmodels (Seabold y Perktold, 2010) en los modelos de referencia. Las redes LSTM de aprendizaje profundo han sido desarrolladas con keras (Chollet, 2015) y construidas sobre TensorFlow (Abadi et al., 2015), librería de inteligencia artificial desarrollada por Google.
5. Resultados
La simulación llevada a cabo replica una situación real en la que se dispondría, en un determinado momento, de información sobre las variables explicativas, no se tiene acceso a la información oficial sobre el crecimiento y se necesita de una estimación del crecimiento regional.
Para ello, en la simulación se utiliza toda la información disponible hasta 𝑡-1 para la modelización y la obtención de los parámetros estimados. Esto permite obtener la estimación de la variable dependiente que se compara con los valores observados hasta 𝑡-1, a este ejercicio le denominamos estimación “dentro de la muestra”. Por otro lado, calculamos el valor estimado del crecimiento en 𝑡 con información de las variables independientes del periodo, 𝑡, y los parámetros estimados del modelo con información hasta 𝑡-1, sería la estimación “fuera de la muestra” que igualmente se compara con el valor conocido. Para obtener las estimaciones fuera de la muestra este proceso que acabamos de presentar se realiza para los tres últimos años, desde el tercer trimestre de 2016 al segundo trimestre de 2019. Tanto para las estimaciones dentro como fuera de la muestra, para comparar la cercanía de la estimación al valor real, se utiliza la medida de la raíz del error cuadrático medio (RECM).
Como se ha señalado en la sección anterior, en todos los modelos se han programado mecanismos semi-automáticos en las que no es necesaria la intervención directa sobre los cálculos específicos de ninguna CCAA concreta. Este procedimiento evita la introducción de sesgos por parte del investigador y descansa en las reglas incorporadas en las rutinas utilizadas, comentadas en la sección 3. En los modelos multivariantes se emplean las mismas variables de entrada normalizadas y todos los modelos tienen como criterio de optimización la minimización de la RECM.
En el caso de las redes neuronales LSTM, para minimizar el riesgo de sobreparametrización, se ha construido la mínima red viable. En concreto, se ha utilizado una capa con 5 unidades más una capa adicional de salida. Para cada red se realizan 100 iteraciones, con minibatch de 40. Las redes neuronales realizan un proceso de convergencia hacia el óptimo que puede converger en un óptimo local o global. Por ello se recomienda realizar varias estimaciones. Para las 17 CCAA y el conjunto de España se han realizado 100 estimaciones que nos proporcionan una idea del rango de variación de los resultados obtenidos. La función de perdida es el error cuadrático medio con el algoritmo optimizador denominado Adam, propuesto por Kingma y Ba (2014). El conjunto de entrenamiento es de 12 años (48 trimestres), el resto de información se utiliza como validación (test) dejando una última observación para las estimaciones fuera de la muestra. Así, el conjunto de datos de test es en media20 de 16 trimestres; esto supone una distribución de los datos del 75% entrenamiento y 25% test. El número total de parámetros estimados es de 226 por red21.
El gráfico 1 ilustra la evolución del error cuadrático medio (ECM) en una de las estimaciones según se avanza en el número de iteraciones, tanto para la muestra de entrenamiento como para el subconjunto de observaciones que componen el test. Como puede observarse el ECM desciende rápidamente durante las primeras 25 iteraciones y mantiene una pendiente de descenso gradual con posterioridad. A partir de la iteración 40, aproximadamente, la evolución del ECM es bastante similar entre ambas submuestras.
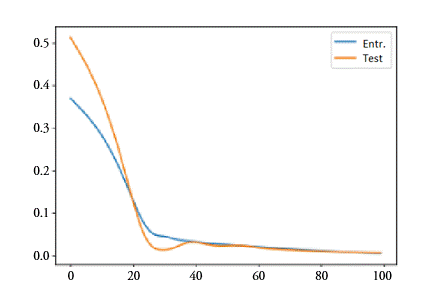
Gráfico 1.
Ejemplo de funciones de pérdida (ECM) en función del número de iteraciones
Fuente: Elaboración propia.
El gráfico 2 presenta la raíz del ECM para las 17 CCAA y el conjunto de España de los distintos modelos, el gráfico 6 en el anexo presenta los mismos datos sin considerar el periodo de crisis financiera22. En general, los resultados de las distintas metodologías son satisfactorios para todas las economías analizadas. En algunas CCAA uniprovinciales como Murcia o La Rioja, los errores, de todas las metodologías, son algo más elevados. Mientras que, en CCAA de mayor dimensión económica, como Madrid, parece que se obtienen estimaciones más ajustadas al dato objetivo en todas las metodologías.
Se observa que las técnicas de LSTM ofrecen RECM inferiores a los de los demás modelos. En 9 de las 17 CCAA las redes LSTM proporcionan un ajuste superior a cualquiera de las técnicas restantes. En las otras 8 CCAA solo una de las técnicas alternativas consigue proporcionar resultados con menor error. En cualquier caso, todas las metodologías permiten un ajuste razonable al dato objetivo poniendo así de manifiesto que todas las técnicas son de utilidad y deben incorporarse a la caja de herramientas del análisis de coyuntura. Dados los resultados obtenidos con redes neuronales LSTM se considera recomendable incorporar al análisis regional de coyuntura esta nueva aproximación.
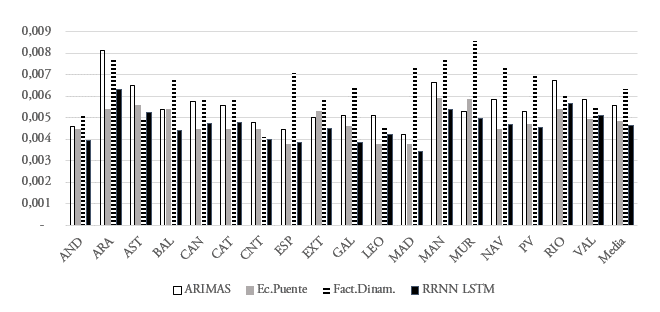
Gráfico 2.
Raíz del error cuadrático medio de las estimaciones. Dentro de la muestra
AND: Andalucía; ARA: Aragón; AST: Asturias; BAL: Baleares; CAN: Canarias; CAT: Cataluña; CNT: Cantabria; ESP: España; EXT: Extremadura; GAL: Galicia; LEO: Cast. León; MAD: Madrid; MAN: Cat. La Mancha; MUR: Murcia; NAV: Navarra; PV: País Vasco; RIO: La Rioja; VAL: C. Valenciana.
Fuente: Elaboración propia.El gráfico 3 presenta los resultados fuera de la muestra, para la predicción en tiempo real del dato de crecimiento. Los errores son inferiores a los presentados en el gráfico 2. La mayor precisión de las estimaciones fuera de la muestra podría deberse a que el periodo utilizado para este ejercicio ha tenido menor oscilación cíclica. Al igual que en el gráfico anterior, se observa que las redes neuronales LSTM tienen una RECM fuera de la muestra inferior a la observada con el resto de metodologías. En todas las CCAA, excepto en Navarra, las redes LSTM consiguen un menor error de estimación que el resto de técnicas.
La mejora de las estimaciones con redes LSTM en relación con el resto de modelos se sintetiza en la tabla 2. Presenta la media del porcentaje de mejora en la RECM de las distintas CCAA que proporcionan las redes LSTM con relación a los modelos alternativos. Se producen mejoras significativas en todos los casos, tanto dentro de la muestra como especialmente fuera de la muestra. De acuerdo con lo señalado anteriormente, las técnicas de redes, más enfocadas en la predicción, ofrecen mejores resultados en esta tarea. En general, las mejoras observadas en los modelos LSTM en relación con el resto de opciones analizadas fuera de la muestra permite reducir el RECM entre un 49% y un 62%. El rango dentro de la muestra es inferior, 3%-24%. La mejora de los modelos LSTM es elevada, aunque algo menor de la obtenida por Siami-Namini y Namin (2018) en la comparación de modelos ARIMA y LSTM, 84-87%23. A escala regional, Claveria et al. (2018) utilizan RRNN para predecir la demanda de turismo. Su trabajo muestra, al igual que los resultados presentados, un buen desempeño de las RRNN para el análisis regional.
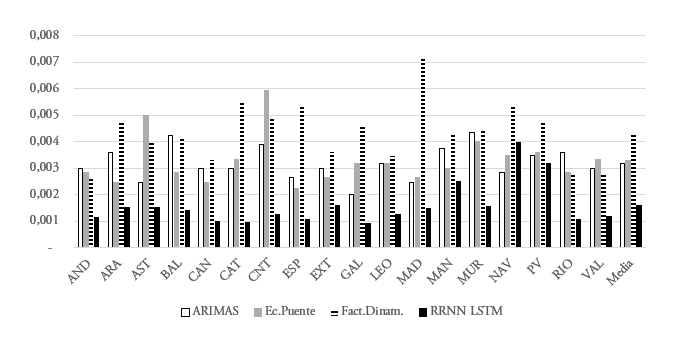
Gráfico 3.
Raíz del error cuadrático medio de las estimaciones. Fuera de la muestra
Fuente: Elaboración propia.
Disminución de la RECM promedio de las redes LSTM en relación con el resto de procedimientos de estimación a nivel CCAA
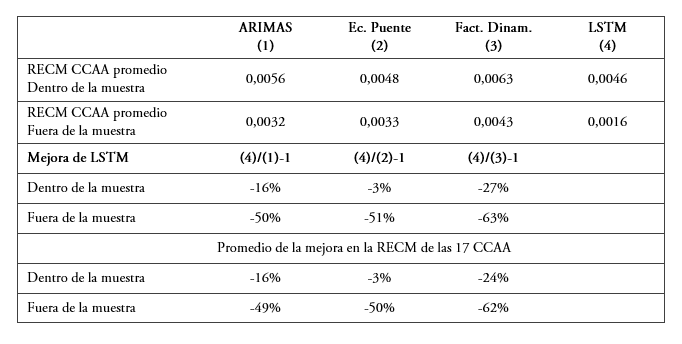
Fuente: Elaboración propia.
Los datos y gráficos que acabamos de comentar utilizan la media de las RECM que se obtiene para los 100 modelos estimados de redes LSTM. El gráfico 4 permite observar la distribución de los errores tanto dentro (bloques azules a la izquierda del marcador de cada región) como fuera de la muestra (bloques naranjas a la derecha de la marca regional). Las figuras proporcionan información sobre datos atípicos, el rango de variación, la mediana y la media (triangulo verde). Se observa que en general los modelos LSTM que se estiman están cercanos a la media, aunque existen algunos casos puntuales en los que los errores son significativamente superiores y en otros casos inferiores. En los casos en los que la media es más elevada también los rangos de variación son superiores. La utilización de la mediana o la moda en lugar de la media ofrece todavía resultados más favorables a los presentado al eliminar la influencia de las estimaciones más atípicas. Como cabe esperar parece existe una correlación positiva, aunque reducida (17%) a escala regional en la precisión de la estimación dentro de la muestra y fuera de la muestra.
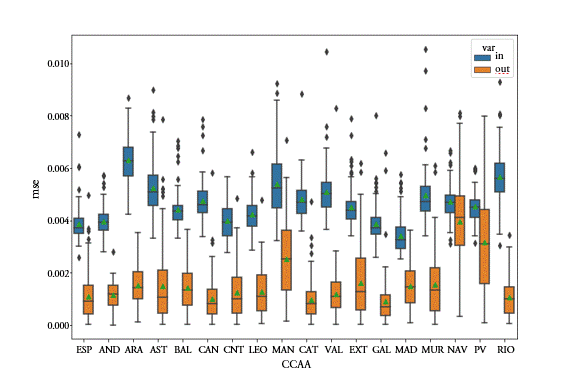
Gráfico 4.
Distribución de las 100 estimaciones del modelo RRNN LSTM para el último periodo
Fuente: Elaboración propia.
Finalmente, el gráfico 5 presenta la evolución de las 100 estimaciones realizadas con LSTM para España y el crecimiento intertrimestral de la economía. El anexo II, gráfico 7, presenta para las 17 CCAA el gráfico equivalente. Como se puede observar, en general, la estimación obtenida por los modelos consigue replicar el ciclo. Algunas de las estimaciones no consiguen replicar adecuadamente la evolución de la economía y se alejan de la media del resto de estimaciones y del dato objetivo. De nuevo esta circunstancia apunta a que a nivel aplicado se desechen las estimaciones más irregulares. Estas estimaciones atípicas parecen converger a un óptimo local frente al óptimo global al que parece converger la mayoría. Tal y como cabía esperar, las estimaciones de los 100 modelos parecen concentrarse más en los periodos de estabilidad cíclica y menos en los cambios de ciclo.
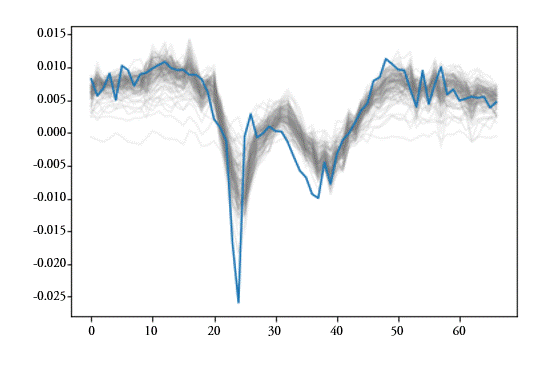
Gráfico 5.
Crecimiento intertrimestral España. Evolución de la estimación y el dato AIReF
Fuente: Elaboración propia.
6. Conclusiones
Este trabajo muestra que las técnicas de RRNN y, en concreto, las modelizaciones que incorporan memoria, las denominadas LSTM, pueden ser utilizadas con resultados satisfactorios en el análisis de coyuntura regional. Tal y como muestran Lehmann y Wohlrabe (2014) estas herramientas han sido escasamente utilizadas para el análisis regional.
El trabajo muestra que las redes LSTM ofrecen resultados competitivos en comparación con los instrumentos tradicionales y, además, sus estimaciones son complementarias utilizando una aproximación diferente y en rápido avance (Hewamalage y Bergmeir, 2019).
Las redes LSTM proporcionan errores inferiores dentro de la muestra a los de otras alternativas. Entre las cuatro técnicas analizadas, las redes se encuentran, en todas las CCAA, entre las dos alternativas que ofrecen menores errores de estimación y en la mayoría de los casos es la técnica mejor.
Estructuras de redes relativamente sencillas permiten disminuir el error medio fuera de la muestra entre un 49% y un 62% dependiendo de la técnica de referencia. En el análisis fuera de la muestra, los errores de las redes LSTM son inferiores a los del resto de metodologías en todas menos en una comunidad autónoma. Este resultado está en línea con los trabajos de Siami-Namini y Namin (2018) y Makridakis et al. (2018). Estructuras de redes más complejas o la simple selección del modelo con menor error permitiría proporcionar mejoras más importantes.
Sabemos que la utilización de diversas técnicas de estimación tiene ventajas de cara al análisis económico y, en concreto, para el análisis de coyuntura. Los beneficios son especialmente útiles cuando la información que recogen los distintos instrumentos es diferente. En este sentido, las RRNN proporcionan una aproximación novedosa respecto a propuestas metodológicas más consolidadas. Las estimaciones obtenidas con RRNN tienen menos desviaciones en relación con los datos observados. Además, la metodología de RRNN es más flexible y permite captar una mayor variedad de comportamientos cíclicos. Son capaces de recoger comportamientos y relaciones entre variables más complejas. Por los motivos mencionados, estas técnicas son útiles a escala regional y se propone la incorporación de esta metodología a las ya consolidadas.
A pesar de la validez y el interés de estos resultados, cabe destacar algunas áreas en las que se necesita mayor trabajo. En primer lugar, el ejercicio realizado con redes LSTM de seguimiento de la economía regional en tiempo real puede extenderse a contextos diferentes como son la predicción a largo plazo y la detección de recesiones y cambios de ciclo. Desde el punto de vista del análisis de coyuntura también es oportuno explorar las posibilidades de estas técnicas para solventar algunos de los problemas tradicionales como: la incorporación de variables explicativas con frecuencias diversas, la utilización de series con datos ausentes, con diferentes retardos de difusión e indicadores con sincronía cíclica variada. También cabe estudiar las posibilidades de las RRNN para relajar supuestos ad-hoc sobre el comportamiento de series que requieren de técnicas de reparto arbitrarias (por ejemplo, en relación con los plazos de ejecución de una licitación). Igualmente, se puede estudiar la posibilidad de incorporar los criterios de consistencia que se consideren oportunos. Además, es conveniente realizar análisis similar al presentado con datos de alta frecuencia o grandes bases de datos. Finalmente, desde la aproximación regional las líneas de investigación apuntan a la exploración de las posibilidades que ofrecen las RRNN para analizar los efectos espaciales entre regiones o los impactos de políticas económicas. Por ejemplo, la estimación simultanea de todas las regiones puede permitir estudiar las dinámicas espaciales.
En definitiva, la incorporación de las herramientas que se desarrollan en el marco de la IA y específicamente de las redes neuronales LSTM abre un número de posibilidades muy importante a la vez que muestra ya unos resultados muy positivos en materia de seguimiento de la coyuntura regional.
Referencias
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg, J., Man_e, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Vi_egas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., y Zheng, X. (2015). TensorFlow: Large-scale machine learning on heterogeneous systems. Software available from tensorow.org
Abadie, A., y Kasy, M. (2019). Choosing among Regularized Estimators in Empirical Economics: The Risk of Machine Learning. Review of Economics and Statistics Volume 101(5), 743-762.
Alcocer, U. M. R., Tello-Leal, E., y Alvarado, A. B. R. (2018). Modelo basado en redes neuronales LSTM para la predicción de la siguiente actividad en el proceso de negocio. Pistas Educativas, 40(130).
Artola, C., Fiorito, A., Gil, M., Pérez, J. J., Urtasun, A., y Vila, D. (2018). Monitoring the Spanish economy from a regional perspective: main elements of analysis. Documento Ocasional Banco de España 1809.
Bandrés, E., y Gadea, M. D., (2013). Crisis Económica y Ciclos Regionales en España. Papeles de Economía Española, 138, 2-30.
Bates, J. M., y Granger, C. W. J. (1969). The Combination of Forecasts. Operations Research Quarterly 20, 451–468.
Bengio, Y., Simard, P., y Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157–166.
Box, G. E. P., y Jenkins, G. M. (1970). Time Series Analysis: Forecasting and Control. San Francisco.
Casares, F. F. (2017). Nowcasting: Modelos de Factores Dinámicos y Ecuaciones Puente para la Proyección del PIB del Ecuador. COMPENDIUM: Cuadernos de Economía y Administración, 4(8), 25-46.
Chatterjee, A., Ayadi, O., y Boone, B. (2000). Artificial Neural Network and the Financial Markets: A Survey. Managerial Finance, 26(12), 32-45.
Chollet, F. et al. (2015). Keras. https://github.com/keras-team/keras
Claveria, O., Monte, E., y Torra, S. (2018). A regional perspective on the accuracy of machine learning forecasts of tourism demand based on data characteristics. IREA Working Papers. University of Barcelona, Research Institute of Applied Economics.
Crone, S. F., Hibon, M., y Nikolopoulos, K. (2011). Advances in forecasting with neural networks? Empirical evidence from the NN3 competition on time series prediction. International Journal of Forecasting, 27(3), 635–660.
Cuevas, A., y Quilis, E. M. (2015). Quarterly Regional GDP Flash Estimates for the Spanish Economy (METCAP model). Autoridad Independiente de Responsabilidad Fiscal AIReF, Working Paper n. 3.
de Lucio, J., y Cardenete, A. (2019). Predicción económica regional para la toma de decisiones. La Riqueza de las Regiones: Aportaciones de la Ciencia Regional a la Sociedad, 183-196. Thomson Reuters.
Gadea, M. D., Gómez-Loscos, A., y Montañés, A. (2012). Cycles inside cycles: Spanish regional aggregation. SERIEs Journal of the Spanish Economic Association, 3, 423-456.
Giannone, D., Reichlin, L., y Small, D. (2008). Nowcasting: The real-time informational content. Journal of Monetary Economics 55(4), 665-676.
Gil, M., Leiva-León, D., Pérez, J. J., y Urtasun, A. (2018). An application of dynamic factor models to nowcast regional economic activity. Banco de España, mimeo.
Glaeser, E., Duke, S., Luca, M., y Naik, N. (2018). Big Data and Big Cities: The Promises and Limitations of Improved Measures of Urban Life. Economic Inquiry, 56, 114-137. https://doi.org/10.1111/ecin.12364
Hewamalage, H., y Bergmeir, C. (2019). Recurrent Neural Networks for Time Series Forecasting: Current Status and Future Directions. Mimeo.
Hill, T., Marquez, L., O’Connor, M., y Remus, W. (1994). Artificial Neural Network Models for Forecasting and Decision Making. International Journal of Forecasting, 10, 5–15.
Hochreiter, S., y Schmidhuber, J. (1997). Long short-term memory. Neural Computation. 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Huang, W., Lai, K. K., Nakamori, Y., Wang, S., y Yu, L. (2007). Neural networks in finance and economics forecasting. International Journal of Information Technology & Decision Making, 6(01), 113-140.
Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9, 90–95.
INE (1993). Contabilidad Nacional Trimestral de España (CNTR). Metodología y serie trimestral 1970-1992. Instituto Nacional de Estadística.
Kingma, D. P., y Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kleinberg, J., Ludwig, J., Mullainathan, S., y Obermeyer, Z. (2015). Prediction policy problems. American Economic Review, 105(5), 491-95.
Lehmann, R., y Wohlrabe, K. (2014). Regional economic forecasting: state-of-the-art methodology and future challenges. Economic and Business Letters, 3(4), 218–231.
Longhi, S., Nijkamp, P., Reggiani, A., y Maierhofer, E. (2005). Neural network modeling as a tool for forecasting regional employment patterns. International Regional Science Review, 28(3), 330-346.
López, A. M. (2016). El papel de la información económica como generador de conocimiento en el proceso de predicción: comparaciones empíricas del crecimiento del PIB regional. Estudios de Economía Aplicada, 34, 553-582.
López, A. M. y Castro, R. (2004). Valoración de la actividad económica regional de España a través de indicadores sintéticos. Estudios de Economía Aplicada, 22, 631-655.
Makridakis, S., Spiliotis, E., y Assimakopoulos, V. (2018). Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 13(3): e0194889. https://doi.org/10.1371/journal.pone.0194889
McKinney, W. (2010). Data structures for statistical computing in Python. En S. van der Walt y J. Millman (Eds.), Proceedings of the 9th Python in science conference.
Moshiri, S., y Cameron, N. (2000). Neural network versus econometric models in forecasting inflation. Journal Forecast, 19, 201-217
Mullainathan, S., y Spiess, J. (2017). Machine Learning: An Applied Econometric Approach. Journal of Economic Perspectives, 31(2), 87-106.
Olah, C. (2015). Understanding LSTM Networks. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Patuelli, R., Longhi, S., Nijkamp, P., y Reggiani, A. (2008). Neural networks and genetic algorithms as forecasting tools: a case study on German regions. Environment and Planning B: Planning and Design, 35(4), 701-722.
Patuelli, R., Longhi, S., Nijkamp, P., Reggiani, A., y Blien, U. (2007). A rank-order test on the statistical performance of neural network models for regional labor market forecasts. The Review of Regional Studies, 37(1), 64-81.
Pinkwart, N. (2018). Short-term forecasting economic activity in Germany: A supply and demand side system of bridge equations. Discussion Papers 36. Deutsche Bundesbank.
Ramajo, J., Márquez, M. A., y Hewings, G. J. D. (2015). Spatiotemporal Analysis of Regional Systems: A Multiregional Spatial Vector Autoregressive Model for Spain. International Regional Science Review, 40, 75-96.
Seabold, S., y Perktold, J. (2010). Statsmodels Econometric and statistical modeling with python. Proceedings of the 9th Python in Science Conference.
Siami-Namini, S., y Namin, A. S. (2018). Forecasting economics and financial time series: ARIMA vs. LSTM. arXiv preprint arXiv:1803.06386.
Stock, J.H., y Watson, M. (2001). A Comparison of Linear and Nonlinear Univariate Models for Forecasting Macroeconomic Time Series. En R.F. Engle y H. White (Eds.), Festschrift in Honour of Clive Granger (pp.1-44). Cambridge University Press.
Tkáč, M., y Verner, R. (2016). Artificial neural networks in business: Two decades of research. Applied Soft Computing, 38, 788-804.
Trujillo, F., Benítez, M. D., y López, P. (1999). Indicadores Sintéticos Trimestrales de la Actividad Económica No Agraria en Andalucía. Revista de Estudios Regionales, 53, 97-128.
Van Der Walt, S., Chris Colbert, S., y Varoquaux, G. (2011). The NumPy array: a structure for efficient numerical computation. Computing in Science and Engineering, Institute of Electrical and Electronics Engineers, 13(2), 22-30.
Varian, H. R. (2014). Big Data: New Tricks for Econometrics. Journal of Economic Perspectives, 28(2), 3–28.
Woloszko, N. (2018). Economic Modeling & Machine Learning, OECD. https://techpolicyinstitute.org/wp-content/uploads/2018/02/Woloszko_Macroeconomic-forecasting-with-machine-learning-TPI.pdf
Zhang, G., Patuwo, B. E., y Hu, M. Y. (1998). Forecasting with artificial neural networks: The state of the art. International Journal of Forecasting, 14(1), 35–62.
Anexos
Descriptivos de los modelos alternativos
AND: Andalucía; ARA: Aragón; AST: Asturias; BAL: Baleares; CAN: Canarias; CAT: Cataluña; CNT: Cantabria; ESP: España; EXT: Extremadura; GAL: Galicia; LEO: Cast. León; MAD: Madrid; MAN: Cat. La Mancha; MUR: Murcia; NAV: Navarra; PV: País Vasco; RIO: La Rioja; VAL: C. Valenciana.
Fuente: Elaboración propia.
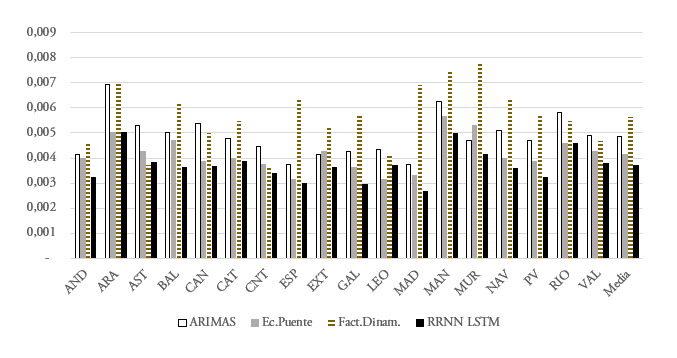
Gráfico 6.
Raíz del error cuadrático medio de las estimaciones. Dentro de la muestra. Sin crisis financiera
(periodos en los que la reducción del crecimiento económico intertrimestral fue superior a un punto porcentual, IVT 2008 y IT2009)
Fuente: Elaboración propia.
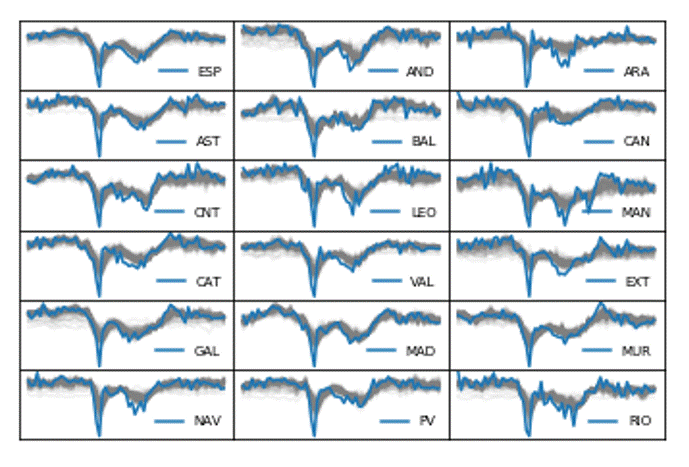
Gráfico 7.
Crecimiento intertrimestral del PIB. Representación de las 100 iteraciones del modelo. RRNN-LSTM y del dato oficial
Fuente: Elaboración propia.
Notas
Información adicional
Clasificación JEL: C45; C53; E27; R15.
Autor responsable de la correspondencia: Juan.deLucio@uah.es
Agradecimientos: El autor agradece los comentarios de la editora y de dos evaluadores anónimos y el apoyo financiero de la Comunidad de Madrid y la UAH (EPU-INV/2020/006) y de la Comunidad de Madrid (H2019/HUM-5761).
