Recursos e Técnicas de Ensino e Pesquisa
SmartPLS 3: Especificação, estimação, avaliação e relato
SmartPLS 3: specification, estimation, evaluation and reporting
SmartPLS 3: Especificação, estimação, avaliação e relato
Administração: Ensino e Pesquisa, vol. 20, núm. 2, pp. 488-536, 2019
Associação Nacional dos Cursos de Graduação em Administração

Esta obra está bajo una Licencia Creative Commons Atribución 4.0 Internacional.
Resumo: A modelagem de equações estruturais com estimação por mínimos quadrados parciais (PLS-SEM) tem sido empregada nas mais variadas áreas de pesquisa, aumentando a quantidade de artigos publicados com o uso desse método de modo exponencial. Há vários motivos para que isso esteja ocorrendo, mas um deles é o fato do software SmartPLS ter facilitado o uso do PLS-SEM. Este artigo tem o objetivo de apresentar sete exemplos didáticos com conjuntos de dados reais e disponíveis àqueles que queiram aprender ou ensinar PLS-SEM, tratando de temas como: avaliação do modelo de mensuração, avaliação do modelo estrutural, multicolinearidade, variável latente de segunda ordem, mediação, moderação com variável numérica e categórica (MGA – multi-group analysis).
Palavras-chave: Modelagem de Equações Estruturais, SmartPLS 3, Mínimos Quadrados Parciais.
Abstract: The structural equation modeling with partial least squares estimation (PLS-SEM) has been used in a wide variety of research areas, increasing the number of articles published using this method in an exponential way. There are several reasons for this to be happening, but one of them is the fact that the SmartPLS software facilitated the use of PLS-SEM. This article aims to present seven didactic examples with real data sets available to those who want to learn or teach PLS-SEM, dealing with such topics as measurement model evaluation, structural model evaluation, multicollinearity, second-order latent variable, mediation, moderation with numerical and categorical variables (MGA - multi-group analysis).
Keywords: Structural Equations Modeling, SmartPLS 3, Partial Least Squares.
INTRODUÇÃO
A modelagem de equações estruturais com estimação por mínimos quadrados parciais (PLS-SEM) nas áreas das ciências sociais e do comportamento tem se mostrado como uma excelente possibilidade para a avaliação de relações entre construtos (ou fatores, componentes, variáveis latentes, variáveis não observadas, subescalas etc.), pois é robusta à falta de normalidade multivariada e é viável para amostras pequenas (menores que ~100 casos). Aspectos esses muito presentes no uso de escalas de atitude. Cabe um alerta que vale à pena ser repetido: não justifique o uso do SmartPLS 3 apenas devido à amostra ser pequena (GUIDE; KETOKIVI, 2015). A complexidade do modelo, a ausência de normalidade multivariada dos dados ou a necessidade de uso de constructos com variáveis formativas são outras razões para se justificar o uso do PLS-SEM.
Além disso, ao se coletar dados com escalas de atitude deve-se ter em mente que muitas respostas não terão boa qualidade, por diversas razões, e assim, o tamanho das amostras mínimas (RINGLE et al., 2014a, 2014b) deve ser dobrado ou triplicado para se evitar que os dados de “baixa” qualidade prejudiquem a análise e resultados.
O PLS-SEM é uma técnica “flexível” capaz de estimar modelos complexos (muitos construtos, muitas variáveis, muitas relações causais entre construtos – setas – e modelos formativos), por isso, tem uma grande “sintonia” com as pesquisas do campo de saber apontadas e com a natureza dos problemas e dos dados provenientes de relações sociais humanas.
Ele se adequa muito bem em situações que a teoria que sustenta as relações causais ainda não tem grande “sedimentação” e pode ser usada de forma mais “exploratória”. Nesse sentido, a complexidade dos problemas e dos processos sociais não possibilita que (ainda) se tenha teorias com grau de generalização como em outras áreas do conhecimento, tais como em Física e Química, por exemplo, fato este que reforça o uso da técnica estatística em questão.
Recaindo mais no cerne deste artigo, tem-se com objetivo principal a apresentação de algumas técnicas avançadas e/ou complementares e servir de material de referência para aqueles interessados em aprender, ensinar e usar a modelagem de equações estruturais com estimação por mínimos quadrados parciais (PLS-SEM), por isso, todos os dados e modelos foram disponibilizados em Bido e Silva (2019). .
Salienta-se que em Ringle et al. (2014a, 2014b) há explicações mais gerais e básicas (indicadores formativos e reflexivos, variáveis endógenas e exógenas, definição do tamanho da amostra, uso do software etc.), do que o presente artigo, neste sentido, ele é recomendado como uma leitura preliminar.
O foco deste artigo está mais no uso do software SmartPLS 3 do que nas atividades e decisões anteriores (definições, hipóteses etc.), dessa maneira, o presente trabalho foi estruturado sob a forma de sete exemplos, e para tirar o melhor proveito deste material, sugere-se uma leitura completa seguida da modelagem de cada exemplo a partir dos conjuntos de dados (.csv ou .txt).
Como o SmartPLS 3 apresenta muitas saídas (output) e o espaço para artigos sempre é muito limitado, a formatação dos resultados como é explicada neste artigo pode ser um exercício útil.
EXEMPLO 1 – ANÁLISE DE COMPONENTES CONFIRMATÓRIA (ACC)
Na modelagem de equações estruturais baseada em covariâncias (LISREL, AMOS, EQS, SAS, Stata, lavaan) é recomendado se rodar a análise em duas etapas (ANDERSON; GERBING, 1988), primeiro a AFC (análise fatorial confirmatória), que é um modelo em que todas as variáveis latentes (VL) são correlacionadas entre si, para se avaliar o modelo de mensuração e depois outro modelo incluindo as relações estruturais (hipóteses).
No contexto de PLS-SEM esta abordagem não é recomendada porque o algoritmo é “partial” (a iteração ocorre em etapas: mensuração Ò estrutural Ò mensuração Ò ..., até haver a convergência, isto é, os resultados de uma etapa praticamente são iguais aos da etapa anterior). Isto quer dizer que se for usada a abordagem em duas etapas, pode acontecer de se obter um modelo adequado na primeira etapa (ACC), mas inadequado na segunda etapa porque a parte estrutural é diferente daquele usado na ACC. Assim, o recomendado é se rodar o modelo estrutural direto no PLS-SEM, mesmo que a análise da mensuração seja feita separada do modelo estrutural.
Por isso, este modelo (ACC) não tem sido muito utilizado, mas ele pode ser útil quando o objetivo é apenas avaliar o modelo de mensuração das VL e se obter escores fatoriais para uso em análises posteriores.
Especificação
Para exemplificar a análise de componentes confirmatória (ACC) foi utilizado o modelo DLOQ (Dimensions of the Learning Organization Questionnaire) de Marsick e Watkins, que já foi replicado tantas vezes que teve um número especial na Advances in Developing Human Resources (v.15, n.2, 2013) e no Brasil foi validado o DLOQ-A (A de “abreviado”, que em vez de usar seis indicadores por VL, usa três indicadores por VL) por Menezes et al. (2011).
A partir deste comentário, conclui-se que o método mais adequado é o SEM-CB (SEM baseado em covariâncias, com softwares como LISREL, AMOS, EQS, Mplus e lavaan), mas foi decidido usar este modelo como exemplo porque os dados estavam disponíveis e porque é um exemplo ilustrativo das decisões que são tomadas durante a análise (não faça isso no seu artigo – usar PLS-SEM, quando o correto seria SEM baseado em covariâncias). Na Figura 1 estão as sete dimensões do DLOQ-A, cujos conteúdos estão explicitados no artigo de Menezes et al. (2011, p. 27-29).
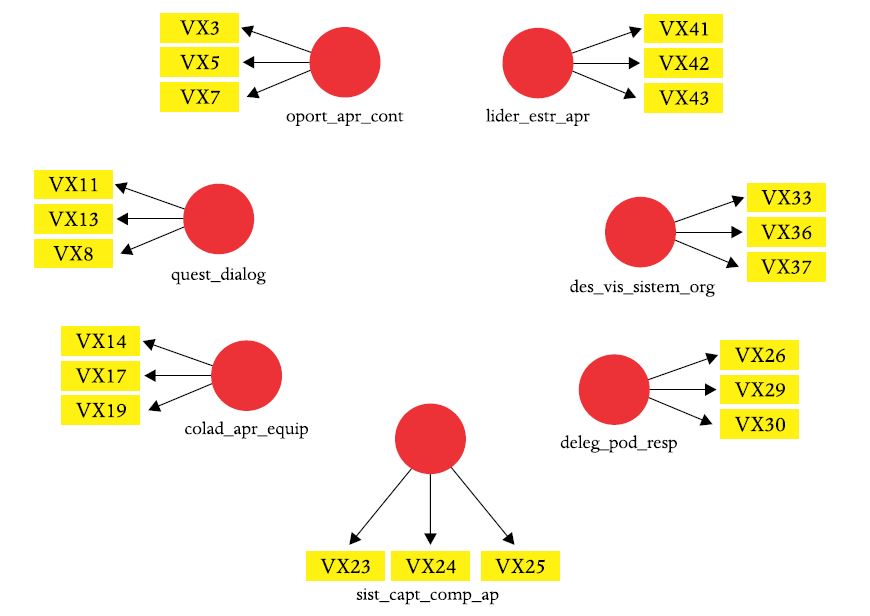
Figura 1
Indicadores por variável latente
Nota: Indicadores disponíveis em Menezes et al. (2011).
Estimação
No SEM-CB todas as VL exógenas são correlacionadas por default, mas no PLS-SEM é preciso incluir essas relações (Figura 2), porque o algoritmo é “partial”, isto é, precisa das relações de mensuração e estrutural para haver as iterações (BIDO et al., 2010, p. 252). Os resultados apresentados nas setas (path coefficients) não serão usados para nada nesta análise, por isso, não importa a sequência em que se conecte as VL.
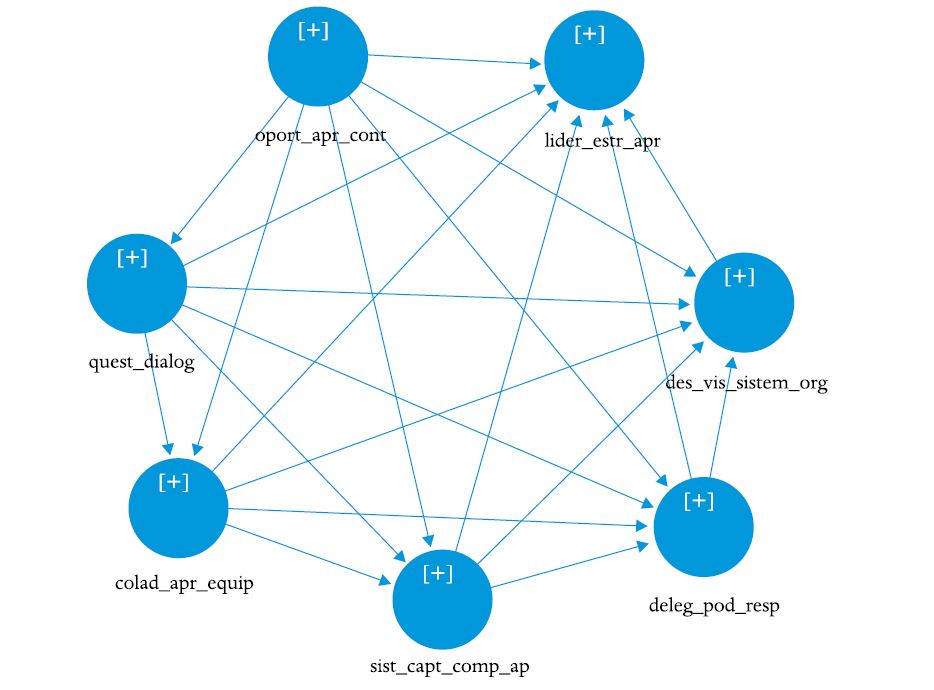
Figura 2
Conectando todas variáveis latentes entre si
Nota: Todas as VL devem ser conectadas com todas as outras, e apesar do sentido das setas não ser importante aqui, não pode haver feedbacks (modelo não recursivo). Neste modelo iniciou-se pela VL “oport_apr_cont”, enviando setas para todas as outras, em seguida “quest_dialog”, continuando no sentido anti-horário até todas VL terem seis setas conectadas a elas (chegando ou saindo). As variáveis observadas ou mensuradas (indicadores reflexivos ou itens da escala) foram escondidas (função hide/show) para deixar mais limpa a figura.
No algoritmo PLS seleciona-se a opção “factor weighting scheme” (Figura 3) e do output são analisadas as correlações entre as VL e as cargas fatoriais (factor loadings e crossloadings
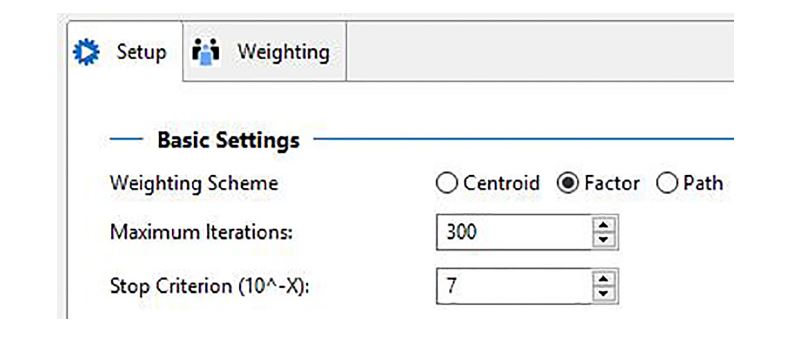
Figura 3
Esquema de ponderação no algoritmo PLS para a ACC
Nota: No Menu do SmartPLS 3 use: Calculate > PLS algorithm > Factor > Start calculation
O bootstrap é usado para obter os valores-p das correlações entre as VL e das cargas fatoriais no SmartPLS 3 da seguinte maneira:
· Calculate > Bootstrapping > Complete bootstrapping (Figura 4) > Start Calculation
· Output do Bootstraping > Quality Criteria > Latent variable correlations (Nota 2 no rodapé na Tabela 1)
· Output do Bootstraping > Final Results > Outer loadings (Nota de rodapé na Tabela 2)
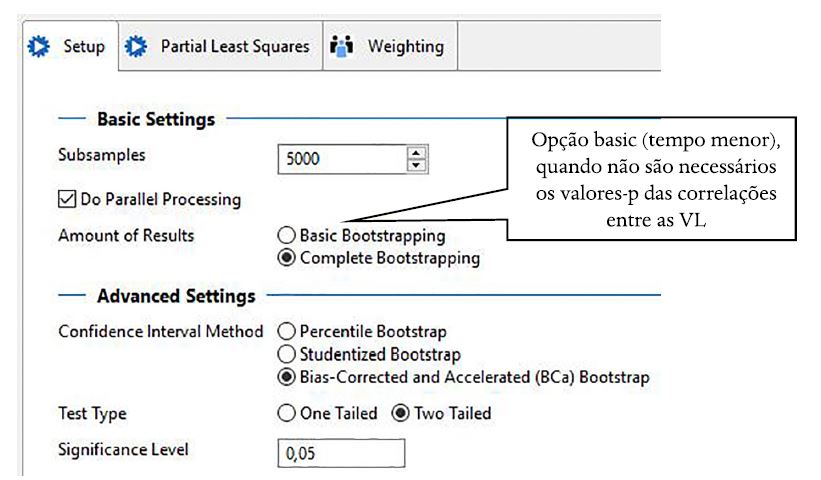
Figura 4
Bootstrapping para se obter os valores-p
Nota 1: Nas versões anteriores ao SmartPLS 3.2.8 havia opções para lidar com as mudanças de sinais, que causavam bimodalidade nos resultados do bootstrapping, porém, das três opções, duas delas (no sign e individual sign) às vezes não resolviam ou pioravam o problema, por isso, foram retiradas na versão mais atual. Nota 2: A cada rodada do algoritmo bootstrapping, os resultados serão um pouco diferentes (erro padrão, valor-t, valor-p), porque ele se baseia em reamostragem aleatória e com reposição, mas se um coeficiente é significante (p<0.05) isso não deve mudar de uma rodada para outra. Compare os valores-p da Tabela 3 com os seus (são rodadas diferentes de bootstrapping).
Avaliação e relato
Na ACC é avaliado apenas o modelo de mensuração (não há modelo estrutural), o que é feito a seguir, a partir do modelo estimado no software SmartPLS 3 (RINGLE et al., 2015).
O SmartPLS 3 produz vários resultados, mas é preciso algum trabalho para formatá-los. São necessárias duas tabelas (Tabela 1 e 2) para se avaliar o modelo de mensuração. A primeira é usada para a análise no nível das VL e a segunda para a análise no nível dos indicadores, recomenda-se que elas sejam avaliadas simultaneamente.
A Tabela 1 foi preparada da seguinte maneira:
· Output PLS algorithm > Quality Criteria:
o Discriminant validity > Fornell-Larcker Criterion > Excel format
o Colar em pasta do Excel
o Construct reliability and validity > Excel format
o Colar na mesma pasta do Excel (em qualquer local)
o Copiar os resultados de confiabilidade, que foram colados > clique-direito (logo abaixo da matriz de correlações) > Colar especial > Transpor
o Numerar as VL e substituir os nomes no cabeçalho por números.
o Incluir a nota 1 no rodapé.
· Output Bootstraping > Quality Criteria:
o Latent variable correlations
o Incluir a nota 2 no rodapé.
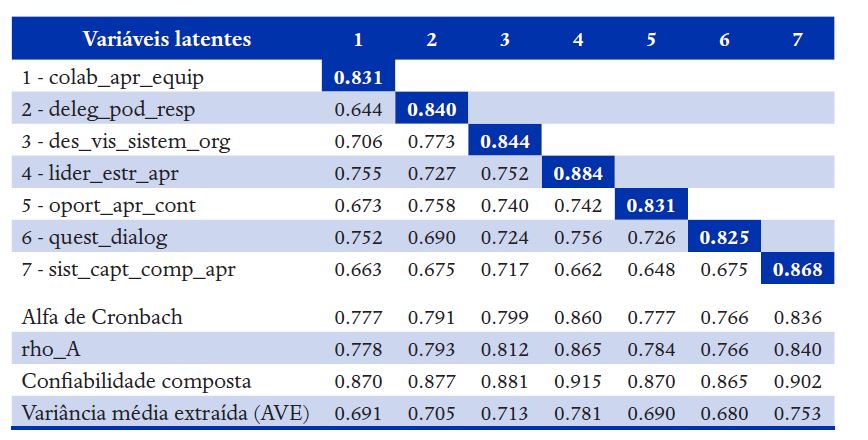
Nota 1: Os valores na diagonal são a raiz quadrada da AVE.Nota 2: Todas as correlações são significantes a 1%.Nota 3: Aqui foram mantidas as três medidas de confiabilidade, como uma forma de mostrar as possibilidades, mas recomenda-se usar a confiabilidade composta, como foi feito nas tabelas 4 e 6.
A Tabela 2 foi preparada da seguinte maneira:
· Output PLS algorithm > Quality Criteria:
o Discriminant validity > Cross-loading > Excel format
o Colar em pasta do Excel (Figura 5)
o Observe que os indicadores são listados em ordem alfabética e não por VL, por isso, o formato na Figura 5b ainda precisa ser rearranjado.
o Mover as linhas de modo que os indicadores da mesma VL fiquem juntos e a tabela deverá ficar como uma “escada” (Tabela 2).
· Output Bootstraping > Final Results:
o Outer loadings
o Incluir a nota 1 no rodapé
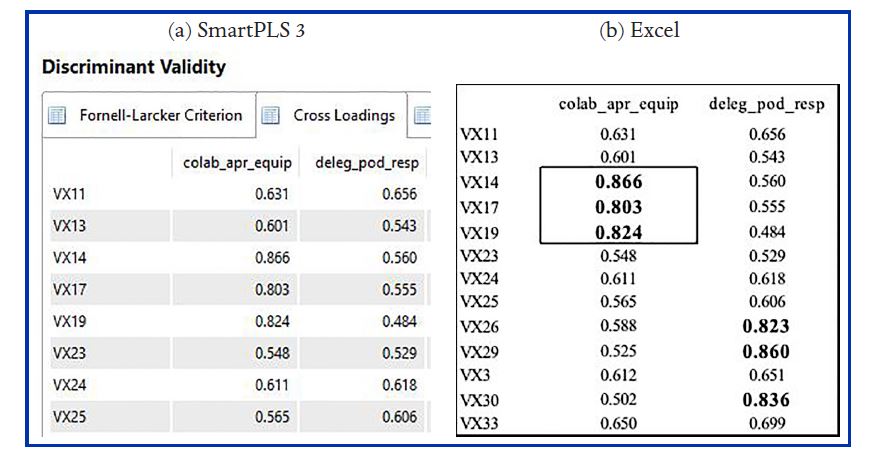
Figura 5
Output PLS algorithm
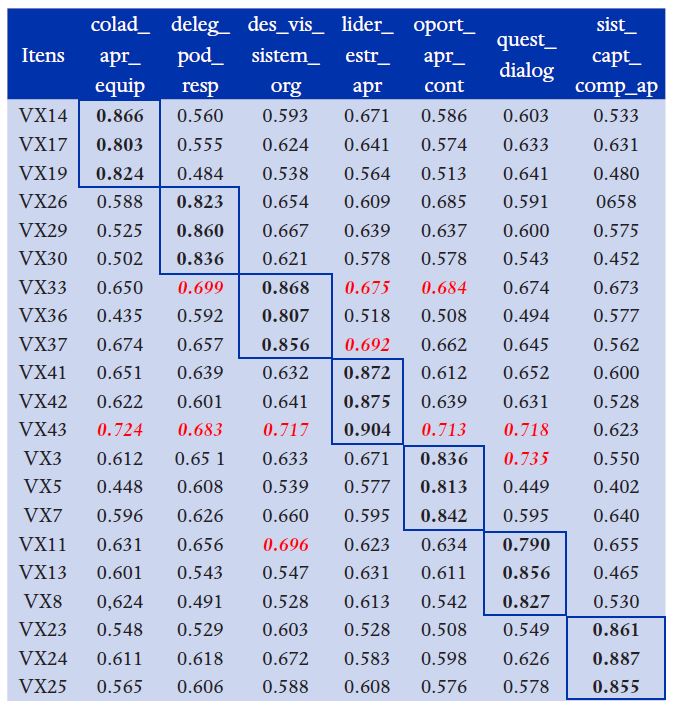
Nota 1: Todas as cargas fatoriais são significantes a 1%.Nota 2: As cargas cruzadas altas foram formatadas em vermelho e itálico.
Com os resultados formatados nas Tabelas 1 e 2, a avaliação do modelo de mensuração é feita na seguinte sequência (*):
· Validade convergente:
o no nível dos indicadores: carga > 0.7 (Tabela 2)
o no nível das VL: AVE > 0.5 (Tabela 1)
· Validade discriminante:
o No nível das VL: √ AVE > rVL (Tabela 1)
o No nível dos indicadores: cargas fatoriais > cargas cruzadas (na horizontal e vertical na Tabela 2)
· Confiabilidade
o CR > 0.7 (Tabela 1)
(*) Sugere-se essa sequência porque um dos pressupostos para a avaliação da confiabilidade, é que o construto é unidimensional, ou seja, sua validade convergente e discriminante devem estar adequadas, por isso, se houver problema de validade convergente ou discriminante, não deveria se prosseguir para a avaliação da confiabilidade.
Na Tabela 1 observa-se que, para todas as VL, AVE > 0.5 e √AVE > rVL, bem como CR > 0.7, portanto, a validade convergente, discriminante e confiabilidade estão adequadas. Entretanto, as correlações entre todas as VL são bem altas (da ordem de 0.65 a 0.75) o que faz sentido no presente modelo, já que todas as VL são dimensões da cultura de aprendizagem (MENEZES et al., 2011).
Na Tabela 2 observa-se que as cargas fatoriais (em negrito) são maiores que as cargas cruzadas (cargas “fora da diagonal”), confirmando a validade discriminante, ainda assim, há cargas cruzadas altas (algumas da ordem de 0.7), o que é coerente com as altas correlações entre as VL (Tabela 1), mas esses valores altos levantam algumas dúvidas:
· Se for usada a matriz HTMT (heterotrait-monotrait ratio) para avaliar a validade discriminante deste modelo, observa-se que algumas correlações desatenuadas são superiores a 0.85 (potencial problema de validade discriminante), mas há correlações desatenuadas superiores a 0.90, o que indica falta de validade discriminante por este critério (HAIR Jr. et al., 2016). Essa matriz está no: Output PLS algorithm > Discriminant Validity > heterotrait-monotrait ratio. Como uma escala tão replicada ainda tem esse tipo de problema? O foco deste artigo não está na discussão teórica de cada modelo, mas algumas respostas seriam:
· As VL são conceitos de nível organizacional, medidos por indivíduos da mesma organização, então, a unidade de análise seria a percepção individual a respeito de um fenômeno organizacional, que é mais homogêneo do que se a unidade de análise estivesse no nível das organizações mesmo (cada caso igual uma organização)
· Mesma pessoa avaliando vários construtos no mesmo momento e com formatos de assertivas iguais, há potencial de viés do método comum (CMB - common method bias) (MACKENZIE; PODSAKOFF, 2012).
· Apesar do DLOQ e DLOQ-A serem escalas muito replicadas, em geral, se analisa apenas o alfa de Cronbach antes de se gerar os escores fatoriais por meio de escala-somada. Tanto Menezes et al. (2011), quanto Yang (2003) tiveram problemas com a escala completa (DLOQ) quando avaliaram a validade convergente e discriminante.
· Essas VL serão usadas nos próximos exemplos (modelos estruturais), então, ficarão mais claras as consequências de se mantê-las separadas ou agrupadas.
Neste exemplo todas as cargas fatoriais foram altas (maiores que 0.8), mas há casos em que os valores mínimos recomendados não são atingidos na primeira rodada. No Quadro 1 são sugeridas algumas providências para melhorar o ajuste do modelo.
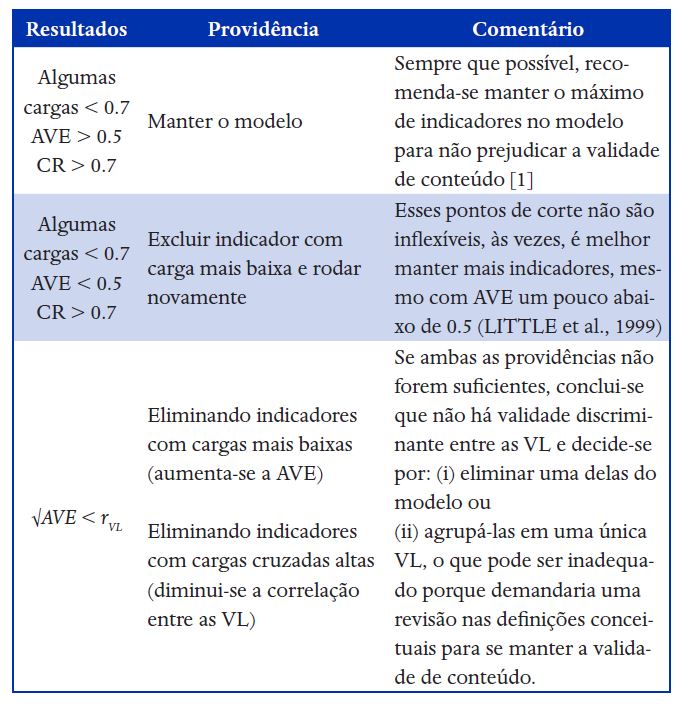
Nota 1: Ao se eliminar muitos indicadores da mensuração pode ocorrer outros problemas: capitalização no acaso (chance capitalization) levantando a dúvida sobre a replicabilidade dos resultados em nova amostra, inviabiliza a comparação com resultados de outros estudos e prejudica a aplicação da escala em estudos futuros (DEVELLIS, 2016; NETEMEYER et al., 2003). Hair Jr. et al. (2010, p.690) dão uma recomendação para SEM-baseado em covariâncias, que é aplicável ao PLS-SEM: se a modificação feita no modelo não for pequena (menos de 20% de indicadores deletados), ele deveria ser replicado em outra amostra.Legenda: AVE = average variance extracted.
CR = composite reliability.
rVL correlação entre as VL
EXEMPLO 2 – MODELO ESTRUTURAL SIMPLES
Este exemplo se baseia no anterior, no qual foi acrescentada uma variável dependente, o desempenho financeiro (Figura 6), agora há relações estruturais (hipóteses H1 a H7).
Especificação
O DLOQ e DLOQ-A contém as sete dimensões usadas no exemplo 1 e outras duas dimensões de desempenho, assim, a especificação do modelo apresentado na Figura 6 se baseia no mesmo referencial teórico (MENEZES et al., 2011).
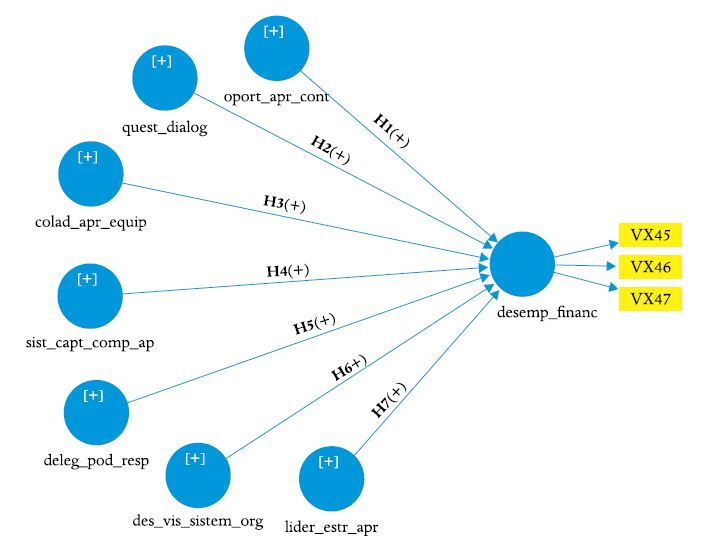
Figura 6
Modelo estrutural
Nota: Indicadores disponíveis em Menezes et al. (2011).
Estimação
No algoritmo do PLS seleciona-se a opção “path weighting scheme” (Figura 7) e do output serão utilizados os resultados: Collinearity Statistics (VIF), f Square e R square, para se formatar a tabela com os resultados do modelo estrutural (Tabela 3).
Figura 7
Esquema de ponderação no algoritmo PLS para o modelo estrutural
O algoritmo do bootstrapping é usado da mesma forma que foi usado no Exemplo 1 (Figura 4) e do output serão utilizados os resultados: Path coefficients e Path coefficients Histogram, para se formatar a Tabela 3 com os resultados do modelo estrutural.
Avaliação e relato
A avaliação do modelo deve ser feita em duas seções separadas: (i) uma para o modelo de mensuração (da mesma forma que foi feita no Exercício 1, mas não será apresentado aqui por limitação de espaço); (ii) e outra para o modelo estrutural, que é o foco deste exemplo.
Antes de iniciar a formatação dos resultados, é preciso avaliar se os histogramas do bootstrapping são unimodais (Figura 8), caso não sejam, é preciso voltar ao início e avaliar a presença de dados atípicos (outliers), indicadores com pouca variabilidade, indicadores binários etc.
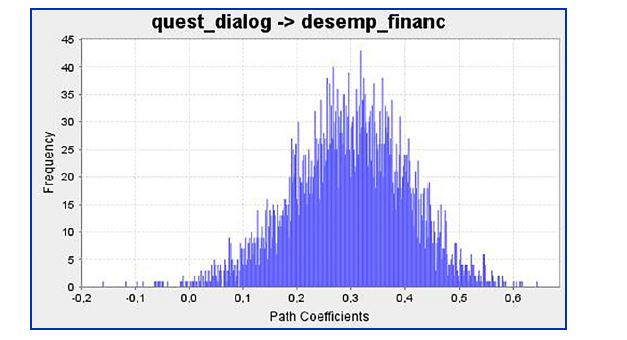
Figura 8
Histograma obtido no bootstrapping
Nota: Um histograma para cada coeficiente estrutural é apresentado no output do bootstrapping. Se este gráfico apresentar bimodalidade, é preciso verificar se há outliers ou VL mensuradas por poucos indicadores dicotômicos. Estes gráficos são apresentados no output do bootstrapping: Histograms > Path coefficients histograms
Os resultados podem ser apresentados na forma de figura ou tabela. A Figura 9 pode ser uma boa opção para fins de apresentação na forma de PPT e discussão em grupo, mas para artigo ela ocupa muito espaço e contém pouca informação (no SmartPLS 3 é possível selecionar o que deve ser apresentado nas setas e nas VL, por exemplo: cargas fatoriais, coeficientes estruturais, valor-t, valor-p, R² ou R² ajustado). A Tabela 3 é o formato recomendado para artigos, dissertações e teses.
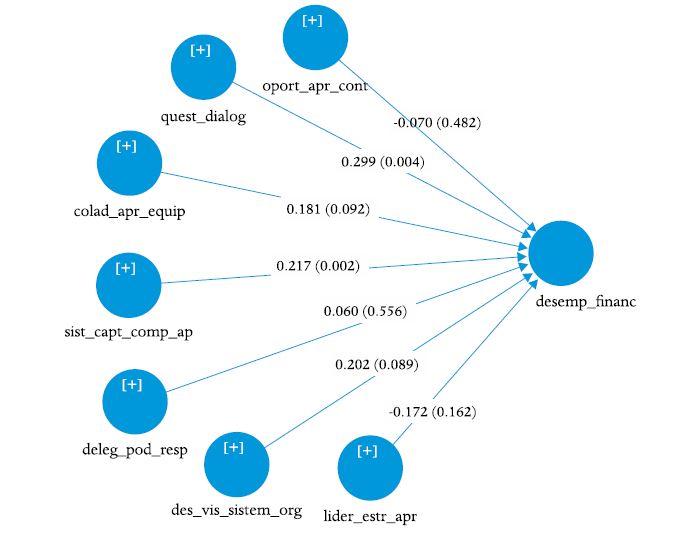
Figura 9
Resultados do modelo estrutural no bootstrapping
Nota: Valores fora dos parênteses são coeficientes estruturais padronizados (betas) e os valores dentro dos parênteses são valores-p (há opção de se apresentar o valor-t).
O SmartPLS 3 contém muitos resultados do modelo estrutural, para facilitar a apresentação deles, recomenda-se a formatação de uma tabela da seguinte maneira:
· Output Bootstraping > Final Results:
o Path coefficients > Excel format
o Colar em uma planilha Excel
o Excluir a coluna “Sample Mean (M)”
o Incluir colunas para: Hipótese, VIF, f² e R² ajustado
· Output PLS algorithm > Quality Criteria:
o Copiar os resultados para a planilha Excel (Tabela 3):
§ Collinearity Statistics (VIF) > Inner VIF Values
§ f Square
· Reordenar as linhas agrupando-as por variável endógena (desnecessário neste exemplo, porque só há uma variável endógena) e colar os valores de R² ajustado para cada variável endógena.
· Reordenar as linhas para deixar na sequência das hipóteses.
Com os resultados formatados na Tabela 3, fica mais fácil analisá-los simultaneamente, levando em conta os seguintes critérios:
· Multicolinearidade
o Se VIF > 5 considerar a exclusão de preditores ou agrupá-los em VL de segunda ordem (HAIR Jr. et al., 2016).
· Importância relativa dos preditores:
o Tamanho do efeito: f² = 0.02 = pequeno; f² = 0.15 = médio; f² = 0.35 = grande (COHEN, 1988)
o Coeficientes estruturais (como betas de regressão)
o Correlações entre as variáveis exógenas e a endógena: comparando as correlações com os coeficientes estruturais obtém-se uma avaliação mais completa da importância relativa do preditor.
· Variância explicada das variáveis endógenas
o R² = 2% = pequeno; R² = 13% = médio; R² = 26% = grande (COHEN, 1988)
Na Tabela 3 observa-se que apenas duas das sete hipóteses foram confirmadas (p<0.05) e o tamanho do efeito (f²) é pequeno em ambas as relações, ainda que a variância explicada seja grande (R² ajustado = 40.6%). A incoerência entre esses resultados pode ser explicada pela multicolinearidade, mesmo que VIF esteja abaixo de 5:
· As correlações entre os preditores e a VL endógena variam de 0.48 a 0.59 (valores são muito próximos àqueles apresentados na Tabela 4a, mais à frente), ou seja, do ponto de vista bivariado todos os preditores são importantes, já que qualquer preditor sozinho explica aproximadamente 25% da variância da VL endógena.

Nota 1: Valores-p estimados por bootstrapping com 5000 repetições.Nota 2: Para a tabela não ficar com muitas colunas e tamanho de letra (fonte) pequena, algumas simplificações podem ser feitas, por exemplo: (i) excluir a coluna VIF e incluir uma nota de rodapé relatando apenas o maior valor de VIF; (ii) excluir a coluna de valor-t e manter apenas valor-p.Nota 3: Este exemplo não tem variáveis de controle, mas se as tivesse, recomenda-se apresentar os resultados de 3 modelos: (1º) apenas com as variáveis de controle e as variáveis endógenas, (2º) modelo completo e com as variáveis de controle significantes, (3º) modelo completo e sem as variáveis de controle.Legenda: f² = tamanho do efeito de Cohen (1988), VIF = variance inflaction factor.
· Apesar da correlação entre os preditores e a variável endógena serem todas positivas e da ordem de 0.5, observa-se na Tabela 3 que o coeficiente estrutural na H7 foi não significante (p>0.05) e seu resultado negativo indica supressão, que é um dos sintomas da multicolinearidade (COHEN et al., 2003).
· Um VIF igual a 3.66 significa que 72.7% da variância de um preditor é explicada pelos demais preditores (há uma sobreposição entre eles).
· As correlações entre os preditores (Tabela 5a) varia de 0.64 a 0.77, ou seja, maiores que as correlações deles com a VL endógena.
Para resolver essa incoerência, Hair Jr. et al. (2016) recomendam eliminar preditores ou agrupá-los em uma VL de segunda ordem, o que foi feito por Menezes et al. (2011) e será desenvolvido no próximo exemplo.
EXEMPLO 3 – MODELO ESTRUTURAL COM VARIÁVEL LATENTE DE SEGUNDA ORDEM (REPETINDO INDICADORES)
Do ponto de vista empírico, observou-se nos exemplos anteriores que as sete VL do DLOQ são altamente correlacionadas, e do ponto de vista teórico as sete dimensões têm a ver com a cultura de aprendizagem, portanto, usá-la como a causa comum entre as sete dimensões faz sentido pelos dois pontos de vista.
Especificação
Uma variável latente de segunda ordem é mensurada por duas ou mais VL de primeira ordem e é assim que ela é modelada quando se usa SEM baseado em covariâncias, mas no caso do PLS-SEM, se a VL não tiver variáveis mensuradas conectadas a ela o algoritmo nem inicia as iterações. Nestes casos, uma das opções é reutilizar os indicadores das VL de primeira ordem na VL de segunda ordem.
Esta opção é recomendada quando a quantidade de indicadores por VL é aproximadamente igual (neste exemplo, as sete VL de primeira ordem possuem três indicadores cada), caso contrário, a VL que tiver mais indicadores resultará em carga fatorial maior simplesmente porque tem mais indicadores repetidos na VL de segunda ordem.
As relações entre a VL de segunda ordem e suas dimensões (VL de primeira ordem) devem ser interpretadas e usadas como cargas fatoriais (não são hipóteses). Neste modelo, a única hipótese (relação estrutural) está entre a cultura de aprendizagem e o desempenho (Figura 10).

Figura 10
Especificação do modelo estrutural no SmartPLS 3
Nota 1: Cultura de Aprendizagem é uma VL de segunda ordem. Nota 2: A VL Cultura de Aprendizagem contém 21 indicadores (os indicadores das 7 VL foram repetidos nela), mas foram escondidos (hide indicators) para facilitar a visualização do modelo.
Estimação
A estimação (PLS algorithm e bootstrapping) é feita exatamente como foi feita no exemplo 2, mas um cuidado que deve ser tomado é que as relações entre a VL de segunda ordem e suas VL de primeira ordem estarão no output de relações estruturais (path coefficients), por isso, é necessário um trabalho de formatação (separar esses resultados), bem como calcular a AVE (average variance extracted) e CR (composite reliability) a mão, porque o SmartPLS 3 faz esses cálculos com os indicadores que foram repetidos na VL de segunda ordem (Figura 11).
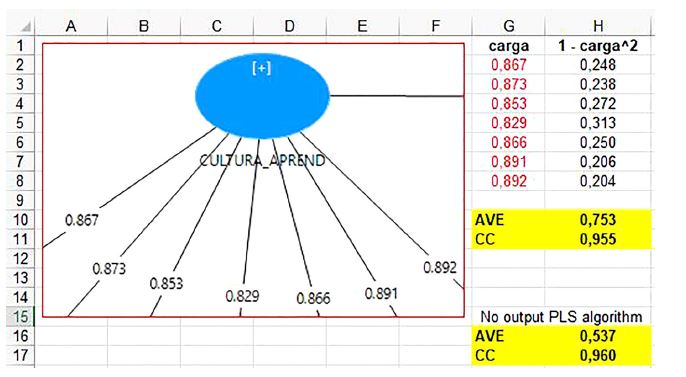
Figura 11
Cálculo da AVE e CR para VL de segunda ordem em planilha Excel
Nota: Para calcular a AVE = H10 = SOMAQUAD(G2:G8)/7 Para calcular a CR = SOMA(G2:G8)^2/(SOMA(G2:G8)^2+SOMA(H2:H8))
Avaliação e relato
Para modelos com VL de segunda ordem, recomenda-se apresentar os resultados em três etapas: (i) modelo de mensuração das VL de primeira ordem (como foi feito nas Tabelas 1 e 2), (ii) modelo de mensuração das VL que estão no modelo estrutural (a seguir, na Tabela 4), (iii) modelo estrutural como foi feito na Tabela 3 (a seguir, na Tabela 5).
A formatação das tabelas é feita da mesma forma que foi feita nos exemplos anteriores, mas agora tem um passo a mais, que é explicado a seguir:
· Output PLS algorithm > Quality Criteria:
o Discriminant validity > Fornell-Larcker Criterion > Excel format
o Colar em pasta do Excel e incluir os valores de AVE e CR como foi feito nos exemplos anteriores, passar as variáveis endógenas para o final da tabela (última linha e coluna à direita).
o Copiar e colar essa tabela em outra pasta do Excel
o Na primeira tabela: deletar as VL de segunda ordem
o Na segunda tabela: deletar as VL de primeira ordem que foram usadas para mensurar as VL de segunda ordem e corrigir os valores de AVE (da raiz quadrada da AVE na diagonal) e da CR para as VL de segunda ordem.
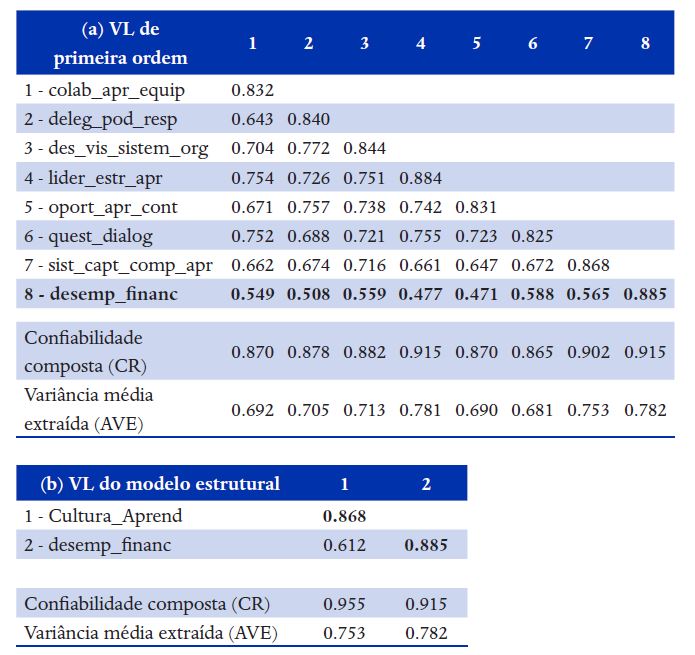
Nota 1: Os valores na diagonal são a raiz quadrada da AVE.Nota 2: Todas as correlações são significantes a 1%. Esta informação é apresentada no output do bootstrapping quando é rodada a opção “completa”.Nota 3: Cultura_Apren é uma VL de segunda ordem.
Para avaliar as cargas cruzadas (como foi feito na Tabela 2), deve-se excluir a VL de segunda ordem e os indicadores repetidos. Não apresentado aqui por limitação de espaço.
O modelo estrutural agora está bem simples, apesar de à primeira vista parecer que a inclusão de VL de segunda ordem aumentaria a complexidade do modelo. Na Tabela 5 são apresentados os resultados.

Nota: Valores-p estimados por bootstrapping com 5000 repetições.
Neste exemplo as sete dimensões do DLOQ-A foram usadas para mensurar a cultura de aprendizagem e esta variável explicou 37,4% da variância do desempenho, confirmando-se a única hipótese proposta (lembrando que, neste modelo, as demais relações são de mensuração).
Quando a quantidade de indicadores/VL é igual para todas as VL (como ocorre no presente exemplo), a abordagem de repetir indicadores pode ser usada, mas quando as quantidades de indicadores/VL nas VL de primeira ordem são muito diferentes, essa abordagem não é recomendada, porque a VL de primeira ordem que tiver mais indicadores, resultará em uma relação mais forte com a VL de segunda ordem (carga fatorial), simplesmente porque teve mais indicadores repetidos na VL de segunda ordem, e a VL que tiver menos indicadores, apresentará uma carga fatorial menor.
Quando a quantidade de indicadores/VL varia, recomenda-se a abordagem em duas etapas para modelar VL de segunda ordem, que será apresentada no próximo exemplo.
EXEMPLO 4 – MODELO ESTRUTURAL COM VARIÁVEL LATENTE DE SEGUNDA ORDEM (DOIS PASSOS)
Esta opção deve ser a escolhida para modelar VL de segunda ordem quando a quantidade de indicadores por VL é muito diferente (nas VL de primeira ordem). É preciso obter os escores fatoriais das VL de primeira ordem, salvar esses escores no conjunto de dados original, importá-lo para o SmartPLS 3 e modelar a VL de segunda ordem como se fosse uma VL de primeira ordem, usando esses escores para a sua mensuração.
Especificação
Para este exemplo, foi rodado o modelo do exemplo 1 e os escores fatoriais foram copiados para o conjunto de dados original. Estes escores estão no Output PLS algorithm:
· Final results > Latent variable > Latent variable
Outras possibilidades para se gerar os escores fatoriais de cada VL de primeira ordem são:
· Rodar uma análise de componentes principais (ACP) para cada VL, avaliar se os indicadores estão com cargas adequadas e devem ser mantidos no modelo, gerar o escore fatorial na própria ACP;
· Usar um método mais antigo (summated rating scales), que consiste em gerar o escore para cada VL como a média de seus indicadores. Uma análise prévia do alfa de Cronbach ou ACP para cada VL pode ajudar a decidir pela manutenção de todos os indicadores ou não, na obtenção dos escores. Este procedimento também pode ser relacionado à literatura sobre “parcelas de itens” ou “item parcels” (LITTLE et al., 2002).
Às vezes na ação de copiar e colar pode ocorrer problemas de formatação (formatos do Reino Unido e dos EUA usa-se ponto para as decimais e no formato brasileiro e da maioria dos países da Europa se usa vírgula), se isso ocorrer, uma solução simples é copiar do SmartPLS 3 (clique no “Excel Format”) e colar em um bloco de notas, substituir os pontos por vírgula e depois copiar/colar para o Excel. Salvar como .csv (caractere separado por vírgulas) e importar para o SmartPLS 3: clique-direito no nome do projeto > import data file > ... > clique-direito no nome do conjunto de dados > Select Active Data File.
Outra opção é usar os recursos do Excel para a importação de dados: Colar > Usar Assistente de importação de texto > Meus dados possuem cabeçalho > Avançar > Selecionar Tabulação > Avançar > Avançado > Separador decimal = ponto; separador de milhar = vírgula > Ok > Concluir.
Comparando a Figura 12 com a Figura 10 observa-se que o modelo estrutural é o mesmo, apenas a mensuração da VL de segunda ordem está diferente.
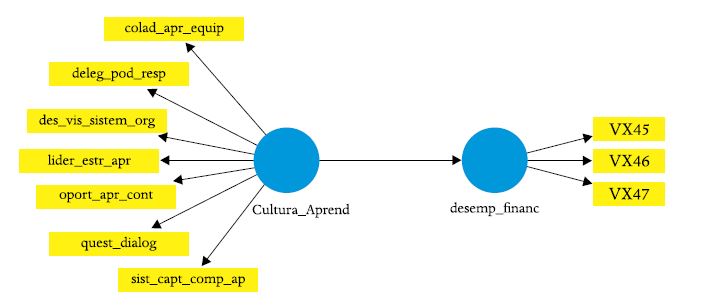
Figura 12
Modelo estrutural com VL de segunda ordem modelada em duas etapas
Nota 1: Cultura de Aprendizagem é uma VL de segunda ordem. Nota 2: Os indicadores da VL cultura de aprendizagem são escores fatorais salvos na primeira etapa, na análise de componentes confirmatória.
Estimação
Neste ponto não há novidades, a estimação (PLS algorithm e bootstrapping) foi exatamente igual ao exemplo 2.
Avaliação e relato
Assim como no exemplo 2, os resultados foram formatados em duas tabelas para o modelo de mensuração (Tabela 6a e 6b) e uma tabela para o modelo estrutural (Tabela 7), que são apresentadas a seguir.
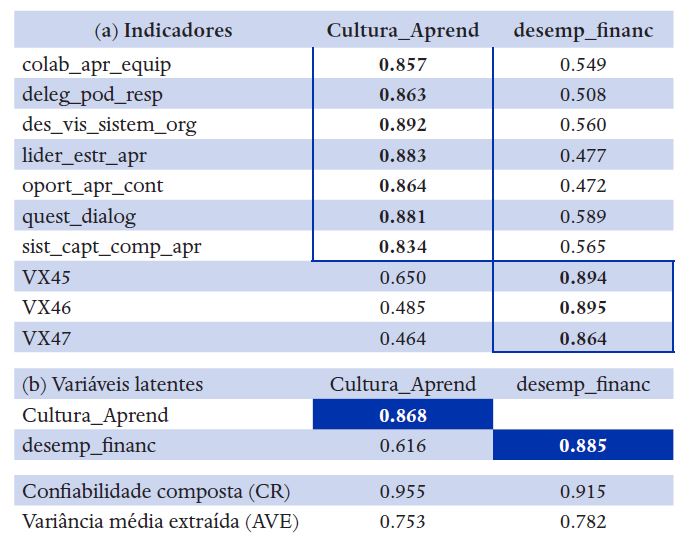
Nota: Painel (a) = matriz de cargas cruzadas
Painel (b) = matriz de correlações entre as VL, com a raiz quadrada da AVE na diagonal.
| Relação estrutural | f² | Coeficiente estrutural | Erro padrão | Valor- t | Valor- p | R² |
| Cultura_Aprend -> desemp_financ | 0.613 | 0.616 | 0.044 | 13.959 | 0.000 | 0.380 |
Como todas as VL de primeira ordem tinham três indicadores (quantidade igual de indicador / VL), a abordagem de repetir os indicadores das VL de primeira ordem na VL de segunda ordem e a abordagem em duas etapas apresentaram resultados idênticos para efeitos práticos (R² igual a 0.374 e 0.380, respectivamente).
Ambas abordagens resolveram o problema de multicolinearidade encontrado no exemplo 2, sendo necessária uma modificação no modelo conceitual: definir a VL de segunda ordem e revisar a hipótese (relação estrutural).
Este procedimento (agrupar variáveis multicolineares) é recomendado por Hair Jr. et al. (2016, posição 4541), mas também usa a mesma lógica do que é conhecido como principal components regression (COHEN et al., 2003, p.428).
EXEMPLO 5 – MODELO ESTRUTURAL COM MEDIAÇÃO (EFEITOS DIRETOS, INDIRETOS E TOTAIS)
Os exemplos 5 e 6 são baseados no modelo ECSI (European Customer Satisfaction Index), cujos dados e projeto estão disponíveis no site do SmartPLS 3 (RINGLE et al., 2015) na aba “Resources > SmartPLS Project Examples”. Este exemplo já é um “clássico”, porque desde 2005 tem sido usado para o ensino do PLS-SEM e tem como referência o artigo de Tenenhaus et al. (2005).
Especificação
Este exemplo não será modificado em nada (Figura 13), apenas será apresentada a forma com que o software estima os efeitos indiretos e totais, de modo que seja possível se avaliar se a mediação é total (quando o efeito indireto é significante, mas o direto é nulo) ou parcial (quando o efeito indireto e direto são significantes).
Estimação
A rigor, deveria ser avaliado o modelo de mensuração e depois o modelo estrutural. Por limitação de espaço não será feito nenhum ajuste no modelo de mensuração (por um lado, se o objetivo é comparar o índice – escore da satisfação – de uma pesquisa para outra, é necessário que o modelo de mensuração seja o mesmo – invariância configuracional – e, por outro lado, se forem feitas as análises apresentadas no exemplo 1, serão identificados sérios problemas de validade convergente e discriminante, verifique você mesmo).
Para efeito deste exemplo, considere a seguinte situação: o efeito direto (path coefficient) entre Expectativa e Satisfação não é significante (0.063, p>0.20), então, Expectativa não influencia a Satisfação?
Avaliação e relato
Para avaliar se há mediação, e se ela é total ou parcial, avalia-se os efeitos diretos, indiretos e totais, como é apresentado no Quadro 2.
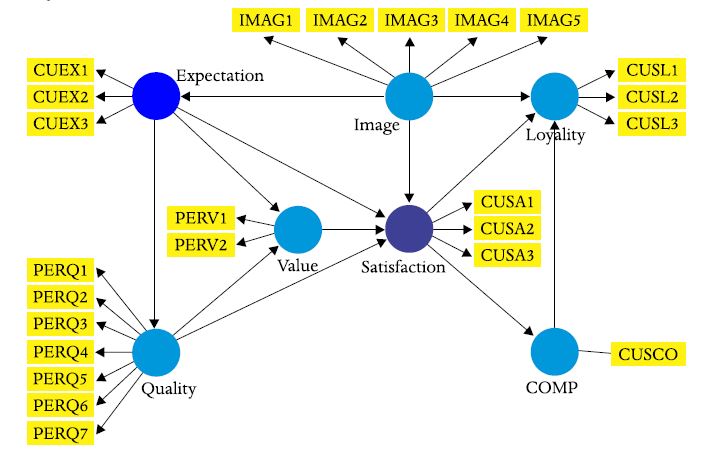
Figura 13
Modelo ECSI – efeito direto e indiretos da Expectativa na Satisfação
Fonte: Ringle et al. (2015).

Notas da figura 13:

A formatação da Tabela 8 é feita a partir dos resultados do bootstrap, destacando-se que a quantidade de resultados (efeitos indiretos) é grande, por isso, o trabalho é mais de selecionar aqueles que interessam:
· Output Bootstraping > Final Results:
o Path coefficients > Excel format
o Colar em uma planilha Excel
o Specific indirect effects > Excel format
o Colar em uma planilha Excel
o Total effects > Excel format
o Colar em uma planilha Excel
o Copiar/colar as linhas que interessam
o Excluir a coluna “Sample Mean (M)”
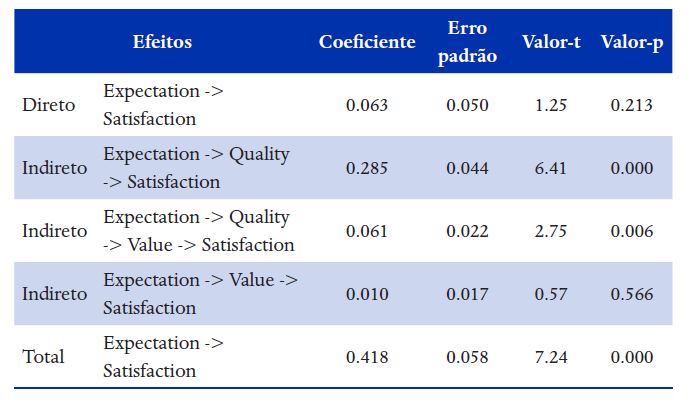
Nota 1: No output do bootstrap a opção Specific indirect effects apresenta os resultados de todos os efeitos indiretos, como está nesta tabela. A opção Total indirect effects é menos detalhada e apresenta apenas o efeito indireto total (0.355, p<0.001).
Respondendo à questão colocada no início da seção 5, a Expectativa não tem um efeito direto na Satisfação, mas tem um efeito indireto (0.355, p<0.001), ou seja, é uma mediação total, por isso, ela é importante para promover a satisfação.
Os resultados podem ser complementados com a Figura 14, que relaciona os efeitos totais (importância) com o desempenho (escores médios em escala de 0 a 100). Aqui fica explícito que a expectativa, apesar de não ter efeito direto significante, ela tem um efeito total importante, e só fica atrás da qualidade percebida em termos de prioridade, que pode ser melhorada de um escore 73 até 100.
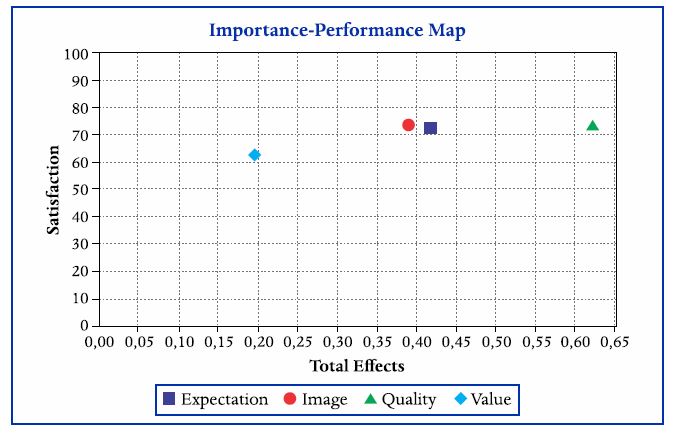
Figura 14
Mapa importância-desempenho (ou Mapa de prioridade)
Nota: Para obter esse gráfico: Calculate > Importance-Performance... > Selecionar a VL Satisfação > Start calculation. As coordenadas de cada ponto podem ser obtidas no output em: Final results > Performance/Index.
EXEMPLO 6 – MODELO ESTRUTURAL COM MODERAÇÃO DE VARIÁVEL CONTÍNUA
Uma variável moderadora fortalece ou enfraquece a relação entre uma variável independente (VI ou preditora) e uma variável dependente (VD ou critério ou endógena). Esta variável moderadora pode ser contínua (pelo menos, intervalar ou considerada como tal) ou categórica. Para o primeiro caso, siga este exemplo (Figura 15), e para o caso de moderadora categórica siga o exemplo 7 (MGA – Multi-group analysis).
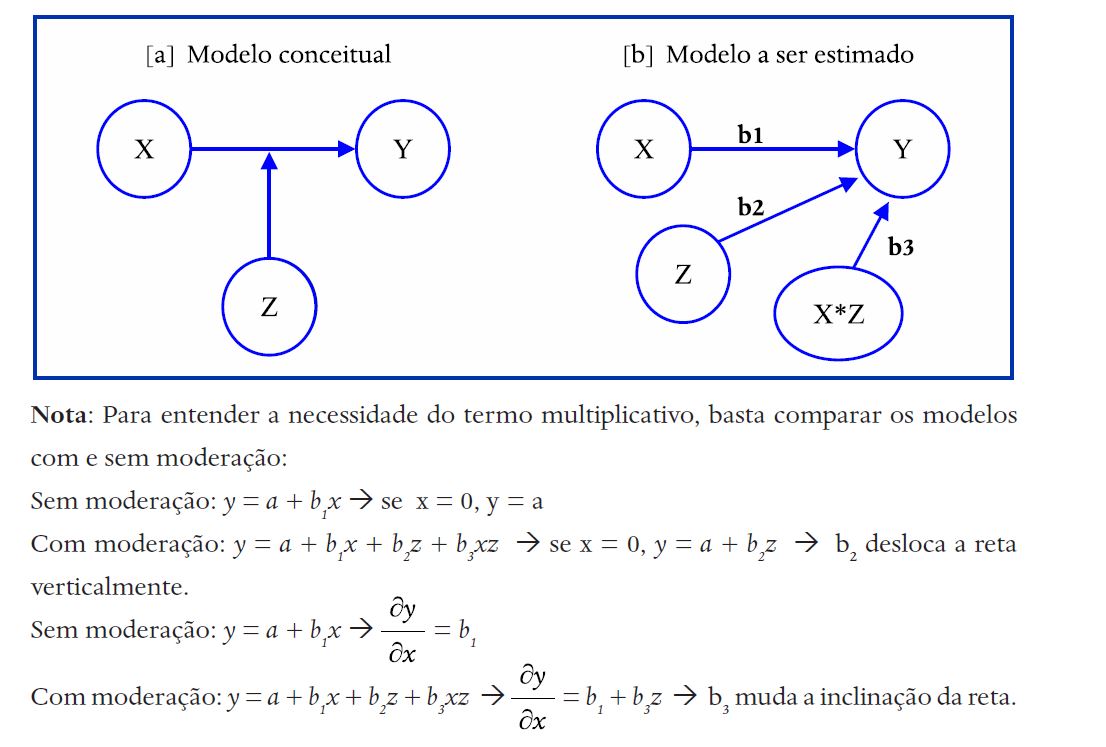
Figura 15
Representação de variável moderadora
Especificação
A relação entre a VI e a VD pode ser positiva ou negativa e a variável moderadora pode enfraquecer ou fortalecer esta relação, Gardner et al. (2017) apresentam vários exemplos que podem ser úteis para se entender como uma variável moderadora seria justificável em um modelo.
O modelo a ser usado neste exemplo é o mesmo ECSI, incluindo um efeito moderador da Imagem na relação entre a Satisfação e a Lealdade, como foi feito na apresentação do software XLSTAT-PLSPM (2017) e é apresentado na Figura 16.
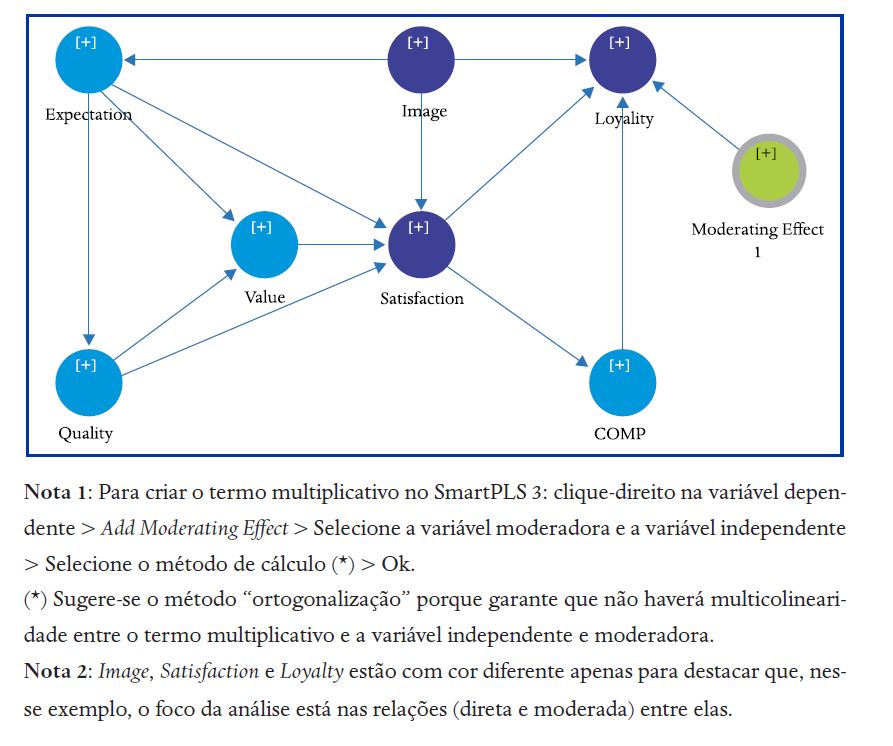
Figura 16
Efeito moderador da Imagem na relação Satisfação-Lealdade
Estimação
A estimação deste modelo é realizada da maneira usual, como é feita em um modelo qualquer e como foi apresentado no modelo do exemplo 5. Ao especificar o termo multiplicativo na etapa anterior, o SmartPLS 3 gera um gráfico (simple slope analysis), que contém três linhas: uma para o valor médio da moderadora e outras duas com um desvio padrão acima e abaixo da média.
Para a v.2 do SmartPLS, ou outros softwares que não têm esse gráfico, é possível gerá-lo a partir dos resultados do bootstrap (coeficientes estruturais) e das planilhas desenvolvidas por Dawson (2014), que são recomendadas por Hair Jr. et al. (2016).
Avaliação e relato
O resultado do efeito moderador é incluído na tabela de avaliação do modelo estrutural, como foi feito nas Tabelas 3, 5 e 7. Na Tabela 9 foi apresentado apenas o resultado do efeito moderador por limitação de espaço.
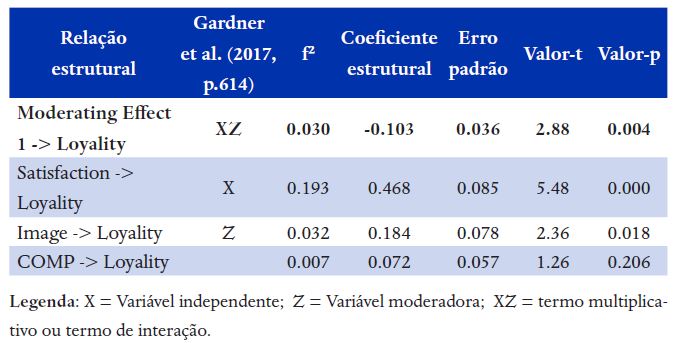
Legenda X = Variável independente; Z = Variável moderadora; XZ = termo multiplicativo ou termo de interação.Nota 1: Gardner et al. (2017, p.614) auxiliam na interpretação dos resultados da moderação a partir dos sinais de X, Z e XZ.Nota 2: Tabela incompleta, só inclui as relações estruturais com a lealdade (R² ajustado = 46,4%), que é o foco deste exemplo.
Como foi citado no exemplo 2, para avaliar o tamanho do efeito dos coeficientes estruturais se usa a classificação de Cohen (1988): f² = 0.02 = pequeno; f² = 0.15 = médio; f² = 0.35 = grande. Entretanto, quando se trata de efeito moderador, Hair Jr. et al. (2017) sugerem a classificação de Kenny (2015): f² = 0.005 = pequeno; f² = 0.010 = médio; f² = 0.025 = grande. Portanto, o efeito moderador neste exemplo é significante e grande.
Outro resultado importante do efeito moderador é a figura 17a:
· a linha superior (verde) representa a relação entre satisfação-lealdade quando a imagem tem valores altos (1 desvio padrão acima da média). Para altos valores de imagem a relação satisfação-lealdade é mais fraca. Nos termos de Gardner et al. (2017, p.614): “Enfraquecimento: Z modera o relacionamento positivo (negativo) entre X e Y, de modo que o relacionamento se torna mais fraco à medida que Z aumenta.”
· a linha inferior (azul) representa a relação entre satisfação-lealdade quando a imagem tem valores baixos (1 desvio padrão abaixo da média). Para baixos valores de imagem a relação satisfação-lealdade é mais forte.
· A figura 17b contém o mesmo gráfico da figura 17a, mas ela pode ser mais adequada do que a primeira no caso de artigos em Preto & Branco. Para gerar a figura 17b, os coeficientes estruturais da Tabela 9 foram inseridos na planilha “two-way interactions – standardized” de Dawson (2014).
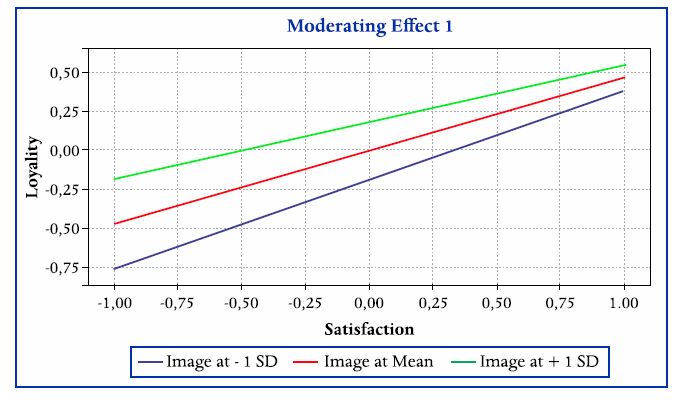
Figura 17a
Gráfico do efeito moderador da Imagem na relação Satisfação-Lealdade
(a) Gráfico gerado no SmartPLS 3 quando se inclui uma variável moderadora
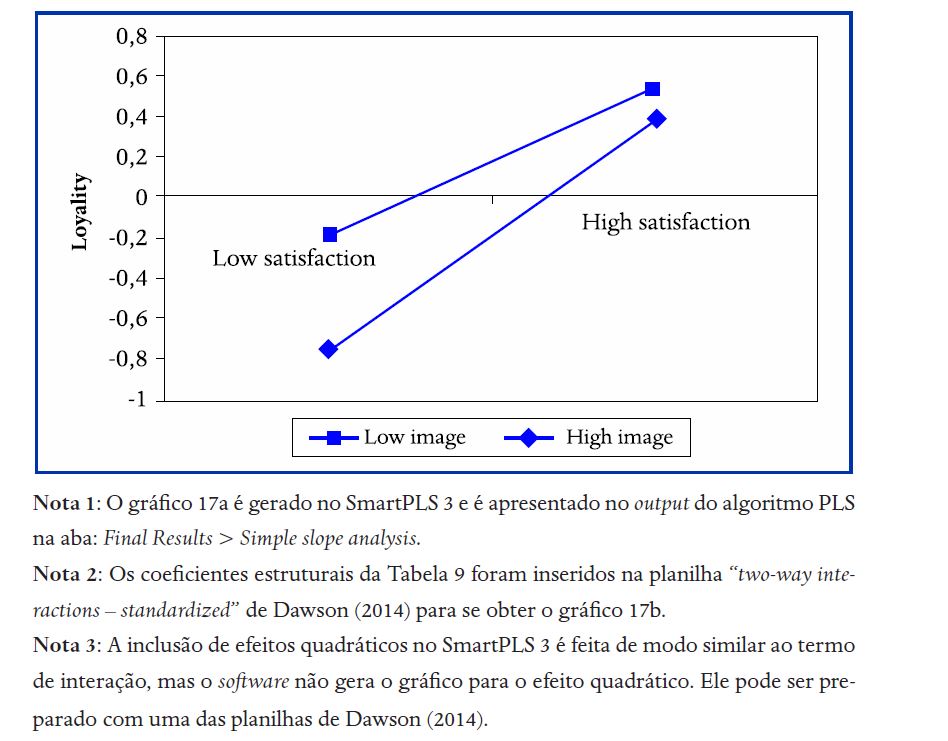
Figura 17b
(b) Gráfico gerado com os coeficientes estruturais da Tabela 9 e planilha de Dawson (2014)
EXEMPLO 7 – MODELO ESTRUTURAL COM MODERAÇÃO DE VARIÁVEL CATEGÓRICA – MGA
Este tipo de análise é usado quando se tem a priori uma variável que será usada para definir os grupos a serem comparados (heterogeneidade observada), por exemplo: gênero, país, setor etc.
O modelo usado neste exemplo continua sendo o ECSI, mas os dados usados são aqueles disponíveis no pacote plspm do software R (SANCHEZ, 2013). São de uma pesquisa espanhola, que inclui a variável gênero e será usada como moderadora categórica neste exemplo. Para obter os dados, instale o software R e execute o script a seguir:

Script
Especificação
O modelo estrutural é igual ao da Figura 13, com exceção de que não há a VL Complaint, e agora a variável gênero será usada como moderadora categórica na análise multigrupos (MGA – multi-group analysis).
Neste tipo de análise o objetivo pode ser: (i) mostrar que o modelo de mensuração é invariante (ou equivalente) entre os grupos, no sentido de que o mesmo construto é medido igualmente em diferentes grupos (MILLSAP, 2011), (ii) avaliar se as relações entre os construtos (coeficientes estruturais) variam dependendo do grupo (HAIR JR. et al, 2016).
Estimação
A modelagem é feita no SmartPLS 3 como as anteriores, mas deve se acrescentar a informação de qual variável será usada como moderadora categórica, que definirá os grupos a serem comparados. Para isto, basta fazer como está na Figura 18: duplo-clique no ícone do conjunto de dados > Generate data groups > Selecionar a variável “gender” > Ok.
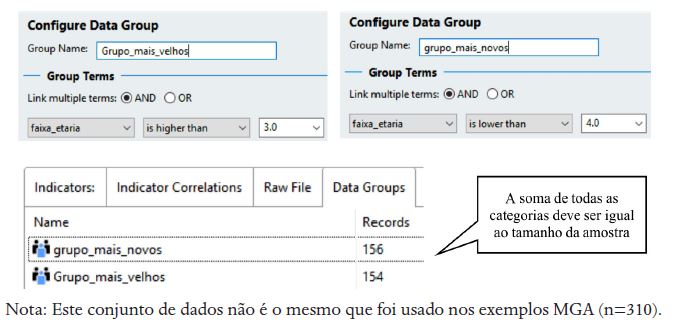
Figura 19
Dicotomização de variável numérica para uso na MGA
Depois que os grupos estão definidos, é possível executar a MGA de duas formas, sendo que a Permutação é a mais recomendada porque tem um teste (MICOM – measurement invariance of composite models) para avaliar a invariância do modelo de mensuração:
1. MGA: Calculate > Multi-group Analysis (MGA) > Selecionar um gênero em cada grupo > Start calculation.
2. Permutação: Calculate > Permutation > Selecionar um gênero em cada grupo > Start calculation.
Avaliação e relato
Em primeiro lugar é preciso avaliar se o modelo de mensuração é invariante de um grupo para outro. A invariância pode ser avaliada desde uma forma mais fraca (invariância configuracional, que significa que os mesmos indicadores são usados para medir os mesmos construtos em grupos diferentes), até algo mais restrito como os indicadores apresentarem as mesmas cargas fatoriais em grupos diferentes etc. Para aprofundamento sobre este tema sugere-se Henseler et al. (2016) para modelos estimados por PLS-SEM e Little (2013) para modelos estimados por SEM baseado em covariâncias.
Neste exemplo, a invariância configuracional é garantida desde o início (passo 1), pois os dois grupos e suas diferenças são estimadas em uma mesma rodada. No passo 2 é avaliada a invariância composicional (MICOM) que, é aceita se a correlação entre os escores para cada construto é igual a 1, quando se usa os pesos fatoriais (outer weights) do grupo 1 e do grupo 2.
Na Figura 20 observa-se que a invariância composicional não foi obtida para o construto Valor, e uma das opções a seguir deve ser escolhida:
· Se a diferença se deve a poucos indicadores, eles poderiam ser excluídos do modelo;
· Definir pesos a priori para cada indicador (valores fixos);
· Excluir o construto inteiro do modelo, com alguma justificativa/explicação a posteriori;
· Não continuar a comparação e analisar os grupos separadamente.
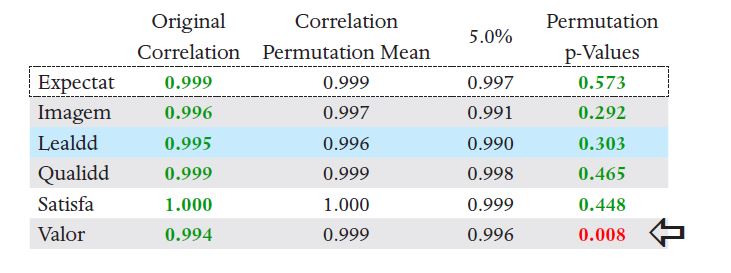
Figura 20
Resultados MICOM
Nota: Este resultado é apresentado no output da Permutação > Quality criteria > MICOM
Para avaliar os indicadores de cada construto no output da Permutação (Final results > outer loadings e outer weights) observa-se as seguintes diferenças significantes entre os grupos:
· Carga fatorial: indicador val3 apresentou uma diferença igual a 0.306 (p=0.002)
· Peso fatorial: indicador val3 apresentou uma diferença igual a 0.091 (p=0.013) e val1 foi igual a 0.115 (p=0.004).
A partir desses resultados, foi decidido excluir o indicador val3 e rodar a Permutação novamente, o que resultou na aceitação da invariância composicional para todos os construtos (configuracional + composicional = invariância parcial), o que permite a comparação dos coeficientes estruturais (no passo 3 do MICOM são comparadas as médias e variâncias para estabelecer a invariância total).
Concluindo a análise, observa-se na Figura 21 dois coeficientes estruturais que foram diferentes (Imagem à Lealdade; Satisfação à Lealdade). A análise MGA pode complementar os resultados da Permutação porque apresenta os coeficientes e valores-p para os dois grupos.
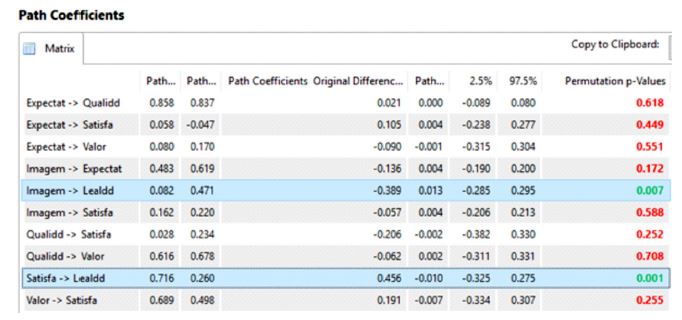
Figura 21
Resultados da Permutação (diferença dos coeficientes estruturais)
Nota: Este resultado é apresentado no output da Permutação > Final Results > Path coefficients.
Se houver mais de dois grupos para comparar, será necessário se fazer comparações duas a duas. Neste caso, a correção de Bonferroni é indicada, por exemplo: se há três grupos a serem comparados (A-B-C), serão três comparações (AB, AC, BC), por isso, os valores-p deverão ser multiplicados por 3 (ou o nível de significância – α – deveria ser dividido por 3, por exemplo 0.05/3 = 0.0167) para se afirmar que a diferença é significante a 5%. Para quatro grupos serão seis comparações (AB, AC, AD, BC, BD, CD), por isso, os valores-p deverão ser multiplicados por 6 ou α = 0.05/6 = 0.00833, para se afirmar que a diferença é significante a 5% (HAIR JR. et al, 2016).
MAIS RECOMENDAÇÃO DO QUE CONCLUSÃO
O artigo apresentado não tem um “fechamento” ou um conjunto de conclusões, porque teve uma base de apresentação de técnicas estatísticas, formando assim uma tentativa de se criar um conjunto de orientações para o uso da técnica multivariada PLS-SEM em outros contextos e situações diferentes daquelas mais usuais.
A crescente utilização do PLS-SEM, provavelmente, tem como principais motivos os tipos de pesquisas que são realizadas nas áreas de ciências humanas, sociais e do comportamento, isto é, são dados provenientes de escalas de atitude ou do tipo de Likert (em muitas vezes) e tais escalas apresentam dados que raríssimas vezes são aderentes à distribuição normal multivariada; apresentam modelos sem bases teóricas muito sólidas ou “sedimentadas”, pois nas áreas do saber indicadas os problemas são mais complexos e difíceis de estruturação.
Assim, a maior “plasticidade” nos pressupostos que sustentam a técnica estatística aqui exposta permite a inclusão de uma enorme gama de modelos e de variações destes que atendem melhor as necessidades das áreas indicadas.
Também, às vezes há debates e certa polêmica por se trabalhar com amostras pequenas e na introdução já foi acrescentada a advertência para não se usar o PLS-SEM com a única justificativa de que a amostra é pequena. Mas qual o problema de se usar uma amostra pequena se os efeitos encontrados foram significantes? Resumidamente:
· Se a amostra é pequena, resultará em maior variação nos resultados;
· Ao eliminar indicadores com cargas baixas, pode ser que os outros (indicadores), que estão com cargas altas apresentem esses valores apenas pelo motivo da amostra ser pequena, isto é, se a amostra fosse grande, a variação seria menor e se observaria que as cargas não são tão altas assim. Essa discussão tem sido feita como overfitting e chance capitalization;
· Por isso, Hair Jr. et al. (2010) sugerem o uso de uma nova amostra se mais de 20% dos indicadores forem excluídos.
· Por fim, entende-se que este artigo foi uma tentativa de complementar e avançar em relação à publicação de Ringle et al. (2014a; 2014b), mas o aprendizado é um trabalho-em-processo, por isso, foram preparados alguns vídeos para os exemplos apresentados neste artigo e estão disponíveis no Canal de YouTube (https://bit.ly/2F7kgud), de modo que os interessados poderão enviar dúvidas e sugestões no próprio Canal.
Referências
ANDERSON, J. C.; GERBING, D. W. Structural equation modeling in practice: A review and recommended two-step approach. Psychological Bulletin, v.103, n.3, p.411-423, 1988.
BIDO, D. S.; SILVA, D. Dataset to run examples in SmartPLS 3 (teaching and learning). Mendeley Data. 2019. Disponível em: .
BIDO, D. S.; SILVA, D.; SOUZA, C. A.; GODOY, A. S. Mensuração com indicadores formativos nas pesquisas em administração de empresas: como lidar com a multicolinearidade entre eles? Administração: Ensino e Pesquisa, v. 11, n. 2, p. 245-269, 2010.
COHEN, J. Statistical Power Analysis for the Behavioral Sciences. 2. ed. New York: Psychology Press, 1988.
COHEN, J.; COHEN, P.; WEST, S. G.; AIKEN, L. S. Applied multiple regression/correlation analysis for the behavioral sciences. 3. ed. New Jersey: Lawrence Erlbaum Associates, Publishers, 2003.
DAWSON, J. F. Moderation in Management Research: What, Why, When, and How. Journal of Business and Psychology, v. 29, n. 1, p. 1–19, 2014. [planilhas Excel disponíveis em: http://www.jeremydawson.co.uk/slopes.htm]
DEVELLIS, R. F. Scale Development: theory and applications. 4. ed. Thousand Oaks: Sage Publications, Inc., 2016.
GARDNER, R. G.; HARRIS, T. B.; LI, N.; KIRKMAN, B. L.; MATHIEU, J. E. Understanding “It Depends” in Organizational Research: a theory-based taxonomy, review, and future research agenda concerning interactive and quadratic relationships. Organizational Research Methods, v.20, n.4, p.610–638, 2017.
GUIDE, V. D. R.; KETOKIVI, M. Notes from the Editors: redefining some methodological criteria for the journal. Journal of Operations Management, v.37, p. v–x, 2015.
HAIR JR., J. F.; BLACK, W. C.; BABIN, B. J.; ANDERSON, R. E. Multivariate Data Analysis. 7. ed. Upper Saddle River, NJ: Prentice Hall, 2010.
HAIR JR., J. F.; HULT, G. T. M.; RINGLE, C. M.; SARSTEDT, M. A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM). 2. ed. Thousand Oaks, CA: Sage Publications, Inc., 2016. [e-book]
HAIR JR., J. F.; SARSTEDT, M.; RINGLE, C. M.; GUDERGAN, S. P. Advanced Issues in Partial Least Squares Structural Equation Modeling. Thousand Oaks, CA: SAGE Publications, Inc, 2017. [e-book]
HENSELER, J.; RINGLE, C. M.; SARSTEDT, M. Testing measurement invariance of composites using partial least squares. International Marketing Review, v. 33, n. 3, p. 405-431, 2016.
KENNY, D. A. Moderation. 2015. Disponível em: .
LITTLE, T. D. Longitudinal Structural Equation Modeling. New York: The Guilford Press, 2013.
LITTLE, T. D.; CUNNINGHAM, W. A.; SHAHAR, G.; WIDAMAN, K. F. To parcel or not to parcel: exploring the question, weighing the merits. Structural Equation Modeling, v. 9, n. 2, p. 151-173, 2002.
LITTLE, T. D.; LINDENBERGER, U.; NESSELROADE, J. R. On selecting indicators for multivariate measurement and modeling with latent variables: When “good” indicators are bad and “bad” indicators are good. Psychological Methods, v. 4, n. 2, p. 192–211, 1999.
MACKENZIE, S. B.; PODSAKOFF, P. M. Common method bias in marketing: causes , mechanisms , and procedural remedies. Journal of Retailing, v. 88, n. 4, p. 542-555, 2012.
MENEZES, E. A. C.; GUIMARÃES, T. A.; BIDO, D. S. Dimensões da aprendizagem em organizações: validação do dimensions of the learning organization questionnaire (DLOQ) no contexto brasileiro. Revista de Administração Mackenzie, v. 12, n. 2, p. 4–29, 2011.
MILLSAP, R. E. Statistical Approaches to Measurement Invariance. New York: Routledge - Taylor & Francis Group, 2011.
NETEMEYER, R. G.; BEARDEN, W. O.; SHARMA, S. Scaling Procedures: issues and applications. Thousand Oaks: Sage Publications, 2003.
RINGLE, C. M.; SILVA, D.; BIDO, D. S. Modelagem de equações estruturais com utilização do SmartPLS. REMark – Revista Brasileira de Marketing, v.13, n.2, p.54–71, 2014a.
RINGLE, C. M.; SILVA, D.; BIDO, D. S. Structural equation modeling with the SmartPLS. Revista Brasileira de Marketing, v.13, n.2, p.56–73, 2014b.
RINGLE, C. M.; WENDE, S.; BECKER, J.-M. SmartPLS 3. GmbH: SmartPLS, 2015. Disponível em: .
SANCHEZ, G. PLS Path Modeling with R. Berkeley: Trowchez Editions, 2013. Disponível em: .
TENENHAUS, M.; ESPOSITO VINZI, V.; CHATELIN, Y.-M.; LAURO, C. PLS path modeling. Computational Statistics & Data Analysis, v.48, n.1, p.159–205, 2005.
XLSTAT-PLSPM. PLS Path Modeling in Excel: moderating effects. 2017. Disponível em: .
YANG, B. Identifying valid and reliable measures for dimensions of a learning culture. Advances in Developing Human Resources, v.5, n.2, p.151–162, 2003.