Artículo
Recepción: 12 Marzo 2022
Aprobación: 15 Mayo 2022
DOI: https://doi.org/10.18273/revuin.v21n3-2022002
Resumen: En los algoritmos de segmentación de imágenes mediante agrupamiento espectral, debido al tamaño de las imágenes, la carga computacional para la construcción de la matriz de similitud y la solución al problema de valores propios para la matriz laplaciana son altos. Además, la medida de similitud más utilizada es el kernel gaussiano, el cual presenta problemas con distribuciones de datos irregulares. Este trabajo propone realizar una presegmentación o diezmado mediante superpíxeles con el algoritmo Simple Linear Iterative Clustering, para disminuir el costo computacional y construir la matriz de similaridad con una medida difusa basada en el clasificador Fuzzy C-Means, que proporciona al algoritmo una mayor robustez frente a imágenes con distribuciones complejas; mediante agrupamiento espectral se determina la segmentación final. Experimentalmente, se comprobó que el enfoque propuesto obtiene segmentaciones adecuadas, buenos resultados de agrupamiento y una precisión comparable respecto a cinco algoritmos, midiendo el desempeño bajo cuatro métricas de validación.
Palabras clave: Agrupamiento espectral, medida de similitud difusa, segmentación de imágenes, superpíxeles, carga computacional, disminución de costo computacional.
Abstract: In image segmentation algorithms using spectral clustering, due to the size of the images, the computational load for the construction of the similarity matrix and the solution to the eigenvalue problem for the Laplacian matrix is high. Furthermore, the Gaussian kernel similarity measure is the most used, but it presents problems with irregular data distributions. This work proposes to perform a pre-segmentation or decimation by superpixels with the Simple Linear Iterative Clustering algorithm to reduce the computational cost, and to build the similarity matrix with a fuzzy measure based on the Fuzzy C-Means classifier, providing the algorithm a greater robustness against images with complex distributions and by spectral clustering the final segmentation is determined. Experimentally, it was found that the proposed approach obtains adequate segmentations, good clustering results and a comparable precision with respect to five algorithms; measuring performance under four determined validation metrics.
Keywords: Fuzzy similarity measure, image segmentation, spectral clustering, superpixels, computational load, computational cost.
1. Introducción
La segmentación es una etapa importante en el procesamiento de imágenes, por lo cual diferentes investigadores enfocan sus esfuerzos en el desarrollo de algoritmos que permitan una segmentación eficiente [1], [2], [3], [4]. En general, estos algoritmos se clasifican en cuatro categorías: umbralización, detección de bordes, métodos basados en regiones y agrupamiento espectral; estos últimos se han utilizado con éxito en el campo de reconocimiento de patrones [5], [6], segmentación de tumores cerebrales en imágenes de resonancia magnética [7], [8], segmentación del parénquima pulmonar a partir de imágenes de tomografía computarizada [9] y segmentación del hipotálamo [10].
En la literatura existen varios algoritmos convencionales basados en agrupamiento, enfocados en la segmentación de imágenes [11], [12]. Fuzzy C-means (FCM) es un algoritmo de agrupamiento fundamentado en la lógica difusa; su principal característica es que un píxel pertenece a varios grupos a la vez, con diferentes grados de pertenencia [13]. El principio del agrupamiento espectral se basa en la teoría de grafos, y consta de preprocesamiento, descomposición y agrupación. En la etapa de preprocesamiento, se construye la gráfica de similitud y su matriz de similaridad; en la segunda etapa, mediante la obtención de los valores propios de la matriz laplaciana, se cambia la representación de los datos a un espacio donde se simplifica el agrupamiento [14]. En la última etapa de procesamiento, se forman conjuntos no vacíos, de tal manera que la similaridad entre los datos del mismo grupo sea alta, mientras que la de los datos entre diferentes grupos es baja [15].
Los algoritmos de agrupamiento espectral son fáciles de implementar y tienen buenos resultados, pero existen algunos problemas. En primer lugar, la construcción de la matriz de similaridad, obtenida por medio de la función de kernel gaussiano, basada en la distancia euclídea [14], no puede reflejar plenamente la compleja distribución espacial del conjunto de datos [16], [17], [18]. Igualmente, hay altos costos computacionales para la construcción de la matriz de similaridad.
Como solución al primer problema, en [16] se propone un algoritmo basado en técnicas difusas, para la construcción de la matriz de similaridad (𝑆). Inicialmente, se genera la matriz de agrupamiento difuso (𝑈), donde sus elementos contienen el grado de pertenencia de cada píxel 𝑗 respecto a la partición 𝑖; estos píxeles también están caracterizados por una serie de atributos con su información de textura y ubicación espacial, que sirven como criterio para asignar el grado de pertenencia hacia un determinado grupo. Después se construye 𝑆 a partir de la matriz 𝑈, se dice que dos píxeles son similares si comparten los mismos grados de pertenencia, y dos píxeles diferentes no tendrán concordancia en sus grados de pertenencia. Finalmente, se aplican los pasos clásicos de agrupación espectral mencionados.
En [19] también se usa un algoritmo de técnicas difusas, llamado Fuzzy Edge-Weighted Centroidal Voronoi Tessellations (FEWCVT), el cual genera una función de similitud difusa combinando la información de intensidad de la imagen con la información de los límites de agrupaciones, por lo que se consiguen bordes más suaves y con mayor tolerancia al ruido. En [5] se propone un algoritmo basado en modelo de mezclas gaussianas. En primer lugar, se modela la distribución conjunta de las características de color y posición con una mezcla gaussiana, a fin de encontrar una aproximación o estimación de la imagen original. Las medidas de similaridad se realizan entre los componentes de Gauss. Finalmente, los componentes de Gauss se fusionan sobre la matriz de similaridad mediante agrupamiento espectral. Las mejores características del algoritmo son robustez frente al ruido, baja sensibilidad a la inicialización, extracción eficaz de la característica espectral y reducción del tamaño de la matriz de similaridad; sin embargo, a mayor número de componentes gaussianos utilizados en la recreación de la imagen, se incrementa la carga computacional y el sobreajuste de datos.
Respecto al segundo problema, algunos autores han iniciado trabajos con superpíxeles [20], [21], técnica que consiste en agrupar cierto número de píxeles en un super- píxel, con lo cual se reduce el costo computacional a la hora de generar la matriz de similaridad. Para esta técnica se han propuesto varios algoritmos basados en grafos y en el crecimiento del gradiente [22]. Uno de los métodos más prometedores para la generación de superpíxeles con bajo costo computacional y gran velocidad de procesamiento se presenta en [23].
En [24] se propone realizar la segmentación en dos etapas. Primero, se presegmenta la imagen por el método de Simple linear Iterative Clustering (SLIC) modificado, donde se extraen las regiones “globales” que contengan características similares. Segundo, se realiza el agrupamiento de las regiones presegmentadas en lugar de los píxeles, a partir del método de Nyström, lo cual permite extrapolar la solución de agrupamiento utilizando un pequeño número de muestras; si la imagen contiene muchos píxeles, exige más recursos computacionales y mayor tiempo de procesamiento en la solución de la matriz de similaridad.
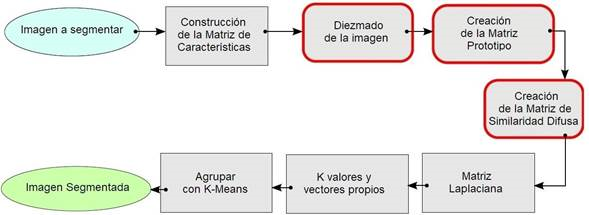
Figura 1
Comparación gráfica entre el algoritmo de agrupamiento clásico SC y el algoritmo SFSC.
Fuente: elaboración propia.
Para resolver el enorme cálculo de la matriz, en [25] se introduce un algoritmo de superpíxeles llamado Superpixel Spectral Clustering (SCS), el cual permite dividir la imagen en un conjunto conectado de regiones homogéneas [26], con la finalidad de obtener la matriz de similaridad de las regiones resultantes; el algoritmo SCS es estable y apenas se ve afectado por el número de vecinos más cercanos, además, puede lograr un mejor proceso de agrupamiento que la mayoría de los algoritmos clásicos.
Este trabajo tiene como objetivo reducir los datos por procesar y proporcionar un criterio más óptimo para la construcción de la matriz de similaridad, por lo que se propone un algoritmo híbrido que combine las bondades que ofrecen las técnicas de agrupamiento espectral, superpíxeles y agrupamiento difuso. El trabajo se organiza de la siguiente manera: en la sección 2 se abordan las etapas del algoritmo propuesto -Superpixel Fuzzy Spectral Clustering (SFSC)-; en la sección 3 se evalúa el algoritmo propuesto; y finalmente, en la sección 4 se presentan las conclusiones y trabajos futuros.
2. Metodología y materiales
El algoritmo propuesto SFSC consta de siete etapas que se indican en la figura 1; en color rojo se identifican las etapas que se incluyeron para generar la matriz de similaridad, respecto al algoritmo clásico de agrupamiento espectral.
2.1 Construcción de la matriz de características
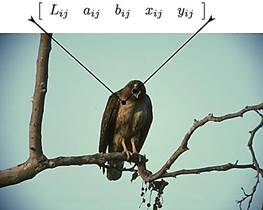
Para la construcción de la matriz de características se tienen en cuenta los componentes (𝐿, 𝑎, 𝑏) del modelo de color CIElab, al igual que la ubicación espacial (𝑥, 𝑦) del píxel, donde la luminosidad (L) varía entre 0-100, a representa las coordenada rojo/verde y b representa las coordenadas amarillo/azul; se organizan en un vector de cinco posiciones [27]. En la figura 2 se ilustra la posible representación del vector característico de un píxel ubicado en la posición (𝑖, 𝑗).
2.2 Construcción de la matriz de características
La imagen se divide en superpíxeles mediante el algoritmo SLIC [22]. Una imagen de 𝑁 píxeles se divide en 𝑘 regiones rectangulares o superpíxeles de dimensión 𝑆 × 𝑆, donde 𝑆 = √𝑁/𝑘. Cada superpíxel 𝑖 es representado en la matriz 𝐶 por un centroide definido como un vector de cinco dimensiones 𝑖 = [ 𝐿𝑖 𝑎𝑖 𝑏𝑖 𝑥𝑖 𝑦𝑖 ]. Para el caso de 20 superpíxeles (figura 3a), véase ecuación 1.
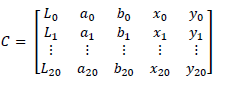 (1)
(1)Los 𝑘 centroides son trasladados a una nueva posición, la que presente el menor valor de gradiente (figura 3b); el valor de gradiente se calcula en un vecindario de 3 × 3 alrededor del centroide inicialmente definido. Esto se hace para evitar centrar un superpíxel en un borde, y reducir la posibilidad de sembrar un centroide en un píxel
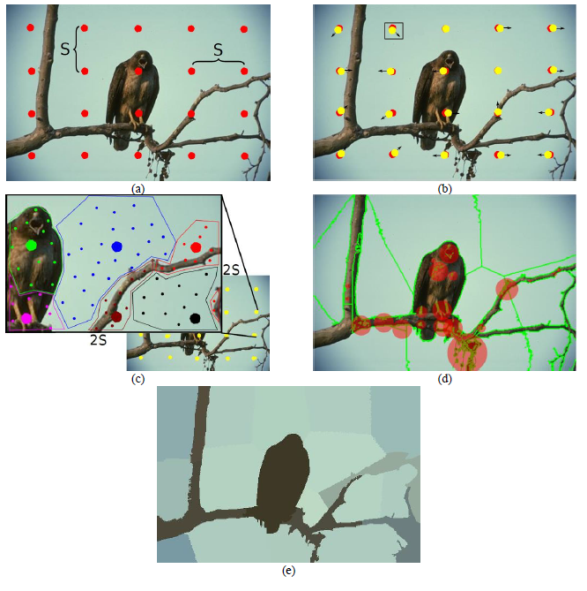
Figura 3
Segmentación con SLIC. (a) Imagen original, ubicación de los k-centroides. (b) Selección de centroides con menor valor de gradiente. (c) Asignación de píxeles al mejor centroide. (d) Penalización de regiones aisladas. (e) Imagen segmentada.
Fuente: adaptada de [29].
En la figura 3, la imagen original está representada por 154.401x103 píxeles, mientras que la imagen tratada con el algoritmo SLIC está representada por 20 superpíxeles (número elegido para el desarrollo del ejemplo), con esto se logra una reducción significativa de los datos para procesar por agrupamiento espectral.
2.3 Creación de la matriz prototipo
Se crea una matriz prototipo (𝑈) que contiene las relaciones parciales entre los 𝑘 superpíxeles y los 𝑘𝑓 grupos a segmentar; esta etapa se soporta en el algoritmo FCM [13]. Para el caso de 𝑘 superpíxeles y dos grupos, se define por medio de la ecuación 2.
 (2)
(2)Donde 𝑢𝑖𝑗 ∈ [0; 1] es el grado de pertenencia de 𝑥𝑗 superpíxel al i-ésimo grupo; se deben cumplir las siguientes dos condiciones para garantizar una partición difusa [16]:
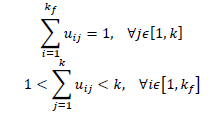 (3)
(3)Se define el vector 𝑉 = {𝑣1, 𝑣2, ⋯ , ??𝑘𝑓}, los elementos de 𝑉 serán los centroides o patrones de cada grupo; estos centroides se escogen de manera aleatoria, por lo que en primera instancia son llamados prototipos. Los agrupamientos prototipos y la matriz de partición difusa se obtienen minimizando la siguiente función objetivo:
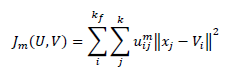 (4)
(4)Donde ‖∗‖ es la distancia euclidiana que expresa la similitud entre cualquier punto de datos medidos, y el prototipo 𝑚 es el exponente de ponderación, 1 < 𝑚 < ∞, con 𝑚 = 1; se tiene una partición clásica: a medida que 𝑚 aumenta, se disminuye la rigidez en las particiones.
2.4 Creación de la matriz de similaridad difusa
Para crear la matriz de similaridad difusa (𝑆), la imagen se representa como un grafo ponderado no dirigido, donde los nodos representan los superpíxeles, y las aristas, la similitud entre ellos [28] (figura 4).
Se debe realizar una elección adecuada de los pesos 𝑤(𝑖, 𝑗) de cada enlace (figura 4), por medio de una función de pesos difusa [16], con características robustas respecto al manejo de ruido y de datos atípicos, definida por el siguiente conjunto de reglas:
-
Si 𝑥𝑖 y 𝑥𝑗 pertenecen a la misma vecindad, entonces 𝑆𝑖??=1.
-
Si 𝑥𝑖 y 𝑥𝑗 pertenecen a 𝑡 vecindades próximas, entonces 𝑆𝑖𝑗=max [𝑢𝑙𝑗,𝑢𝑙𝑗], 1≤𝑙≤𝑡.
-
•En cualquier otro caso 0.
2.5. Creación de la matriz laplaciana normalizada
El cálculo de la matriz laplaciana normalizada (𝐿𝑛) requiere de la matriz diagonal 𝐷[𝑘 x 𝑘], calculada a partir de la suma de los elementos de las filas de la matriz 𝑆.
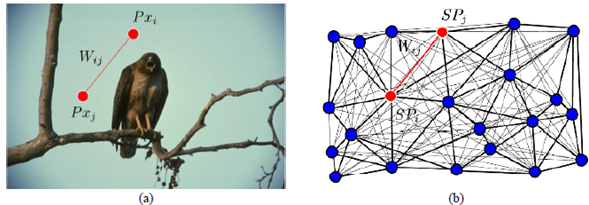
Figura 4
Construcción matriz de similaridad. (a) Imagen representada por superpíxeles. (b) Imagen representada por un grafo de similitud.
Fuente: elaboración propia.
Después de construir la matriz diagonal, se aplica la ecuación de la matriz laplaciana normalizada (véase ecuación 5).
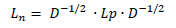 (5)
(5)Donde 𝐿𝑝=𝐷−𝑆.
2.6. Cálculo de los valores y vectores propios
A partir de la matriz 𝐿𝑛 se calculan los valores y vectores propios de esta, seguido, se extraen los 𝑘𝑝 vectores propios de menor valor. Para dos grupos, se utiliza el vector propio correspondiente al segundo valor propio más pequeño (Fiedler vector), el cual tiene información sobre cómo segmentar los superpíxeles, diferenciando los dos grupos mediante sus componentes positivos y negativos (figura 5a); este vector propio es unidimensional y contiene la misma cantidad de datos que superpíxeles en que fue presegmentada la imagen (figura 5b).
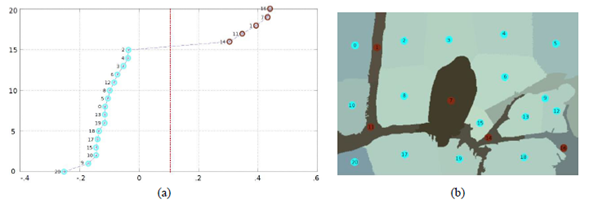
Figura 5
Segmentación en dos grupos; se toma el segundo menor vector propio. (a) Componentes y mejor corte de vector propio. (b) Segmentación de la imagen con el corte de la figura 5a.
Fuente: elaboración propia.
2.7. Etiquetado de píxeles
El etiquetado de píxeles es el último paso, donde se construye una nueva imagen remarcando las regiones con un color específico. En la figura 6 se muestra el etiquetado obtenido de la imagen agrupando los superpíxeles de acuerdo con el corte propuesto mediante el algoritmo K-means (figura 5).

Figura 6
Segmentación final. (a) Etiquetado de píxeles. (b) Superposición de imagen real con matriz de etiquetas.
Fuente: elaboración propia.
3. Resultados y discusión
Para verificar el rendimiento del algoritmo SFSC, se segmentan imágenes con diversas características, obtenidas de la base de datos Berkeley Segmentation Dataset 300 [25]. Las pruebas se realizaron en un PC Intel® Core™ i3 CPU: M-370, frecuencia: 2,40 GHz, y RAM: 2 GB. El algoritmo SFSC se implementó en C++, en Qt Creator 4.1, usando las librerías OpenCV (librería de visión artificial), Eigen y Armadillo (librerías de trabajo matricial) e Intel MKL (Math Kernel Library), Lapack, Blas y OpenMp (librerías de optimización). El número de grupos, así como el de superpíxeles en el algoritmo actual, se ingresan de forma manual; se segmenta en dos grupos utilizando 21 superpíxeles.
Los resultados obtenidos se comparan con otros algoritmos reportados en la literatura, donde las métricas de contraste son la complejidad temporal, precisión (C), recall (Lc) y la media armónica F (F). Dichos algoritmos son:
-
Shi Malik (SM) [30]: aborda la segmentación como un problema de partición de grafos, su mayor aporte es el criterio global de corte normalizado para segmentar el grafo.
-
Nyström (NW) [31]: extrapola la solución de los valores y vectores propios (espectro) utilizando un pequeño número de muestras de la matriz de características, después selecciona el vector propio de menor valor; se agrupa según el número de segmentos deseados.
-
Spectral (SC) [32]: calcula la matriz laplaciana normalizada de Jordan and Weiss, y usa los k-vectores propios de menor valor en vez de uno solo para segmentar.
-
Naotoshi (NS) [33]: construye la matriz simétrica de similaridad, resuelve el sistema generalizado de valores y vectores propios, realiza el corte del vector propio de menor valor y finalmente se realiza la bipartición recursivamente.
-
Bai Cao (NC) [34]: presegmenta la imagen por el método SLIC y después realiza el agrupamiento de las regiones presegmentadas haciendo uso del método Nyström.
Para definir las métricas de validación externa: precisión (C), recall (Lc) y media armónica F (F) [35], [36], se deben tener en cuenta los términos verdadero positivo (VP), falso positivo (FP), falsos negativos (FN) y verdadero negativo (VN), los cuales corresponden a contadores que se utilizan para contrastar los resultados de la segmentación con la imagen de referencia.
La precisión (C) hace referencia a la proporción de píxeles de un grupo estimado que pertenece a la clase de referencia [36], y está definida por la ecuación 6. C se encuentra comprendido entre 0 y 1, y aumenta a medida que disminuye el número de FP.
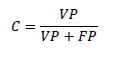 (6)
(6)El índice recall (𝐿𝑐) define la proporción de la clasificación correcta (VP) de los casos que son realmente positivos (ecuación 7); cuando se obtiene su mayor número posible (1) significa que los píxeles dentro del grupo por evaluar coinciden con las etiquetas proporcionadas por la referencia.
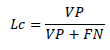 (7)
(7)La media armónica 𝐹 representa la media armónica entre 𝐶 y 𝐿𝑐, y está definida por la ecuación 8[35].
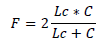 (8)
(8)3.1. Complejidad temporal
La complejidad temporal calcula el tiempo de ejecución de un algoritmo [37]. Este tiempo depende de los datos suministrados a la entrada, la calidad del código generado por el compilador, la naturaleza y rapidez de las instrucciones de máquina del procesador para que ejecute el programa y la complejidad intrínseca del algoritmo [38].
Los datos de complejidad temporal son tomados sobre cuatro imágenes, donde se presentó el peor desempeño temporal de toda la base de datos (figura 7).

Las cuatro imágenes seleccionadas para medir la complejidad temporal son redimensionadas a tamaño 𝑚×𝑚, que van desde 10×10 hasta 1000×1000 píxeles, y se segmentan en dos y tres grupos. El tiempo se determina como la media de los valores obtenidos para la segmentación del conjunto de imágenes redimensionadas (figura 8).
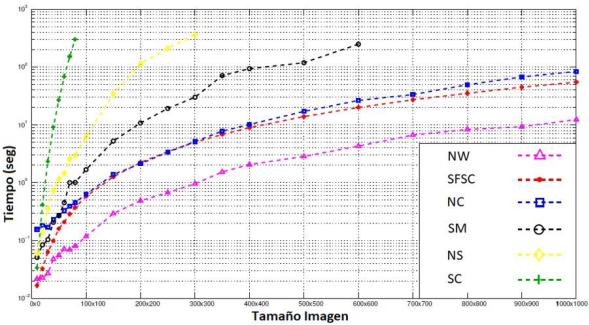
Figura 8
Gráfica de tiempo de ejecución.
Fuente: elaboración propia.
El algoritmo con mayor eficiencia es NW, esto se debe a que permite solucionar el problema de valores y vectores propios con una baja cantidad de elementos de la matriz de características; por este motivo se ahorra el cálculo de la matriz laplaciana, aunque para algunos casos sufre indeterminación en la solución del problema de valores y vectores propios. NC y SFSC tienen un rendimiento similar debido a que presentan una etapa de presegmentación basada en SLIC, la cual determina un mejor rendimiento. El bajo desempeño de los algoritmos SM, NS y SC se debe a que realizan la segmentación con todos los píxeles de la imagen (sin superpíxeles), además utilizan una estructura en árbol, que se ejecuta iterativamente hasta realizar los mejores cortes.
3.2. Evaluación externa
Para obtener los resultados de las medias externas, se tienen en cuenta los cuatro algoritmos que tuvieron mejor desempeño en la evaluación de complejidad temporal (SFSC, NW, NC y SM). Estos algoritmos se aplican a un conjunto aleatorio de 14 imágenes de la base de datos; la comparación visual se muestra en la figura 9.
En la tabla 1 se presentan los valores de C, Lc y F (los datos son multiplicados por un factor de 10−4) para los algoritmos de prueba aplicados al mismo conjunto de imágenes; se resaltan los valores de F para quien ocupa el primer lugar (azul) y quien ocupa el segundo (rojo); la selección de F como punto de análisis se debe a la falta de preferencia de una métrica sobre otra.
Medidas externas. Precisión (C), recall (Lc) y media armónica F (F)
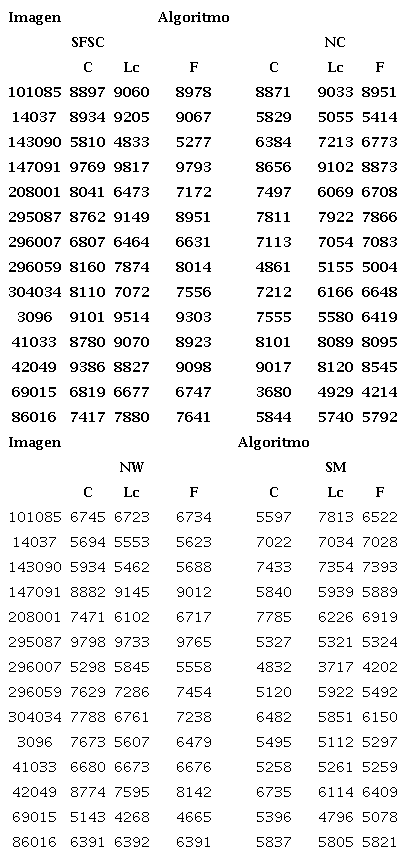
Fuente: elaboración propia.

Figura 9
Segmentación de imágenes.
Fuente: elaboración propia.
De la tabla 1, se observa que el algoritmo SFSC presenta la mayor cantidad de aciertos para la media armónica entre C y Lc. SFSC de 14 imágenes segmentó 11 como mejor segmentación y 2 como segunda mejor segmentación. La tabla 2 presenta el valor promedio de las medidas externas, calculado sobre el conjunto de 14 imágenes de la base de datos; el algoritmo SFSC logra una precisión de 0,82, recall de 0,8 y media armónica F de 0,81. El algoritmo NW encuentra segmentos pequeños para ser asignados a un segmento más lógico, a NC y SFSC se les dificulta encontrar este tipo de regiones debido a la implementación de SLIC como presegmentación.
Por otra parte, el algoritmo SM no tuvo un gran desempeño debido a una “baja” ponderación de la distancia espacial entre píxeles
Valores promedio de las medidas Precisión (C), Recall (Lc) y media armónica F (F)
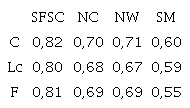
Fuente: elaboración propia.
4. Conclusiones
En este trabajo se propone un método de segmentación de imágenes a color, compuesto por tres etapas: presegmentación con SLIC; construcción de la matriz de similitud difusa 𝑆, basada en el algoritmo FCM; y, por último, segmentación con la técnica de agrupamiento espectral. El algoritmo desarrollado ha reducido considerablemente el tiempo de respuesta en comparación con el algoritmo clásico (SC), la razón principal es la introducción de la técnica de superpíxeles en la etapa de presegmentación, la cual reduce los datos que van a ser procesados por agrupamiento espectral, y en consecuencia reduce su tiempo de ejecución. Debido a que de forma clásica se trabaja con todos los píxeles de la imagen, este se ve afectado por imágenes de más de 2500 píxeles, a diferencia del algoritmo propuesto, el cual mostró un buen desempeño a la hora de segmentar imágenes conformadas por 100e3 píxeles.
La calidad de la segmentación es mejorada en el algoritmo propuesto, por el uso de la función de similaridad difusa, ya que con esta medida se tiene una separación clara entre grupos y mayor cohesión intragrupos. La ventaja de construir la matriz de similaridad bajo la función difusa se ve reflejada en el criterio de partición de la imagen, puesto que permite a la matriz laplaciana y posteriores vectores propios dar puntos de corte más visibles para el algoritmo K-means.
Como trabajos futuros, se plantea extender la caracterización de los píxeles a otras características, por ejemplo, descriptores de texturas o descriptores difusos que recojan la imprecisión en la caracterización de un píxel. Además, incluir medidas de semejanza y conectividad entre píxeles que tomen en consideración las nuevas caracterizaciones y su aplicación a la segmentación de imágenes. El número de grupos como el de superpíxeles en el algoritmo actual es ingresado de forma manual. Investigaciones posteriores se podrían enfocar en mecanismos que permitan la obtención automática y óptima de estos parámetros.
Agradecimientos
Los autores agradecen a la Universidad del Cauca por el apoyo recibido para realizar este proyecto
Referencias
D. Kaur, Y. Kaur, “Various Image Segmentation Techniques: A Review”, Int. J. Comput. Sci. Mob. Comput., vol. 3, no. 5, pp. 809-814, 2014.
N. R. Pal, S. K. Pal, “A review on image segmentation techniques”, Pattern Recognit., vol. 26, no. 9, pp. 1277-1294, 1993, doi: https://doi.org/10.1016/0031-3203(93)90135-J
F. Sultana, A. Sufian, P. Dutta, “Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey”, Knowledge-Based Systems, vol 201-202, 2020, doi: https://doi.org/10.1016/j.knosys.2020.106062
C.L. Chowdhary, D.P. Acharjya, “Segmentation and Feature Extraction in Medical Imaging: A Systematic Review”, Procedia Computer Science, vol 167, pp 26-36, 2020, doi: https://doi.org/10.1016/j.procs.2020.03.179
S. Zeng, R. Huang, Z. Kang, N. Sang, “Image segmentation using spectral clustering of Gaussian mixture models”, Neurocomputing, vol. 144, pp. 346-356, Nov, 2014. doi: https://doi.org/10.1016/j.neucom.2014.04.037
X. Wang, Z. Yang, X. Yue, H. Wang, “A Group Norm Regularized Factorization Model for Subspace Segmentation”, IEEE Transactions on Cybernetics, vol 8, 2020, doi: https://doi.org/10.1109/ACCESS.2020.3000816
M. Angulakshmi, G.G. Lakshmi Priya, “Walsh Hadamard Transform for Simple Linear Iterative Clustering (SLIC) Superpixel Based Spectral Clustering of Multimodal MRI Brain Tumor Segmentation”, IRBM, vol 40, no. 5, pp. 253-262, 2019, doi: https://doi.org/10.1016/j.irbm.2019.04.005
M. Angulakshmi, G.G. Lakshmi Priya. “Brain tumour segmentation from MRI using superpixels based spectral clustering”, Journal of King Saud University - Computer and Information Sciences, 2018, doi: https://doi.org/10.1016/j.jksuci.2018.01.009
N. He, X. Zhang, J. Zhao, et al. “Pulmonary parenchyma segmentation in thin CT image sequences with spectral clustering and geodesic active contour model based on similarity”, Int. Conf. Digital Image Process., Hong Kong, 2017, doi: https://doi.org/10.1117/12.2281942
M. Spindler, C. M. Thiel, “Quantitative magnetic resonance imaging for segmentation and white matter extraction of the hypothalamus,” Journal of Neuroscience Research, vol. 100, no. 2, pp. 564-577, 2022, doi: https://doi.org/10.1002/jnr.24988
J. Hou, W. Liu, X. E, H. Cui, “Towards parameter-independent data clustering and image segmentation”, Pattern Recognit., vol. 60, pp. 25-36, 2016, doi: https://doi.org/10.1016/j.patcog.2016.04.015
N. Qiao, L. Di, “An improved method of linear spectral clustering”, Multimedia Tools and Applications 2021, vol. 81, no. 1, pp. 1287-1311, 2021, doi: https://doi.org/10.1007/s11042-021-11459-x
X. L. Jiang, Q. Wang, B. He, S. J. Chen, B. L. Li, “Robust level set image segmentation algorithm using local correntropy-based fuzzy c-means clustering with spatial constraints”, Neurocomputing, vol. 207, pp. 22-35, 2016, doi: https://doi.org/10.1016/j.neucom.2016.03.046
T. Inkaya, “A parameter-free similarity graph for spectral clustering”, Expert Syst. Appl., vol. 42, no. 24, pp. 9489-9498, Dec. 2015, doi: https://doi.org/10.1016/j.eswa.2015.07.074
A. Mur, R. Dormido, N. Duro, S. Dormido, J. Vega. “Determination of the optimal number of clusters using a spectral clustering optimization”,Expert Systems with Applications, vol 65, pp 304-314, 2016, doi: https://doi.org/10.1016/j.eswa.2016.08.059
F. Zhao, H. Liu, L. Jiao, “Spectral clustering with fuzzy similarity measure”, Digit. Signal Processing, vol. 21, no. 6, pp. 701-709, 2011, doi: https://doi.org/10.1016/j.dsp.2011.07.002
Y. Yang, Y. Wang, “Simulated annealing spectral clustering algorithm for image segmentation”, J. Syst. Eng. Electron., vol. 25, no. 3, pp. 514-522, 2014, doi: https://doi.org/10.1109/JSEE.2014.00059
H. Chang, D.Y Yeung, “Robust path-based spectral clustering with application to image segmentation”, Tenth IEEE Int. Conf. Comput. Vis, vol. 1, Beijing, 2005, pp 278-285, doi: https://doi.org/10.1109/ICCV.2005.210
X. Fan, L. Ju, X. Wang , S. Wang, “A fuzzy edge-weighted centroidal Voronoi tessellation model for image segmentation”, Computers and Mathematics with Applications, vol. 71, no. 11, pp. 2272-2284, 2016. doi: https://doi.org/10.1016/j.camwa.2015.11.003
L. Fang, X. Wang , Z. Lian, Y. Yao, and Y. Zhang, “Supervoxel-based brain tumor segmentation with multimodal MRI images,” Signal, Image and Video Processing, vol. 16, no. 5, pp. 1215-1223, 2022, doi: https://doi.org/10.1007/s11760-021-02072-4
E. Zimudzi, I. Sanders, N. Rollings, C. Omlin, “Segmenting mangrove ecosystems drone images using SLIC superpixels,” Geocarto International, vol. 34, no. 14, pp. 1648-1662, 2018, doi: https://doi.org/10.1080/10106049.2018.1497093
R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, S. Susstrunk, “SLIC Superpixels”, EPFL Tech. Rep. 149300, June, p. 15, 2010.
X. D. Bai, Z. G. Cao, Y. Wang, M. N. Ye, L. Zhu, “Image segmentation using modified SLIC and Nyström based spectral clustering”, Optik, vol. 125, no. 16, pp. 4302-4307, 2014, doi: https://doi.org/10.1016/j.ijleo.2014.03.035
Z. Li, J. Chen, “Superpixel segmentation using Linear Spectral Clustering”, 2015IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, 2015, pp. 1356-1363, doi: https://doi.org/10.1109/CVPR.2015.7298741
Y. Yang , Y. Wang , X. Xue, “A novel spectral clustering method with superpixels for image segmentation”, Optik, vol. 127, no. 1, pp. 161-167, 2016, doi: https://doi.org/10.1016/j.ijleo.2015.10.053
A. Schick, M. Fischer, R. Stiefelhagen, “An evaluation of the compactness of superpixels”, Pattern Recognit. Lett., vol. 43, no. 1, pp. 71-80, 2014, doi: https://doi.org/10.1016/j.patrec.2013.09.013
K. B. Schloss, L. Lessard, C. Racey, A. C. Hurlbert, “Modeling color preference using color space metrics”, Vision Research, vol 151, pp. 99-116, 2018, doi: https://doi.org/10.1016/j.visres.2017.07.001
S. E. Schaeffer, “Graph clustering”, Computer Science Review, vol. 1, no. 1, pp. 27-64, 2007, doi: https://doi.org/10.1016/j.cosrev.2007.05.001
D. Martin, C. Fowlkes, D. Tal, J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics”, ProceedingsEighthIEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 2001, pp. 416-423, doi: https://doi.org/10.1109/ICCV.2001.937655
J. Shi, J. Malik, “Normalized cuts and image segmentation”, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 22, no. 8, pp. 888-905, Aug. 2000. doi: https://doi.org/10.1109/34.868688
C. Fowlkes , S. Belongie, J. Malik, “Efficient spatiotemporal grouping using the Nyström method”, Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 2001, pp. I-I, doi: https://doi.org/10.1109/CVPR.2001.990481
Y. Ng. Andrew, M. I Jordan, Y. Weiss, “On Spectral Clustering: Analysis and an algorithm”, Proceedings of the14thInternational Conference on Neural Information Processing Systems: Natural and Synthetic. January 2001, pp. 849-856.
N. Seo, “Normalized Cuts and Image Segmentation,” 2006 [En línea]. Disponible en: http://note.sonots.com/SciSoftware/NcutImageSegmentation.html.
X. D. Bai , Z. G. Cao , Y. Wang , M. N. Ye , L. Zhu , “Image segmentation using modified SLIC and Nyström based spectral clustering”, Optik (Stuttg)., vol. 125, no. 16, pp. 4302-4307, 2014, doi: https://doi.org/10.1016/j.ijleo.2014.03.035
H. Zhang, J. E. Fritts, S. A. Goldman, “Image segmentation evaluation: A survey of unsupervised methods”, Comput. Vis. Image Underst., vol. 110, no. 2, pp. 260-280, 2008, doi: https://doi.org/10.1016/j.cviu.2007.08.003
T. Fawcett, “ROC Graphs: Notes and Practical Considerations for Data Mining Researchers ROC Graphs: Notes and Practical Considerations for Data Mining Researchers”, ReCALL, p. 27, 2003.
R. Iakymchuk, “Performance prediction through time measurements”, International Conference on High Performance Computing, Kyiv, Ukraine, October 12-14, 2011.
R. Guerequeta, A. Vallecillo, Técnicas de diseño de algoritmos. Servicio de Publicaciones e Intercambio Científico de la Universidad de Málaga, 2000.
Notas
