Ciência de Dados: Enfoque no Desafio do Processamento
Data Science: Focus on Processing Challenge
Ciencia de datos: enfoque en el desafío de procesamiento
 Bornieque Brister Marcovit Pacheco borniek@hotmail.com
Marcelo Salton Disconzi mdisconzi@gmail.com
Bornieque Brister Marcovit Pacheco borniek@hotmail.com
Marcelo Salton Disconzi mdisconzi@gmail.com
Ciência de Dados: Enfoque no Desafio do Processamento
Research, Society and Development, vol. 8, núm. 11, pp. 01-15, 2019
Universidade Federal de Itajubá

Este trabalho está sob uma Licença Internacional Creative Commons Atribuição 4.0.
Recepção: 23 Julho 2019
Revised: 25 Julho 2019
Aprovação: 12 Agosto 2019
Publicado: 23 Agosto 2019
Resumo: A ciência de dados está em constante evolução, porém muitos problemas são por vezes impossíveis de solucionar, seja somente devido a grande quantidade de dados coletados ou associado aos diferentes tipos de dados, ao afirmar que existem vários problemas impossíveis de se solucionar por questões de processamento, e observar que o dilúvio de dados só aumenta a cada dia, fica o seguinte questionamento: Qual o caminho a ciência de dados pode seguir para conseguir driblar a questão do limite de processamento dados em quantidades cada vez mais exorbitantes? Este artigo tem por objetivo sugerir uma possível solução futura para o problema através de uma pesquisa descritiva, por meio de análise documental. Seguindo os seguintes passos: Embasamento teórico básico sobre a Ciência de Dados, Banco de dados NoSQL, Big Data, Machine Learning e o Computador Quântico, tendo por finalidade apontar passos futuros ou possíveis problemas.
Palavras-chave: Limite de processamento, Computador quântico, IA.
Abstract: Data science is constantly evolving, but many problems are sometimes impossible to solve, either because of the large amount of data collected or associated with different types of data, by stating that there are several problems that can not be solved by processing issues , and to observe that the flood of data only increases every day, the following question remains: What path can data science follow in order to manage the issue of the processing limit given in increasingly exorbitant quantities? This article aims to suggest a possible future solution to the problem through descriptive research, through documentary analysis. Following the following steps: Basic theoretical background on Data Science, NoSQL Database, Big Data, Machine Learning and the Quantum Computer, aiming at pointing out future steps or possible problems.
Keywords: Processing limit, Quantum computer, AI.
Resumen: La ciencia de datos está en constante evolución, pero a veces es imposible resolver muchos problemas, ya sea por la gran cantidad de datos recopilados o asociados con diferentes tipos de datos, al afirmar que existen varios problemas que no pueden resolverse por razones de procesamiento. Y, teniendo en cuenta que la avalancha de datos solo crece día a día, es la siguiente pregunta: ¿Qué camino puede tomar la ciencia de los datos para evitar el límite del procesamiento de datos en cantidades cada vez mayores? Este artículo pretende sugerir una posible solución futura al problema a través de una investigación descriptiva a través del análisis de documentos. Siguiendo los siguientes pasos: Antecedentes teóricos básicos sobre Data Science, NoSQL Database, Big Data, Machine Learning y Quantum Computer, con el objetivo de señalar pasos futuros o posibles problemas.
Palabras clave: límite de procesamiento, Ordenador cuántico, IA.
1. Introdução
A ciência de dados estuda o ciclo de vida dos dados e visa geração de valor comercial a partir de insights, que são informações geradas a partir dos dados. No espaço de tempo de uma década, pode-se considerar um verdadeiro dilúvio de dados, em ciências como física ou astronomia, por exemplo, novos experimentos geram petabytes (PB) de dados (Bell et al., 2009). Com a expansão de novas tecnologias e dispositivos, a tendência é seguir essa crescente produção de dados.
Segundo Taurion (2013), empresas atuais, não podem tomar decisões baseadas em palpites, pois com o grande volume de dados, temos que tratar os mesmos, gerar valor em tempo hábil, para tomar decisões baseadas em dados concretos.
Machado (2018), trata Big Data como um grande volume de dados gerados de forma universal, que pode ser considerado como uma nova onda de tecnologia e arquitetura, a fim de gerar conhecimento com valor competitivo entre corporações e governos.
A Ciência de dados abrange incontáveis áreas, algumas inclusive pouco imagináveis, como o futebol, conforme o caso de sucesso contado pelo jornal The New York Times em 22 de maio de 2019. O time do Liverpool, campeão da Liga dos Campeões 2018-09, o principal campeonato de clubes do mundo, foi montado com base em dados estatísticos, analisando-se entre diversos componentes, o quanto cada jogador combinava para os demais atletas do clube, levando em consideração o máximo de informações sobre os mesmos dentro de campo (Schoenfeld, 2019).
O presente artigo se justifica através da necessidade de manipulação e processamento de dados cada vez maiores, por parte de empresas e governos, no ramo da ciência de dados. Qual o caminho que a ciência de dados pode seguir para conseguir driblar a questão do limite de processamento dados em quantidades cada vez mais exorbitantes?
A Lei de Moore se apresenta com um possível fim próximo, ao se considerar que poderá se tornar fisicamente impossível ou com custo benefício inviável para produção a nível comercial.
Segundo Matos (2018), o computador quântico poderia detectar em grandes conjuntos de dados ou ajudar a integrar dados de diferentes conjuntos de dados. O computador quântico poderia ser uma saída para o processamento exigido pela ciência de dados?
2. Revisão Bibliográfica
No contexto histórico, Ciência de Dados ou “Data Science” é uma expressão antiga, dos anos de 1960, porém a mesma é uma ciência nova, que em definição mais sucinta são processos, modelos e tecnologias que estudam o ciclo de vida do dado (Amaral, 2016).
Concordamos com Amaral uma vez que esta ciência está em evolução e novos saberes lhe são acrescentados trazendo mais conhecimento sobre o tema ao longo do tempo. A Figura 1 ilustra o ciclo de vida no trabalho com dados.
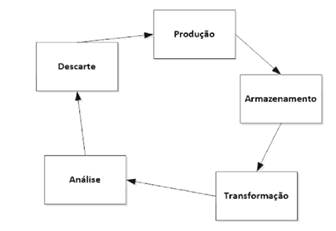
Figura 1 -
Ciclo de vida dos dados
Fonte: AMARAL (2016, p. 06)
Empresas estão coletando dados em: operações, fabricação, gestão da cadeia de suprimentos, relacionamento com o cliente, desempenho em campanha de marketing, procedimentos de fluxo de trabalho, redes sociais e entre outros. Com a finalidade de analisa-los para corrigir problemas, prever tendências futuras ou mesmo automatizar processos. Visando vantagens comerciais (MATOS, 2015).
Concordamos com Matos, pois grandes empresas não querem continuar realizando decisão por achismo dos gestores, mas sim baseadas em dados consistentes.
2.1 Banco de dados NoSQL
O NoSQL (Not Only SQL) surgiu para resolver a problemática de tratamento de grandes volumes de dados, sem prejudicar o desempenho. Se tornando uma nova forma de persistência de dados, baseada em disponibilidade, desempenho e escalabilidade dos dados (TOTH, 2011).
O blog de informações, especializado em ciência de dados para profissionais da área de Ciência de Dados, o Ciência e Dados, define a importância dos bancos de dados NoSQL para a Ciência de Dados. Descrevendo-os como bancos de dados não relacionais e sem esquemas, com alta adaptabilidade e eficiência para gerir processamento de grandes volumes de dados, este termo pode ser usado para paradigmas como: Key-value stores, document stores, graph databases, entre outros (MATOS, 2018).
Conforme colocação de Matos, os bancos de dados relacionais não seriam capazes de atender a necessidade de disponibilidade, desempenho e escalabilidade dos dados, em ciência de dados.
2.2 Big data
Vários autores tem diferentes conceitos para o termo Big Data, Amaral (2016) descreve Big Data como um conjunto de três “Vs”, sendo eles volume, velocidade e variedade. Mais adiante, passou a se considerar cinco “Vs”, incluindo veracidade e valor. A Oracle Brasil, (www.oracle.com, 2019), define os cinco “Vs” iniciais da seguinte forma:
-
Volume: A quantidade de dados é um fator importante, sendo possíveis trabalhar com informações geradas de maneira analógica ou digital, podendo algumas empresas armazenar terabytes ou petabytes;
-
Velocidade: É taxa mais rápida em que os dados são recebidos, podendo as taxas mais rápidas, ser transmitidas diretamente para a memória ou assim como as mais lentas armazenadas em disco ou ainda estar habilitados para operar em tempo real;
-
Variedade: Refere-se aos vários tipos de dados existentes, podendo ser estruturados, não estruturados ou semiestruturados;
-
Veracidade: Refere-se à garantia de autenticidade, dos dados extraídos, tentando assim, distinguir erros do sistema de informações;
-
Valor: O principal objetivo do Big Data é gerar valor a partir das informações analisadas, podendo eles ser traduzidos em vantagem competitiva entre as corporações.
O Big Data busca potencializar negócios, para corrigir problemas existentes ou prever tendências futuras, com a finalidade de gerar vantagens competitivas, melhorar tomadas de decisão, reduzir custos aumentar receitas (FELIX et al., 2018).
Concordamos com as afirmações de Felix, pois o principal foco da ciência de dados, junto com o Big Data é gerar valor a partir dos dados.
2.3 Machine learning
O termo Machine Learning ou sua tradução simples Aprendizado de Máquina, segundo o portal Data Science Academy (2018), “uma das primeiras pessoas a usar o termo, provavelmente foi Arthur Samuel, em 1959, com a finalidade de programar um jogo de damas”.
Segundo Monard & Baranauskas segue a seguinte descrição:
“Aprendizado de Máquina é uma área de IA cujo objetivo é o desenvolvimento de técnicas computacionais sobre o aprendizado bem como a construção de sistemas capazes de adquirir conhecimento de forma automática. Um sistema de aprendizado é um programa de computador que toma decisões baseado em experiências acumuladas através da solução bem sucedida de problemas anteriores.” (Monard & Baranauskas, 2003).
Conforme com as colocações de Monard e Baranauskas, IA consiste em adquirir conhecimento, baseando-se em experiências bem sucedidas. Concordamos com as colocações do mesmo.
Mais adiante, a Figura 2 ilustra o modelo de Machine Learning:

Figura 2 -
Representação do modelo de Machine Learning
Fonte: https://medium.com/intro-to-artificial-intelligence/deep-learning-series-1-intro-to-deep-learning-abb1780ee20.
Conforme descrito na figura, o Aprendizado de Máquina algoritmos recebem dados previamente preparados e aplicam análises estatísticas, retornando respostas mais precisas.
O portal Data Science Academy (2018), cita alguns casos de utilização de Machine Learning, são eles: Detecção de fraudes, sistemas de recomendação, mecanismos de busca, reconhecimento de manuscrito, processamento de linguagem natural, bots de serviço ao cliente, segurança de TI, análise de streaming de dados, manutenção preditiva, detecção de anomalia, previsão de demanda, logística, negociação financeira, diagnostico de cuidados de saúde, veículos autônomos e robôs. Vários dos casos de uso listados podem ser manipulados sem o aprendizado de máquina, mas o aprendizado trás com sigo a velocidade na criação de modelos, precisão no aprendizado, eficiência e economia de custos, apesar de levar em conta o auto custo de Machine Learning.
2.4 Limite do processamento tradicional ou o fim da Lei de Moore
Em 1965, em um artigo escrito para a revista Electronic Magazine, Gordon Moore fez a seguinte previsão:
“A complexidade dos custos mínimos dos componentes aumentou a uma taxa aproximada de um fator de dois por ano. Certamente, a curto prazo, pode-se esperar que essa taxa continue, se não aumente. A longo prazo, a taxa de aumento é um pouco mais incerta, embora não haja razão para acreditar que ela não permanecerá quase constante por pelo menos 10 anos. Isso significa que, em 1975, o número de componentes por circuito integrado para o custo mínimo será de 65.000. Eu acredito que um circuito tão grande pode ser construído em uma única bolacha (componente)" (Moore, 1965).
Até os dias atuais, a Lei de Moore vem se mantendo, por mais de 4 décadas, tempo que torna impossível descordarmos da mesma.
Conforme Schwab (2019), os transistores atuais, estão menores que um vírus, os mesmos já atingiram a medida de nanômetro, com unidade de medida “nm”, a critério de comparação, o diâmetro do fio de cabelo é de 50.000nm, em contrapartida a Intel poderá lançar transistores com cerca de 7nm até 2024, chegando praticamente no limite físico para transistores de silício. Outras tecnologias, como a criada por pesquisadores em Berkeley, criaram um transistor usando nanotubos de carbono e dissulfeto de molibdênio, este por sua vez, com apenas 1 nm de largura. Considerando a Lei de Moore, mais cedo ou mais tarde, será fisicamente impossível dobrar o número de transistores por polegada quadrada, por outro lado, fazer isso possível pode tornar o custo inviável para uso comercial.
2.5 Computador quântico
“Computador quântico é um computador que usa as leis da mecânica quântica para realizar cálculos. Pode resolver mais rapidamente que o computador mais rápido moderno. Ele promete capacidade de processamento mais poderosa do que qualquer computador convencional poderia ser” (PANDEY, 2015).
Concordamos com Pandey, pois empresas gigantes como Google e IBM, estão fazendo diversos investimentos para tentar desenvolver máquinas estáveis.
David Matos, profissional formado em ciência de dados, com experiência em TI e negócios, na América Latina, Canadá e Estados Unidos, em seu blog Ciência e Dados, define o computador quântico da seguinte forma:
"É uma máquina capaz de solucionar problemas computacionais muito difíceis de forma incrivelmente ágil. Conforme vimos na seção anterior, em computadores convencionais, a unidade de informação é o “bit” que pode assumir um valor 1 ou 0. Seu equivalente no sistema quântico – o qubit (bit quântico) – pode ser 1 e 0 ao mesmo tempo. O fenômeno permite que múltiplos cálculos sejam realizados simultaneamente. No entanto, qubits precisam ser sincronizados usando um efeito quântico conhecido como entrelaçamento, o que Albert Einstein chamou de uma “ação fantasma à distância”." (MATOS, 2018).
Concordamos com as afirmações de Matos, visto que os bits quânticos ou qubits, podem assumir os valores 1 e 0 ao mesmo tempo, podendo assim, realizar múltiplos cálculos simultaneamente.
Com a computação quântica, será possível resolver problemas antes impossíveis, para os modelos clássicos de computadores, como solucionando cálculos que demorariam anos, em alguns minutos (NUNES, 2016).
Estamos de acordo com as afirmações, pois testes realizados pelos cientistas do Google AI, afirmam que o ganho computacional em relação aos computadores convencionais é duplamente exponencial.
Os computadores quânticos seriam uma possível solução para o problema de processamento de dados, visto que: “A complexidade e o tamanho de nossos conjuntos de dados estão crescendo mais rapidamente que nossos recursos de computação e, portanto, sobrecarregam consideravelmente nossa malha de computação" (MARR, 2019).
Conforme descrito no parágrafo anterior, com quantidade cada vez maior de dispositivos e sistemas gerando dados, ligados à necessidade de empresas em gerar valor a partir de grande quantidade de dados e à possível estagnação da Lei de Moore, concordamos com a afirmação do autor.
Após construir modelos estáveis de computadores quânticos, tirando proveito de estranhas leis da mecânica quântica, existirá um novo padrão para a computação, podendo esses resolver problemas com um número considerável de variáveis, úteis para problemas logísticos ou buscas em gigantescos bancos de dados não estruturados (SCHWAB, 2019).
Estamos em conformidade com as afirmações de Schwab, após construir computadores quânticos estáveis, existiram novos padrões computacionais, levando-se em conta todo o poder computacional e a sua tendência para detecção de padrões.
Pandey (2015), afirma que o computador quântico pode resolver problemas de big data.
“Podemos dizer que o computador quântico pode resolver problemas em escala além de qualquer computador convencional. Dessa forma, descobrimos que a computação quântica pode ser utilizada em larga escala para analisar o problema de dados em rápido crescimento na web, chamados big data. Ele pode ser utilizado prevendo antecipadamente o tempo, prevendo desastres naturais como tsunami, terremoto, business intelligence e muito mais” (PANDEY, 2015).
Pandey tem total razão ao afirmar que o computador quântico pode em escala além qualquer computador convencional, pois o ganho de computacional é duplamente exponencial.
Na Figura 3, temos o Q Sistem One, o primeiro computador quântico para uso comercial da IBM.

Figura 3 -
Q Sistem One primeiro computador quântico para uso comercial da IBM
Fonte: Divulgação/IBM
O Q Sistem One, primeiro computador quântico para uso comercial da IBM, foi apresentado em janeiro de 2019, na CES 2019 (Consumer Eletronic Show), maior feira de tecnologia do mundo, o mesmo está sendo disponibilizado para uso comercial, por meio de acesso remoto, em nuvem.
Hartnett (2019), destaca testes realizados pelos cientistas do Google AI, onde o diretor Hartmut Neven, destaca a taxa de ganho computacional dos computadores quânticos em relação aos computadores clássicos é duplamente exponencial ou seja:  ,
,  ,
,  ,
,  ,
,  , e assim sucessivamente, sendo tratada como a Lei de Neven. Considerando o ganho computacional dos computadores clássicos segundo a Lei de Moore, pode-se fazer a ilustração conforme segue o Quadro 1:
, e assim sucessivamente, sendo tratada como a Lei de Neven. Considerando o ganho computacional dos computadores clássicos segundo a Lei de Moore, pode-se fazer a ilustração conforme segue o Quadro 1:

Fonte: Elaborado pelo autor, com dados da pesquisa.
O Quadro 1, relaciona o ganho computacional do computador quântico, segundo a Lei de Neven, em relação ao computador clássico, segundo a Lei de Moore. A mesma descreve um ganho duplamente exponencial.
Segundo Schwab (2019), um dos principais problemas para a construção de um computador quântico universal está na criação e manutenção de qubits, pois exigem condições extremas, como manter a temperatura dos componentes, muito próximo do zero absoluto.
Concordamos com Schwab (2019), porém a ideia da IBM para uso comercial a partir de acesso remoto pode ser uma solução primária para os principais problemas.
A seguir, Biamonte et al. (2017), relaciona o padrão da mecânica quântica com o aprendizado de máquina.
“A mecânica quântica é bem conhecida por gerar padrões de contra intuitivo nos dados. Métodos clássicos de aprendizado de máquina, como redes neurais profundas, frequentemente têm a característica de reconhecer padrões estatísticos em dados e produzir dados que possuem os mesmos padrões estatísticos: eles reconhecem os padrões que produzem. Essa observação sugere a seguinte esperança. Se pequenos processadores de informação quântica podem produzir padrões estatísticos que são computacionalmente difíceis de serem produzidos por um computador clássico, então talvez eles também possam reconhecer padrões que são igualmente difíceis de reconhecer classicamente” (BIAMONTE et al., 2017).
Concordamos com a observação esperançosa de Biamonte et al. (2017), pois ao expandir pequenos processadores quânticos, a tendência é que os mesmos continuem a reconhecer padrões estatísticos difíceis de reconhecer em computadores quânticos.
3. Metodologia
Neste artigo foi realizada uma pesquisa descritiva, através de análise documental. (Pereira, et al., 2018).
Como meios de busca, foram utilizados sites, revistas cientificas e material digital de empresas especializadas neste ramo de atividade.
Como critérios para inclusão, foram utilizados documentos científicos preferencialmente publicados nos últimos 10 anos, primordialmente gratuitos.
O presente trabalho não necessitará ser submetido para aprovação junto ao Comitê de Ética em Pesquisa, conforme a resolução CNS 466/2012, pois se trata de uma pesquisa cujas informações serão obtidas em materiais já publicados e disponibilizados na literatura, não havendo, portanto, intervenção ou abordagem direta, junto a seres humanos. Dessa forma, a pesquisa não implicará em riscos ao sujeito.
Este trabalho visa contribuir para o problema computacional, de processamento, da expansão até então desenfreada de dados e necessidade de uso destes pela ciência de dados, que abrange praticamente todas as áreas de pesquisa que possuem dados computacionais.
4. Resultados e discussões
Com base nos artigos estudados, fica comprovado que a Ciência de Dados exige cada vez mais processamento, para a solução de problemas complexos com quantidades exorbitantes de dados que dobram a cada 2 anos.
Conforme Machado (2018) o Big Data “pode ser considerado como uma nova onda de tecnologia e arquitetura, a fim de gerar conhecimento com valor competitivo entre corporações e governos”. A fim de potencializar negócios, visando melhorar tomadas de decisões e lucro financeiro (FELIX et al., 2018).
Monard e Baranauskas (2003) Definem o Aprendizado de Maquina como um sistema de aprendizado onde programas de computador tomam decisões com base em experiências acumuladas, retornando soluções bem sucedidas. Essas operações por vezes podem se tornar impossíveis de realizar em casos de conjuntos de dados exorbitantes, levando em consideração o tempo de execução da tarefa.
Schwab (2019) destaca o possível fim da Lei de Moore, levando em consideração que se tornará fisicamente impossível dobrar o número de transistores por polegada quadrada. Esse processo pode congelar os avanços da Ciência de Dados, levando em consideração a necessidade constante de processamento computacional.
Segundo Matos (2018), o computador quântico poderia detectar em grandes conjuntos de dados ou ajudar a integrar dados de diferentes conjuntos de dados. O que pode levar a enormes avanços para o Aprendizado de Máquina e consequentemente para a Ciência de Dados. “A complexidade e o tamanho de nossos conjuntos de dados estão crescendo mais rapidamente que nossos recursos de computação e, portanto, sobrecarregam consideravelmente nossa malha de computação" (MARR, 2019).
Hartnett (2019) destaca testes realizados por cientistas do Google AI, onde constataram que o ganho de processamento computacional do computador quântico é duplamente exponencial em relação aos computadores clássicos, porém é preciso levar em consideração os problemas para a criação de computadores quânticos estáveis, como a exigência de condições extremas, como manter a temperatura dos componentes, muito próximo do zero absoluto, para a criação de qubits (bit quântico).
4. Considerações finais
Ao averiguar a revisão bibliográfica, pode-se afirmar que apesar do os rumos da Ciência de Dados estão diretamente ligados à construção de computadores quânticos totalmente estáveis e funcionais em nível comercial.
Com o diluvio de dados, alguns problemas abordados por Big Data se tornam por vezes impossíveis, pois mesmo colocando computadores tradicionais em paralelo, o tempo que leva para analisar registro por registro é incrivelmente enorme.
A tecnologia dos computadores quânticos tem enorme potencial para solucionar os problemas de processamento em grandes volumes de dados e detecção de padrões para a Ciência de dados, porém ainda possuem problemas considerados críticos e que podem inviabilizar funcionamento de computadores quânticos tal qual computadores tradicionais, mas tecnologia quântica no geral poderá ganhar novos conceitos de aplicação para uso em conjunto com tecnologias já existentes.
Referências
Amaral, F. (2016). Introdução à ciência de dados: mineração de dados e big data. Alta Books Ed. Rio de Janeiro.
Bell, G., Hey, T., & Szalay, A. (2009). Beyond the Data Deluge. Tradução Google translate. Science, 323:1297–1298.
Biamonte, J. et al. (2017). Quantum machine learning. Nature, 549(7671): 195.
Equipe DAS (2018). 17 Casos de Uso de Machine Learning. [Blog] Data Science Academy. Disponível em: <http://datascienceacademy.com.br/blog/17-casos-de-uso-de-machine-learning/>;. Acesso em: 12 jul. 2019.
Felix, B.M., Tavares, E. & Cavalcante, N.W.F. (2018). Fatores críticos de sucesso para adoção de Big Data no varejo virtual: estudo de caso do Magazine Luiza. Rev. bras. gest. neg., São Paulo , 20(1):112-126. Disponível em: <http://www.scielo.br/scielo.php?script=sci_arttext&pid=S1806-48922018000100112&lng=pt&nrm=iso>;. Acessos em: 13 jun. 2019. http://dx.doi.org/10.7819/rbgn.v20i1.3627.
Hartnett, K. (2019). A lei de Neven descreve a ascensão da computação quântica? | Revista Quanta. Disponível em: <https://www.quantamagazine.org/does-nevens-law-describe-quantum-computings-rise-20190618/>;. Acesso em: 25 jul. 2019.
Machado, F.N.R. (2018). Big Data O Futuro dos Dados e Aplicações. Editora Saraiva.
Matos, D. (2015). Ciência de Dados e Soluções. [Blog] Ciência e Dados. Disponível no website: <http://www.cienciaedados.com/ciencia-de-dados-e-solucoes/>;. Acesso em: 13 jul. 2019.
Matos, D. (2018). Como a Computação Quântica Vai Revolucionar a Inteligência Artificial, Machine Learning e Big Data. [Blog] Ciência e Dados. Disponível em: <http://www.cienciaedados.com/como-a-computacao-quantica-vai-revolucionar-a-inteligencia-artificial-machine-learning-e-big-data/>;. Acesso em: 13 jun. 2019.
Matos, D. (2015). NoSQL Database. [Blog] Ciência e Dados. Disponível em: <http://www.cienciaedados.com/nosql-database/>;. Acesso em: 11 jul. 2019.
Matos, D. (2018). Top 6 NoSQL Databases. [Blog] Ciência e Dados. Disponível em: <http://www.cienciaedados.com/top-6-nosql-databases/>;. Acesso em: 11 jul. 2019.
Marr, B. (2017). How Quantum Computers Will Revolutionize Artificial Intelligence, Machine Learning And Big Data. | Revista Forbes. Disponível em: <https://www.forbes.com/sites/bernardmarr/2017/09/05/how-quantum-computers-will-revolutionize-artificial-intelligence-machine-learning-and-big-data/#435f6d445609>;. Acesso em: 11 jun. 2019.
Monard, M.C. & Baranauskas, J.A. (2003). Conceitos sobre aprendizado de máquina. Sistemas inteligentes-Fundamentos e aplicações, v. 1, n. 1, p. 32.
Moore, G.E. et al. (1965). Cramming more components onto integrated circuits.
Nunes, J. (2016). Computadores quânticos, informação e computação quânticas. Correio dos Açores, p. 17-17.
O que é Big Data? [Website] Oracle Brasil.Disponível em: <https://www.oracle.com/br/big-data/guide/what-is-big-data.html>;. Acesso em: 12 jun. 2019.
Pandey, A. & Ramesh, V. (2015). Quantum computing for big data analysis. Indian Journal of Science, v. 14, n. 43, p. 98-104.
Pereira, A.S. et al. (2018). Metodologia da pesquisa científica. [e-book]. Ed. UAB/NTE/UFSM, Santa Maria/RS. Disponível em: https://repositorio.ufsm.br/bitstream/handle/1/15824/Lic_Computacao_Metodologia-Pesquisa-Cientifica.pdf?sequence=1. Acesso em: 25 julho 2019.
Schoenfeld, B. (2019). How Data (and Some Breathtaking Soccer) Brought Liverpool to the Cusp of Glory - The New York Times. Tradução Google translate. Disponível em: <https://www.nytimes.com/2019/05/22/magazine/soccer-data-liverpool.html>;. Acesso em: 11 jul. 2019.
Schwab, K. & Davis, N. (2019). Aplicando a quarta revolução industrial,. Edipro, São Paulo.
Taurion, C. (2013). Big data. Brasport.
Toth, R.M. (2011). Abordagem NoSQL–uma real alternativa. Sorocaba, São Paulo, Brasil: Abril, 13(1).
Porcentagem de contribuição de cada autor no manuscrito
Bornieque Brister Marcovit Pacheco – 90%
Marcelo Salton Disconzi – 10%