Artículos originales
Componente de indexación de huellas dactilares basado en características globales
Fingerprints indexing component based on global features
 Allen Torres Ruíz allenstr90@gmail.com
Allen Torres Ruíz allenstr90@gmail.com
Componente de indexación de huellas dactilares basado en características globales
Innovación y Software, vol. 1, núm. 1, pp. 58-73, 2020
Universidad La Salle

Esta obra está bajo una Licencia Creative Commons Atribución 4.0 Internacional.
Recepción: 04 Diciembre 2019
Aprobación: 07 Marzo 2020
Publicación: 30 Marzo 2020
Resumen: El campo de orientación de la huella dactilar como característica global es fundamental para el desarrollo de una estrategia de indexación, aportando estabilidad y disminuyendo los tiempos de respuesta durante el proceso de búsqueda de un sistema de identificación basado en huellas dactilares. El empleo de grafos relacionales de atributos y máscaras dinámicas permite explotar las características brindadas por el esquema de particionado para la búsqueda. De cada una de las estrategias propuestas se determinó el índice de penetración de la base de datos, así como el error en que incurren los algoritmos de indexación implementados. Para corroborar los resultados obtenidos fueron empleados los bancos de datos aportados por la Competencia de verificación de huellas dactilares. La implementación computacional de las estrategias de búsquedas propuestas demuestra las virtudes que ofrece el campo de orientación para dirigir el proceso de búsqueda, logrando reducir el número de comparaciones en un 53.24 % como promedio, comportándose de manera estable ante imágenes de huellas dactilares de diferente calidad. Basado en los resultados del estudio se concluyó que la adopción de dichas estrategias de indexación permitirá reducir el tiempo de respuesta en el módulo de identificación de individuos basado en patrones de la huella dactilar propuesto por el Centro de Identificación y Seguridad Digital de la Universidad de las Ciencias Informáticas.
Palabras clave: campo de orientación, grafos relacionales de atributos, indexación de huellas dactilares, máscaras dinámicas.
Abstract: The fingerprint orientation field is a widely used feature for developing indexing strategies. Such feature brings stability and decreases the response times during the identification process. The use of attribute relational graphs and dynamic masks can exploit the features provided by the partitioning scheme. The penetration index and the error rate for each of the proposed strategies were determined. To verify the results obtained were used the databases provided by the Fingerprint Verification Competition. Both search schemes reveal the facilities offered by the orientation field for guiding the searching process; reducing the number of comparisons in 53.24 %; proving its stability against different fingerprint image qualities. Based on the results, it was proven that the adoption of such indexing strategies will reduce the response time in the identification module proposed by the Identification and Digital Security Center at the University of Informatics Sciences.
Keywords: attribute relational graphs, dynamic masks, fingerprints indexing, orientation field..
Introducción
Los sistemas de reconocimiento de huellas dactilares se basan fundamentalmente en dos procesos: la verificación e identificación. Este último, requiere la búsqueda y comparación del patrón de entrada teniendo como campo de análisis la totalidad de la base de datos, cuyo tamaño actualmente se encuentra en el orden de los millones de impresiones, por lo cual la búsqueda lineal resulta impracticable cuando se requiere inmediatez en el proceso. Algunas estrategias para agilizar el proceso de búsqueda proponen dividir la base de datos en un conjunto de grupos, basados en alguna clasificación predefinida. La más ampliamente difundida de estas técnicas de clasificación se basa en los estudios de Francis Galton en 1892 y Edward Henry en 1900; este esquema reconoce como clases: arco, arco tendido, lazo izquierdo, lazo derecho y espiral. Con la perspectiva de solventar los problemas asociados al problema en cuestión, surge otra técnica definida como indexación de huellas dactilares, cuyo método emplea una clave para retornar una lista ordenada por relevancia de aquellos candidatos potenciales a coincidir con el patrón dactilar de entrada [1].
Las características globales, tales como patrón descrito por las crestas y las singularidades presentes en la huella dactilar, son obtenidas en las primeras etapas del preprocesado de su imagen. La independencia y robustez de las estrategias de indexación basadas en características globales de la huella dactilar, arrojan resultados que validan la calidad de la misma, como se puede constatar en [1]-[4].
El Centro de Identificación y Seguridad Digital (CISED), perteneciente a la Universidad de las Ciencias Informáticas (UCI), desarrolla soluciones de software empleadas en casi todas las esferas de la sociedad para el control y resguardo de sus recursos. El sistema de verificación de identidades propuesto por CISED se encuentra en constante actualización y requiere de un proceso continuo de investigación para continuar mejorando la eficiencia y efectividad de su servicio. La aplicación de las estrategias implementadas en CISED hasta hoy, por sí solas no solventan el problema de la búsqueda durante la identificación de individuos por medio de huellas dactilares.
Varias han sido las propuestas a lo largo de los años que utilizan características globales de las huellas para la indexación. En [5], se utilizan los resultados planteados en [6] para presentar un algoritmo invariante a la traslación y rotación que no requiere la detección de las singularidades, evolucionando el enfoque presentado en [7]. En [8] proponen la utilización de un vector de 156 componentes de orientación e información procedente del campo de orientación para la búsqueda. Un enfoque estadístico más sofisticado, es propuesto en [9]; los cuales utilizan los coeficientes del modelo FOMFE, como vector de características. En [10] presentan el uso de los momentos polares complejos para extraer una representación invariante a la rotación del campo de orientación de la huella; dicha representación es utilizada para generar un vector de características compacto y de longitud fija. Un estudio más reciente es [11], este utiliza redes neuronales para implementar un clasificador (de 4 clases) con altos niveles de efectividad.
La presente investigación tiene como objetivo el análisis y evaluación de los algoritmos propuestos en [5], [7] los cuales utilizan el campo de orientación de la huella dactilar para implementar una estrategia de búsqueda simplificada que empleando grafos relacionales de atributos y máscaras dinámicas a partir de la entrada permiten extraer un vector de características robusto e invariante a la traslación y rotación lo suficientemente discriminante en un tiempo adecuado para su implementación en un sistema de verificación que atienda peticiones en línea.
Lo novedoso de la investigación se ve reflejado en el empleo del algoritmo propuesto en [7] para la indexación de huellas dactilares, en lugar de la clasificación, principio fundamental para el que fue creado. Además, la utilización de un algoritmo genético de nuevo tipo y una estrategia dinámica de búsqueda en árbol, definida como TS, propuesto en [12] para efectuar la comparación inexacta entre dos grafos relacionales de atributos dados. Por otra parte, a la estrategia propuesta en [5] se le incorpora un procedimiento semiautomático que contribuye a la elaboración de las máscaras dinámicas utilizadas por dicha estrategia. Para la abstracción de las máscaras dinámicas es empleado un algoritmo de triangularización de polígonos para lograr la correcta aproximación de los vértices de la máscara en un tiempo eficiente, requiriendo un mínimo de ajuste en lugar de la creación manual de dichas máscaras. Las estrategias de indexación propuestas se implementaron empleando el lenguaje de programación C# y fueron insertadas en un framework que permitió comprobar la efectividad y el rendimiento de los mismos. Los bancos de datos utilizados para las pruebas del experimento son las publicadas en el sitio oficial de Competencia de Verificación de Huellas Dactilares (FVC - Fingerprint Verification Competition) FVC2000 y la FVC2004: DB1_B, DB2_B, DB3_B, DB4_B[13].
Metodología computacional
Utilización de grafos relacionales de atributos
El enfoque estructural propuesto por [7] versa sobre la aplicación de la estructura de grafo sobre el campo de orientación de la huella dactilar para generar una clasificación exclusiva empleada en el proceso de identificación de los Sistemas Automáticos de Identificación de Huellas Dactilares (AFIS - Automatic Fingerprint Identification System). La comparación de grafos consiste en encontrar una correspondencia entre dos grafos dados, donde los vértices son rotulados de acuerdo al mayor ajuste encontrado. El esquema funcional de dicha propuesta se divide en cinco pasos fundamentales: 1) cálculo de la imagen direccional o campo de orientación, 2) particionado de la imagen, 3) construcción del grafo relacional, 4) comparación inexacta de grafos y 5) clasificación dactilar (ver Figura 1).
![Pasos fundamentales de la propuesta descrita en [7].](../673870834005_gf2.png)
Figura 1.
Pasos fundamentales de la propuesta descrita en [7].
Elaboración propia inspirada en la Figura 3 de [7]
Particionado del campo de orientación
Partiendo de los algoritmos propuestos en [14],[15] para el cálculo del campo de orientación, en la etapa de particionado se enfatizan las características topológicas y estructurales de la huella. Un algoritmo dinámico de agrupamiento propuesto en [7] es adoptado para dicho propósito de acuerdo a un criterio de ajuste óptimo, intentando minimizar la varianza entre los elementos direccionales pertenecientes a la misma región y simultáneamente conservar la regularidad de la forma.
Definición 1. Sea ., el campo de orientación de la huella, una partición . de . se define como R = {R., R., ..., R.} en . con R. regiones conectadas.
Una región R. está conectada si, para cada par de elementos (d.,d.)en R., existe un camino en R. que comunique d. y d..
La obtención de una partición óptima se encuentra subordinada a un modelo de costo propuesto en [7] donde se describe una función para cada región R. como se muestra en la Ecuación 1:
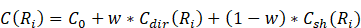 (1)
(1)Donde Cdir(R.) denota la no homogeneidad entre los elementos direccionales pertenecientes a R.. Csh(R.) denota la irregularidad de la región R.; w ∈ [0,1] constituye un valor de peso, y C. es el valor umbral correspondiente al costo definido para una región a la cual pertenezca un solo elemento.
Las definiciones propuestas en [7] para Cdir(R.) y Csh(R.) se muestran en las Ecuaciones 2 y 3:
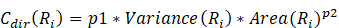 (2)
(2)
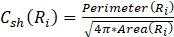 (3)
(3)Donde Variance(R.) está dada por la diferencia existente entre los elementos direccionales que pertenecen a R.. Area(R.) . Perimeter(R.)de R. representan el área y perímetro respectivos de dicha región.
Entre todas las posibles particiones de D, en [7] se define una partición R como óptima, si esta minimiza el costo total Ctot(R) según se muestra en la Ecuación 4:
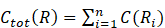 (4)
(4)Construcción del grafo relacional de atributos y comparación inexacta
El análisis de los aspectos esquemáticos del modelo, evidencia la difícil obtención de una partición óptima de la imagen de la huella dactilar en sus unidades fundamentales, por lo que no se puede esperar un isomorfismo entre dos grafos de imágenes diferentes, aunque estas representen la misma huella dactilar. El isomorfismo denota la correspondencia biunívoca entre dos estructuras algebraicas que conserva las operaciones. Por ello es necesario aplicar técnicas de comparación inexacta de grafos, que incurren en la optimización de alguna función objetivo. En el caso de este estudio, dicha función objetivo está influenciada por el costo de la partición obtenida por la Ecuación 4. Para realizar este proceso en la fase posterior al particionado del campo de orientación, se construye un grafo relacional de atributos, donde cada región es representada como un nodo y cada par de regiones adyacentes constituye una arista del dicho grafo.
La función para medir el grado de ajuste existente entre los vértices y los nodos de ambos grafos, basada en los atributos especificados para representar cada uno de estos, así como la topología descrita, fue tomada de [12]. En la presente investigación se implementaron tres estrategias fundamentales de las propuestas por [12]; primero se desarrolló un enfoque estructural que describe una búsqueda en árbol para encontrar la mejor correspondencia posible entre dos grafos relacionales de atributos dados. Luego, una alternativa determinista del enfoque anterior y un algoritmo genético son utilizados para comparar el rendimiento y exactitud de la propuesta analizada.
Empleo de máscaras dinámicas
El estudio realizado en [5] pretende solventar la mayoría de los problemas asociados a la estrategia descrita en el Epígrafe 2.1. En lugar del enfoque de particionado anterior, se expone una estrategia estructural de agrupamiento global que realiza un particionado “guiado” del campo de orientación y genera vectores de mayor exactitud para el espacio de búsqueda, reduciendo los grados de libertad del algoritmo dinámico propuesto en [7], otorgando así estabilidad al proceso de indexación propuesto. Las máscaras dinámicas representan una abstracción del particionado y resumen la información extraída de las particiones modelos creadas para cada clase de huella dactilar establecida. Dicha estructura conserva la invariante de traslación y rotación sin incurrir en la detección de puntos singulares. Un algoritmo genético con enfoque similar al referenciado en [5], es empleado utilizando los operadores de reproducción y mutación propuestos en [17] para la clusterización jerárquica de grafos; la definición de dicha estrategia metaheurística se extrajo de [18]. Con la implementación de dicha estrategia se propone otra clusterización de los bloques pertenecientes al campo de orientación. La idea básica propuesta en [5] consiste en:
- 1. Cálculo y realzado de la imagen direccional de la huella dactilar (campo de orientación).
- 2. Empleo del conjunto de máscaras dinámicas previamente calculadas para lograr el mejor ajuste posible. Cada una es aplicada de manera independiente al campo de orientación de entrada. Luego, para determinar el mejor ajuste se emplea una función de costo derivada de la propuesta en [7].
- 3. El vector de costo resultante constituye la base para la clasificación final.
Definición de las máscaras dinámicas
La aplicación de una máscara en particular a . puede ser vista como una segmentación “guiada” de la misma, donde la cantidad de regiones y una aproximación de la forma de estas se encuentran fijados a priori. Cada máscara está compuesta por un conjunto de vértices que definen los bordes de las regiones que delimitan la segmentación. La posición de algunos vértices puede ser modificada durante el proceso de ajuste con el objetivo de lograr la mejor correspondencia con las singularidades de la huella dactilar de entrada, las cuales tienden a ocupar diferentes posiciones incluso para huellas de la misma clasificación. A la definición dada en [5] para las máscaras dinámicas, se le agregaron algunos conceptos para lograr un procedimiento que permitiera la construcción semiautomática de las mismas. A continuación, se ofrece la definición formal de máscaras dinámicas utilizada en la presente investigación (ver Figura 2).
Definición 2. Una máscara dinámica se define como una 7-tupla, M = (V,P,T,..,.,fwin,fmov), donde:
-
V = VF ∪VM ∪VD: conjunto de vértices p, cada uno de los cuales posee una posición inicial (px,py); VF denota los vértices fijos; VM denota los vértices móviles, cuya posición se puede ajustar de forma independiente durante la adaptación de la máscara; VD denota los vértices dependientes, cuya posición se encuentra anclada a la de uno de los vértices móviles. Los tres subconjuntos de vértices son disjuntos: VF ∩ VM = ∅, VF ∩ VD = ∅, VD ∩ VM = ∅.
-
P = {P1,P2,...,Pn}: conjunto de regiones poligonales cuyos vértices están en V; cada región Pi = {pa,pb,pc,...} está delimitada por el polígono definido por los vértices pa,pb,pc,... tomado en un orden dado, por lo que P es un subconjunto del conjunto potencia de V : P ⊂ ℘(V ).
-
T = {T1,T2,...,Tn}: conjunto de triángulos agrupados de acuerdo al polígono Pi que estos describen. Cada elemento, Ti = {ta,tb,tc,...}, donde tθ = (pl,pm,pn)||pl,pm,pn ∈ Pi posee una propiedad que lo define como válido o no, dicha propiedad es empleada para el procedimiento de ajuste de la máscara dinámica.
-
RD ⊆ VD × VM: relación que codifica la correspondencia entre los vértices dependientes y móviles.
-
A ⊆ P × P × ∆θ: codifica una relación entre los pares de regiones que se asocian a los ángulos que representan los valores “ideales” de su diferencia de fase. ∆θ denota el dominio de la diferencia de fase. Para cada par [Pi,Pj], cuya diferencia de orientación θij ∈ ∆θ es significativa, la tripleta (Pi,Pj,θij) ∈ A.
-
win : VM → ∆xmax × ∆ymax: función que asocia cada vértice móvil a una ventana de permisividad en el movimiento de los vértices durante la adaptación de las máscaras. ∆xmax y ∆ymax representan el dominio del máximo desplazamiento a lo largo de los ejes x y y, respectivamente.
-
fmov : RD × ∆x × ∆y → ∆x × ∆y: función que indica, para cada par en RD, el movimiento del vértice dependiente sobre la base del vértice móvil correspondiente. ∆x × ∆y representan el dominio de desplazamiento a lo largo de los ejes x y y, respectivamente.
En la Figura 2 se muestran algunas de las máscaras dinámicas obtenidas después de corregir los resultados del procedimiento automático propuesto para su construcción. Los puntos móviles son representados con color negro, los cuales tienen asociado su respectiva ventana de movilidad; en gris, se definen aquellos puntos dependientes y con una saeta se delinea su correspondiente punto móvil; los puntos blancos son aquellos cuya posición y dependencia los ubica como fijos en la máscara. Las líneas oscuras describen los polígonos que delimitan cada región y las claras los triángulos válidos que la conforman. Dichas máscaras se corresponden con huellas de la FVC2000 DB4_B.
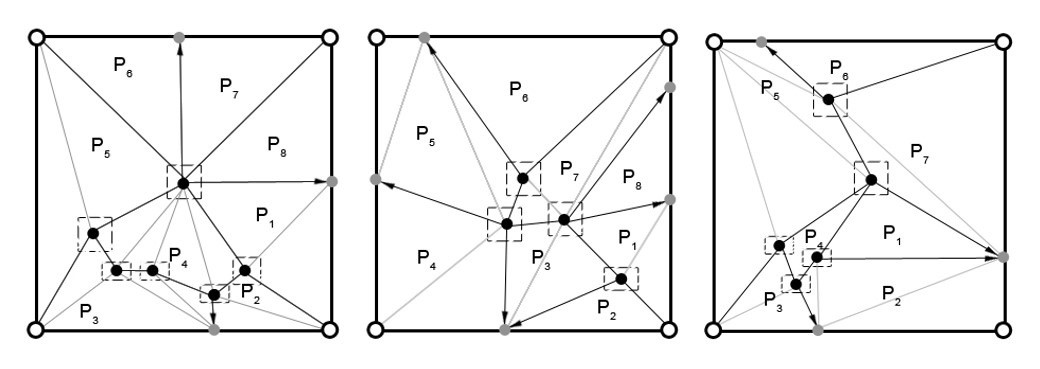
Figura 2.
Máscaras dinámicas obtenidas del procedimiento automático propuesto.
La construcción de un conjunto de máscaras prototipos es realizada durante la etapa de configuración del algoritmo de indexación al banco de datos especificado, sin incurrir en un costo adicional para el AFIS durante cada consulta realizada.
Algoritmo para la estimación automática de máscaras dinámicas
En los estudios anteriores no se incurre en el tema de la generación automática de las máscaras dinámicas propuestas por [5], ni se tiene conocimiento de cualquier otro procedimiento desarrollado para dicho propósito. Por tal motivo, se desarrolla un algoritmo dinámico que construye de manera incremental las máscaras dinámicas. La abstracción de las máscaras y la elección de una estructura consistente que almacene la información para ser aplicada en las fases posteriores del procedimiento de indexación propuesto en [5], es una tarea ardua que no está ajena a errores. Ello podría ser una de las causas por la cual no se ha encontrado ningún otro estudio realizado sobre el tema, a pesar de la notada rapidez y efectividad que denota el método en contraste con la poca información de la huella dactilar que emplea. La base fundamental de este procedimiento es la construcción de una matriz de particiones de la imagen direccional de la huella, a partir del resultado obtenido por el algoritmo de particionado empleado.
Definición 3. Sea . una matriz de dimensiones igual a ., cuyos componentes representan números enteros, cada uno de los cuales establece una correspondencia para cada elemento direccional ubicado en la posición [i,j] de . con el entero dispuesto en la posición [i,j] de .. Cada uno de estos determina a qué región pertenece dicho bloque de orientación de la matriz . a través de .. El dominio de la matriz . se corresponde con la cantidad de regiones determinadas por el algoritmo de particionado escogido.
El procedimiento empleado para la generación automática de máscaras dinámicas se realiza siguiendo los pasos:
- 1. Aplicar un procedimiento lineal para adicionar los vértices fijos de la máscara a VF, puesto que estos constituyen las aristas de la imagen.
- 2. Definir los vértices dependientes dispuestos en VD: se realiza un recorrido por los bordes de la matriz S que describe la partición de D obtenida para detectar cambios de región en los bordes de la imagen. Cada cambio de región detectado incurre en la aparición de un vértice dependiente de la máscara.
- 3. Detectar los puntos móviles agregados a VM que de manera general se corresponden con las singularidades de la huella dactilar: se emplea una estrategia similar a la expuesta en [19], sin utilizar el análisis multiresolución sobre la matriz S para detectar los puntos móviles de la máscara.
- 4. Definir a priori las ventanas de movilidad para los elementos en VM: se utiliza un procedimiento arbitrario que asigna a cada ventana perteneciente a un punto móvil valores entre 4, 2 y 6 a cada una de sus dimensiones, lo cual genera indistintamente ventanas cuadradas y rectangulares. Según el análisis realizado de la propuesta descrita en [5] se puede seguir un orden fijado a priori para obtener resultados similares a los descritos en ese estudio.
- 5. Utilizar el Algoritmo H.1 propuesto en [20] para la construcción de las regiones poligonales que describen la partición definida por la máscara dinámica a partir del conjunto V de vértices. Luego, un algoritmo de triangularización de polígonos propuesto en [19] es empleado con el objetivo de determinar un subconjunto del espacio de triangulaciones en las que puede ser dividido el polígono detectado. La solución propuesta es óptima y permite lidiar con la inclusión en la región de algún vértice que no le corresponda, debido a que el algoritmo dinámico empleado para asignar los vértices a regiones no es lo suficientemente robusto. La triangularización resultante del algoritmo propuesto en [19] requiere el mínimo de modificación humana para lograr una correcta descripción de las máscaras dinámicas propuestas por [5].
- 6. Definir RD: se determina la relación existente entre los vértices del conjunto V basado en la matriz de partición S.
- 7. Establecer el conjunto A: se definen las relaciones de fase entre regiones de la máscara utilizando una estrategia heurística definida a priori por los autores en correspondencia con la diferencia de fase obtenida entre el promedio de las orientaciones de cada región. El dominio previamente se encuentra fijado en el intervalo máximo admisible [0,π]. Con la realización de un análisis de las diferencias de fase entre regiones se establece un rango r (ver Ecuación 5) el cual es tomado como dominio admisible para la máscara construida.
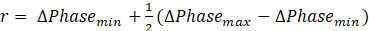 (5)
(5)Las máscaras dinámicas definidas son representadas en la aplicación resultante de dicho estudio como un XML que las describe formalmente. Dicho archivo en el formato especificado es cargado posteriormente por el procedimiento encargado de “guiar” el particionado durante el proceso de indexado propuesto. Para la codificación de las máscaras se emplea la clase nativa del .NET Framework 4.5, XmlSerializer.
Resultados y discusión
En orden de comparar el rendimiento de las dos propuestas de indexación descritas en el Epígrafe 2.1 y el Epígrafe 2.2, tomando como referencia la igual denominación propuesta en [5], se escogió una de las estrategias de recuperación definidas en [6]. Se simularon pruebas de acuerdo a la metodología B., sobre los bancos de datos de la FVC2000 DB_ B, DB2_B, DB3_B y DB4_B. La estrategia escogida para la experimentación plantea un escenario incremental que permite ajustar el espacio de búsqueda sobre el banco de datos a partir de la distancia euclidiana entre el vector de entrada y el resto de los vectores almacenados en la base de datos.
Las bases de datos con las que se cuenta para la simulación contienen 80 impresiones de huellas dactilares cada una, las cuales han sido obtenidas con diferentes dispositivos de captura y la última de estas generada sintéticamente. La estructura de las imágenes presentes en los respectivos bancos de datos comprende 10 huellas, contando con 8 impresiones diferentes de cada una. En la Tabla 1 se ofrecen algunas consideraciones importantes de los conjuntos de pruebas empleados. Los parámetros empleados para los algoritmos propuestos son los siguientes: para la Ecuación 1 se utilizaron los valores .. = 1,5 y . = 0,2 y en la Ecuación 1, se emplean los valores ..= 0,001 y .. = 1,3. El rango de desplazamiento global de las máscaras utilizadas incurre en un intervalo de [−6,6] para ambos ejes . e .; el rango de rotación global alcanzado por las máscaras es de [−π,π], utilizando pasos discretos de 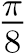
| Base de datos | A | T | L | R | W | D |
| DB1_B | - | - | 2 | 4 | 4 | - |
| DB2_B | - | - | 2 | 4 | 4 | - |
| DB3_B | 2 | 1 | 4 | 2 | - | 1 |
| DB4_B | 1 | - | 3 | 3 | 1 | 2 |
En la Tabla 1 se utilizan las siguientes iniciales para representar las diferentes topologías de huellas propuestas para este estudio, A (arco), T (arco tendido), L (lazo izquierdo), R (lazo derecho), W (espiral) y D (doble lazo).
La descripción de los parámetros evolutivos empleados para cada uno de los experimentos es especificada en la Tabla 2. La Figura 3 muestra el comportamiento de las diferentes configuraciones genéticas utilizadas de acuerdo a su función de ajuste, así como el óptimo alcanzado por el algoritmo ávido propuesto en [7], el cual se tomó como referencia para el siguiente análisis.
| Serie | Generaciones | Población | Cruzamiento | Mutación | Particiones |
| 1 | 1000 | 100 | 1.0 | 0.13 | 10 |
| 2 | 1000 | 50 | 0.5 | 0.13 | 10 |
| 3 | 1000 | 100 | 0.5 | 0.13 | 10 |
| 4 | 1000 | 30 | 0.5 | 0.13 | 10 |
![Comportamiento obtenido por las series expuestas en la Tabla 2. Los puntos etiquetados se corresponden con el mejor resultado ofrecido por las diferentes configuraciones genéticas y el óptimo logrado por el algoritmo ávido propuesto en [7].](../673870834005_gf6.png)
Figura 3.
Comportamiento obtenido por las series expuestas en la Tabla 2. Los puntos etiquetados se corresponden con el mejor resultado ofrecido por las diferentes configuraciones genéticas y el óptimo logrado por el algoritmo ávido propuesto en [7].
A continuación, se muestran algunos análisis realizados producto de la ejecución de los diferentes algoritmos propuestos. En lo adelante, se denota como TS a la primera propuesta analizada en el Epígrafe 2.1; se define como CLMM a la propuesta descrita en el Epígrafe 2.2 utilizando como conjunto de máscaras prototipos, aquellas definidas en [5] como ideales para las cinco clasificaciones de huellas dactilares propuestas en dicho estudio; por último, se define como CLMM* a la aplicación del procedimiento anterior, empleando para ello el conjunto de máscaras prototipos generadas por el algoritmo descrito en el Epígrafe 2.2.2 para la construcción de las máscaras dinámicas. Según los resultados expuestos, los mejores ajustes son obtenidos por la estrategia dinámica especificada en [7], por lo cual se emplea esta, en lugar del algoritmo genético sugerido en [5].
El proceso de indexación de huellas dactilares se rige por una serie de parámetros que cuantifican la eficiencia y calidad de la indexación aportada por cada uno de los métodos evaluados. A continuación, se detallan los rasgos que permiten apreciar el tiempo de respuesta y la estabilidad de las estrategias de búsqueda propuestas en este estudio.
Índice de penetración. Dicha medida es comúnmente utilizada para cuantificar el rendimiento de los sistemas de clasificación y la misma influye directamente en el tiempo de respuesta del proceso. Se define como se muestra en la Ecuación 6:
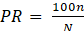 (6)
(6)sean .: número de huellas revisadas, y .: total de huellas presentes en el banco de datos. Este indicador se mide en una escala del [0,100]%.
Tiempo de respuesta. Se define como se muestra en la Ecuación 7:
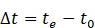 (7)
(7)sean t.: tiempo en el que la acción culmina, y ..: instante inicial de la operación. Usualmente es medido en milisegundos (ms) o segundos (s).
Tasa de error. Representa la razón entre el número de huellas mal clasificadas y el número total de muestras empleadas para la prueba. Se define como se muestra en la Ecuación 8:
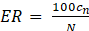 (8)
(8)sean c.: la cantidad de huellas mal clasificadas, y .: el total de impresiones del conjunto de prueba. Este indicador se mide en una escala del [0,100]%. Suele expresarse en función del índice de penetración.
Durante el análisis exploratorio para el algoritmo en cuestión se definen los siguientes indicadores de rendimiento:
-
ER100 (el menor PR para un ER ≤ 1%).
-
ER1000 (el menor PR para un ER ≤ 0,1%).
-
Gráfica [ER × PR].
-
IS (el promedio del PR para el escenario de búsqueda incremental). En tal escenario no existen errores de retorno, en el peor de los casos, la búsqueda es extendida a todo el banco de datos, y el PR promedio es reportado como un indicador de rendimiento simple.
-
Tiempo de enrolamiento promedio (µe).
-
Tiempo de indexación promedio (µx).
Teniendo en cuenta la distribución de huellas por clases dada en la Tabla 1, se utiliza el conjunto de máscaras dinámicas asociadas a las topologías de huellas encontradas para cada una de las bases de datos utilizadas. Los indicadores de IS, ER100y ER1000, presentan iguales valores dado el pequeño número de huellas con las que cuentan las bases de datos empleadas en las pruebas, por tal motivo, estos se tratan como un todo en los resultados expuestos. Otros valores de interés, son el tiempo de enrolamiento e indexación promedio, definidos como µ. . µx, respectivamente.
En la Tabla 3 se muestran algunas estadísticas calculadas a partir de las pruebas realizadas sobre el banco de datos de la FVC2000 perteneciente al conjunto . de la misma.
| Base de datos FVC2000 | Estrategia | IS | µx (ms) | µe (ms) |
| DB1_B | TS | 38.271 | 686.579 | 543.658 |
| CLMM | 65.432 | 155.165 | 61058.250 | |
| CLMM* | 54.320 | 255.903 | 50593.437 | |
| DB2_B | TS | 44.737 | 1198.080 | 449.584 |
| CLMM | 54.320 | 182.343 | 1961.548 | |
| CLMM* | 58.025 | 2050.548 | 284.950 | |
| DB3_B | TS | 55.560 | 4636.166 | 892.520 |
| CLMM | 50.000 | 359.865 | 130173.850 | |
| CLMM* | 61.250 | 465.698 | 101888.012 | |
| DB4_B | TS | 85.185 | 351.295 | 315.712 |
| CLMM | 43.210 | 202.550 | 47203.875 | |
| CLMM* | 43.210 | 282.297 | 66022.437 |
Según los resultados obtenidos durante las pruebas, el algoritmo TS ofrece mejor tasa de penetración (PR) que los restantes en dos de las cuatro pruebas realizadas, así como un tiempo de enrolamiento mínimo en el total de las pruebas ejecutadas. Por otro lado, el tiempo de indexación mostrado por el algoritmo CLMM constituye el mejor resultado de las pruebas, ello es debido a que este algoritmo emplea un conjunto de máscaras más pequeño que la propuesta CLMM*; sin embargo, cuenta con los peores tiempos de enrolamiento para la mayoría de las pruebas ejecutadas (3.4).
En la Figura 4 se describe el comportamiento de las tres propuestas antes mencionadas para las cuatro bases de datos analizadas. Las dos implementaciones probadas CLMM y CLMM*, manifiestan tasas de penetración ligeramente similares, siendo la primera de estas, la que en mayor cantidad de ocasiones coloca los mejores resultados (3.4), llegando a superar las tasas de penetración resultantes de la estrategia TS en dos de las cuatro ocasiones. Además, se constata el correcto funcionamiento de la estrategia CLMM* para la mayoría de las bases de datos de prueba (3.4), en las cuales esta ofrece un mejor comportamiento global con respecto a la propuesta CLMM.
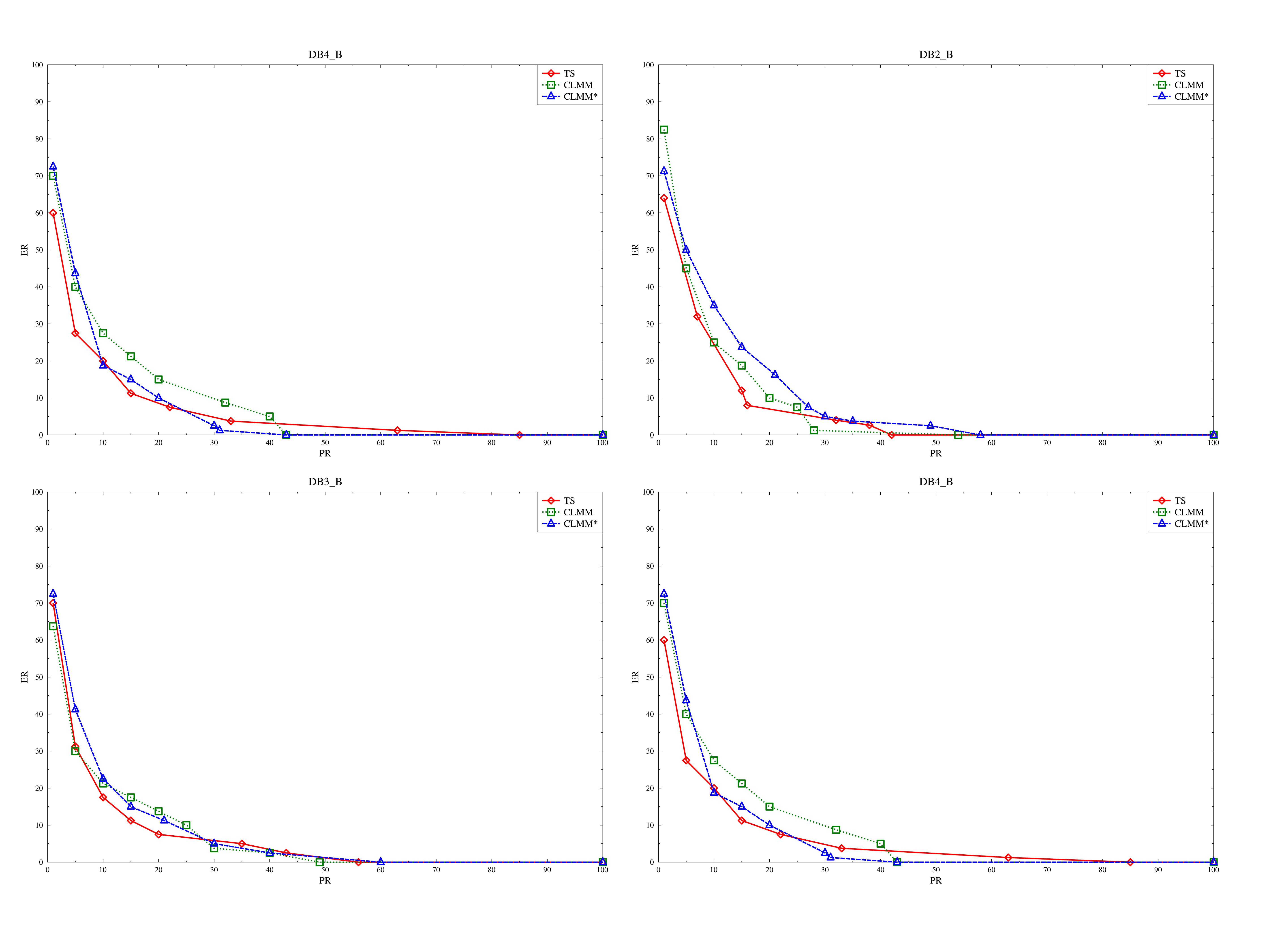
Figura 4.
Resultados de la ejecución de los algoritmos TS, CLMM y CLMM* sobre el banco de datos de la FVC2000 DB1_B, DB2_B, DB3_B y DB4_B de izquierda a derecha y de arriba hacia abajo respectivamente.
Conclusiones
De los resultados mostrados, su análisis y discusión, se pueden obtener las siguientes conclusiones sobre las estrategias de indexación propuestas. La utilización de características globales para la indexación de huellas dactilares garantiza reducir en al menos un 53.24 % el número de comparaciones realizadas durante el proceso de búsqueda de un AFIS. Los tiempos de ejecución del procedimiento de indexación utilizando máscaras dinámicas se mantienen aceptables, garantizando rapidez durante la búsqueda del AFIS. La estrategia de búsqueda en árbol para la comparación inexacta de grafos ofrece un balance aceptable entre rapidez y efectividad durante el proceso de indexación de huellas dactilares. Su comportamiento posee valores de similitud comparables con aquellos obtenidos por otras estrategias metaheurísticas utilizadas con propósitos similares. El procedimiento semiautomático para la generación de máscaras dinámicas, aporta fluidez al proceso de indexación y requiere poca intervención humana, garantizando tasas de error similares a aquellas aportadas por la generación manual de las mismas. La utilización de un mayor número de máscaras dinámicas no siempre garantiza la obtención de mejores resultados en el proceso de indexación abordado. El empleo de estrategias que utilicen el campo de orientación de la huella dactilar como única característica de entrada, no permite alcanzar tasas de penetración lo suficientemente adecuadas para garantizar la rapidez en el proceso de identificación de un AFIS, de acuerdo a los resultados actuales alcanzados a nivel internacional en dicha área.
Referencias
[1] D. Maltoni, D. Maio, A. K. Jain, and S. Prabhakar, Handbook of fingerprint recognition. Springer Science & Business Media, 2009.
[2]. M. H. Bhuyan, S. Saharia, and D. K. Bhattacharyya, “An effective method for fingerprint classification,” arXiv preprint arXiv:1211.4658, 2012.
[3] S. U. Maheswari and E. Chandra, “A review study on fingerprint classification algorithm used for fingerprint identification and recognition,” IJCST, vol. 3, no. 1, pp. 739–744, 2012.
[4] D. Parekh and R. Vig, “Review of Parameters of Fingerprint Classification Methods Based on Algorithmic Flow,” presented at the International Conference on Advances in Computing and Information Technology, 2011, pp. 28–39.
[5] R. Cappelli, A. Lumini, D. Maio, and D. Maltoni, “Fingerprint classification by directional image partitioning,” IEEE Transactions on pattern analysis and machine intelligence, vol. 21, no. 5, pp. 402–421, 1999.
[6] A. Lumini, D. Maio, and D. Maltoni, “Continuous versus exclusive classification for fingerprint retrieval,” Pattern Recognition Letters, vol. 18, no. 10, pp. 1027–1034, 1997.
[7] D. Maio and D. Maltoni, “A structural approach to fingerprint classification,” presented at the Proceedings of 13th International Conference on Pattern Recognition, 1996, vol. 3, pp. 578–585.
[8] M. Liu, X. Jiang, and A. C. Kot, “Efficient fingerprint search based on database clustering,” Pattern Recognition, vol. 40, no. 6, pp. 1793–1803, 2007.
[9] Y. Wang, J. Hu, and D. Phillips, “A fingerprint orientation model based on 2D Fourier expansion (FOMFE) and its application to singular-point detection and fingerprint indexing,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 4, pp. 573–585, 2007.
[10] M. Liu and P.-T. Yap, “Invariant representation of orientation fields for fingerprint indexing,” Pattern Recognition, vol. 45, no. 7, pp. 2532–2542, 2012.
[11] Ş. Parlakyıldız and F. Hardalaç, “A New and Effective Method in Fingerprint Classification,” Life Science Journal, vol. 10, no. 12, pp. 584–588, 2013.
[12]. R. M. Cesar Jr, E. Bengoetxea, I. Bloch, and P. Larrañaga, “Inexact graph matching for model-based recognition: Evaluation and comparison of optimization algorithms,” Pattern Recognition, vol. 38, no. 11, pp. 2099–2113, 2005.
[13] “FVC-onGoing.” [Online]. Available: https://biolab.csr.unibo.it/FVCOnGoing/UI/Form/Home.aspx. [Accessed: 08-Ene-2020].
[14] N. K. Ratha, S. Chen, and A. K. Jain, “Adaptive flow orientation-based feature extraction in fingerprint images,” Pattern Recognition, vol. 28, no. 11, pp. 1657–1672, 1995.
[15] B. G. Sherlock, D. M. Monro, and K. Millard, “Fingerprint enhancement by directional Fourier filtering,” IEE Proceedings-Vision, Image and Signal Processing, vol. 141, no. 2, pp. 87–94, 1994.
[16] S. Rizzi, “Genetic operators for hierarchical graph clustering,” Pattern Recognition Letters, vol. 19, no. 14, pp. 1293–1300, 1998.
[17] D. Maio, D. Maltoni, and S. Rizzi, “Topological clustering of maps using a genetic algorithm,” Pattern Recognition Letters, vol. 16, no. 1, pp. 89–96, 1995.
[18] C.-Y. Huang, L. Liu, and D. D. Hung, “Fingerprint analysis and singular point detection,” Pattern Recognition Letters, vol. 28, no. 15, pp. 1937–1945, 2007.
[19] A. Hernández and E. Martín, “Componente de indexación de huellas dactilares basada en características globales,” Universidad de las Ciencias Informáticas, 2014.[1]
[20] M. Van Kreveld, O. Schwarzkopf, M. de Berg, and M. Overmars, Computational geometry algorithms and applications. Springer, 2000.
Notas de autor
eomartin@uci.cu
Información adicional
Tipo de artículo: Artículos originales
Temática: Procesamiento de imágenes
Enlace alternativo
https://revistas.ulasalle.edu.pe/innosoft/article/view/17/8 (pdf)
https://revistas.ulasalle.edu.pe/innosoft/article/view/17 (html)
https://n2t.net/ark:/42411/s1/a17 (html)
https://purl.org/42411/s1/a17 (html)
https://revistas.ulasalle.edu.pe/innosoft/article/view/17/9 (html)