Resumen: Diversos estudios han comprobado que los niveles de violencia en los videojuegos pueden influir negativamente en el desarrollo de los niños, especialmente en la adolescencia y es por ello que se debe tener cuidado en que la clasificación sea la adecuada según el contenido presente. Para el análisis se utilizó la clasificación ESRB, que contiene 7 diferentes categorías, junto con la implementación de un modelo de árboles de decisión, que es una técnica de minería de datos capaz de representar gráficamente la relación entre las variables. Los resultados arrojaron que el nivel de precisión para un árbol de nivel 6 no supera el mínimo requerido.
Palabras clave: Árbol de decisión, ESRB, Minería de datos.
Abstract: Various studies have proven that the levels of violence in video games can negatively influence the development of children, especially in adolescence and that is why care must be taken that the classification is appropriate according to the content present. For the analysis, the ESRB classification was used, which contains 7 different categories, together with the implementation of a decision tree model, which is a data mining technique capable of graphically representing the relationship between the variables. The results showed that the precision level for a level 6 tree does not exceed the minimum required.
Keywords: Decision tree, Data mining, ESRB..
Artículos originales
Predicción de la clasificación ESRB para videojuegos según su contenido usando árboles de decisión
Predicting ESRB ratings for video games by content using decision trees
Universidad La Salle

Esta obra está bajo una Licencia Creative Commons Atribución 4.0 Internacional.
Recepción: 18 Diciembre 2022
Aprobación: 03 Febrero 2023
Publicación: 30 Marzo 2023
Los videojuegos se han convertido en un mercado crecimiento año a año, llegando a facturar más que la industria cinematográfica y de música a nivel global; desde su creación en 1962 por Steve Rusell, en el Massachusetts Institute of Technology inventando el Spacewar [1], ha ido mejorando en gráficos y mecánicas nuevas en busca de nuevos jugadores, pero también a todo su largo recorrido fue acompañado de polémicas por el tipo de contenido sin control que ofrecían.
Los videojuegos se definen [2] como programas informáticos que mantienen a los usuarios interactuando a través de imágenes que se muestran en dispositivos con pantallas de varios tamaños, a través de un incentivo implícito para ganar. Actualmente se están desarrollando videojuegos que pueden ser controlados por voz o movimiento, siendo un avance a como antes solo se podía controlar con los dedos u otros instrumentos adicionales (como guitarras, rifles y pistolas).
Los sistemas de clasificación previo a 1994 no existían, sin embargo, después del lanzamiento de algunos videojuegos en los años 90 como Funk, Buchman y principalmente por la polémica de Mortal kombat, causada por los elementos violentos que siempre tuvo la saga, se crea en Estados Unidos la Entertainment Software Rating Board (ESRB) con el fin de garantizar contenido adecuado a partir de diferentes parámetros [3].
Categorías de clasificación y su sugerencia de nivel de edad [4]:
-
EC Early Childhood: Contenido apto para niños de tres a diez años, no contiene material inapropiado.
-
E Everyone: Contenido apto para personas de seis años en adelante, contiene una mínima violencia, travesuras y lenguaje obsceno.
-
E10+ Everyone 10+: Contenido apto para mayores de diez años. Puede contener mayor cantidad de violencia de caricatura o temas sugestivos.
-
T Teen: Contenido apto para personas de trece años en adelante. Puede contener violencia, humor grosero y temas sugestivos con un mínimo de sangre.
-
M Mature: Contenido apto para personas de diecisiete años en adelante. Puede contener temas sexuales y lenguaje o violencia más intensa con derramamiento de sangre.
-
AO Adults Only: Contenido apto sólo para adultos de 18 años a más. Puede incluir contenido sexual gráfico o escenas prolongadas de violencia.
-
RP: La clasificación se encuentra en espera.
Además de esta metodología de clasificación de videojuegos ERP existen otras relevantes como son:
-
USK es la organización de clasificación de software utilizada en Alemania que viene a ser un tablero de clasificación bastante estricto, en parte debido a la paranoia del país entorno a los videojuegos con violencia, ya que existen distintos videojuegos que han sido prohibidos o han requerido que los desarrolladores editen o quiten ciertas funciones.
-
SMECCV es una clasificación mexicana orientada a las especificaciones gráficas para las advertencias, descriptores de contenidos y elementos interactivos que deberán implementar objetos, respecto de los videojuegos distribuidos, comercializados o arrendados en el territorio nacional. Con el objetivo de crear parámetros específicos que apoyen a desarrollar una adecuada categorización tanto el contenido de los mismos, así como de las personas a la que va dirigido.
-
CERO Computer Entertainment Rating Organization es una organización que clasifica la edad recomendada de los juegos en Japón, y fue fundada en 2002 como una división de "CESA".
-
GSRR es el sistema de clasificación de contenido de videojuegos utilizado en Taiwán, Hong Kong y sureste de Asia. La ley realizada el 6 de julio de 2006 y se enmendó el 29 mayo 2012.
Los padres tienden a preocuparse por el contenido del juego en especial si son violentos, ya que podrían afectar la conducta del niño. Según Russell N. Laczniak, Les Carlson, Doug Walker, y E. Deanne Brocato los ESRB pueden ayudar a que los niños jueguen juegos menos violentos y asimismo reducir la participación de los niños en comportamientos negativos en la escuela [5], [6].
En una investigación sobre consecuencias de los videojuegos en niños y adolescentes en aspectos de la vida social, muestra como posibles efectos psicológicos y fisiológicos pueden sufrir los menores, donde ahonda como el entregar un juego con contenido de acuerdo a su edad le puede evitar comportamiento agresivos, problemas de atencion, gasto energético, respuestas hormonales y entre otros el efecto negativo de la exposición prolongada a los videojuegos, tal como la llamada «epilepsia fotosensible» [7], [8].
Los árboles de decisión han sido utilizados en el aprendizaje, sirve para hallar una respuesta o curso de acción, dadas k variables o entradas, donde cada nodo suyo hace una pregunta sobre una variable; también se puede haber más de k preguntas antes de emitir una respuesta, por otro lado, las hojas o nodos finales “dan la respuesta” o decisión a tomar. El método usa una muestra de datos llamada generalmente conjunto de entrenamiento para formar el árbol, por lo cual resulta una buena opción para poder clasificar [9].
Este trabajo tiene como finalidad utilizar los árboles de decisión y la inteligencia que estos proveen para predecir la clasificación de los videojuegos según el contenido que presenten, tales como: sangre, lenguaje explicito, violencia, etc; en las diferentes categorías que tiene la ESRB, con el propósito de brindar ayuda al control de efectos negativos en menores de edad.
Son modelos precisos, estables y más sencillos de interpretar principalmente porque construyen unas reglas de decisión, las cuales se pueden representar usando un diagrama similar a un árbol. A diferencia de los modelos lineales conocidos, pueden representar relaciones no lineales para resolver problemas más diversos. En estos modelos, destacan los árboles de decisión y los random forest. Al ser más precisos y elaborados, obviamente ganamos en capacidad predictiva, pero perdemos en rendimiento [10].
Es una forma gráfica y analítica de representar todos los eventos o sucesos que pueden surgir a partir de una decisión asumida en cierto momento. Nos ayudan a tomar la decisión más “acertada”, desde un punto de vista probabilístico, ante un abanico de posibles decisiones tomando en cuenta cierta precisión. Estos árboles permiten examinar los resultados y determinar visualmente cómo fluye el modelo. Los resultados visuales ayudan a encontrar subgrupos específicos y relaciones que tal vez no se podría hallar con estadísticos más tradicionales [11].
-
DataSet: Un conjunto de datos corresponde a los contenidos de una única tabla de base de datos, donde cada columna del dataset representa una variable única, y cada fila está reemplazando a un miembro en concreto del conjunto de datos en la tabla. En un dataset tenemos todos los valores que puede tener cada una de las variables, como por ejemplo la sangre que se pueda visualizar y las agresiones que tengan dentro del juego. Cada uno de estas variables se conoce con el nombre de dato, también puede incluir datos para uno o más miembros en función de su número de filas [14].
-
Google Colab: Viene a ser una herramienta que nos da la posibilidad de ejecutar y compilar scripts del lenguaje Python a mediante los servidores de Google. Permitiéndonos ejecutar porciones de código similar a un cuaderno de Jupyter Notebook para linux. Orientado para implementar machine learning, ya que al ser una máquina virtual no se limita a los recursos de hardware. Teniendo en cuenta que se puede usar tanto el GPU y la TPU del mismo servidor de Google para poder potenciar el procesamiento del proyecto [15].
-
Python: Es un lenguaje 100% gratuito. Tratándose de un lenguaje open source siendo disponible para todas las plataformas. Ya que podemos instalarlo y ejecutarlo en diferentes sistemas operativos como Windows, Linux o MacOS [15].
Se usó para el desarrollo de este clasificador de ESBR usando un árbol de decisión, la cual comprende las siguientes fases:
-
La fuente de información fue un Dataset.csv, esto fue sacado de la página Kaggle.com, necesaria para poder construir un árbol de decisión utilizando las librerías sklearn, y se hizo uso de las funciones que nos brinda.
-
Análisis de Datos: con el dataset que se obtuvo, se vio la cantidad de información que tiene, y las variables. las clasificamos en números para su uso correcto con la librería o lenguaje que se trabajaría.
-
Modelado: Se escoge una técnica adecuada para poder desarrollar la clasificación.
-
Evaluación: Tuvimos que corroborar efectivamente que el modelo escogido se ajuste a lo que estamos buscando, en este caso poder clasificar según ESBR y que pueda ser modificado en el futuro.
A continuación se muestran una serie de artículos que se han analizado para poder desarrollar nuestro trabajo, se procederá a hablar brevemente sobre los puntos que nos sirvieron de apoyo.
Algoritmos de aprendizaje automático para análisis y Predicción de datos
Sandoval [10] expone sobre la técnica de Machine Learning, rama de la inteligencia artificial, como elemento fundamental de la ciencia de datos, así como tipos de aprendizaje, diferentes métodos que son utilizados para la predicción de los mismos y la fase de desarrollo hasta su presentación.
Se obtuvo una fundamentación teórica para el modelado del proyecto, además brinda información sobre cómo cual método de predicción podría ser más factible.
Cómo aplicar árboles de decisión en SPSS
Complemento al trabajo anterior se tiene el realizado por Berlanga, Rubio y Vilà [11] donde explica como funciona un árbol de decisión como parte de la minería de datos, usos del mismo y terminología relacionada; se presenta una información más específica en contraste con el anterior.
Predicción del consumo de cocaína en adolescentes mediante árboles de decisión
Gervilla y Palmer [12] presentan un estudio sobre cómo implementar técnicas de Data Mining, especialmente árboles de decisión, que permitan analizar el valor predictivo de la impulsividad y la búsqueda de nuevas sensaciones sobre consumo de cocaína y/u otras sustancias, principalmente en la etapa de la adolescencia, partiendo de la suposición que los rasgos anteriormente mostrados evidencian una marcada relación con las conductas de experimentación y la adicción a ciertas sustancias.
Predicción, análisis y pronóstico de covid-19 utilizando un modelo de árbol de decisión
Otro ejemplo desarrollado es la tesis de Castellanos y Haro [13], donde elaboran un modelo de aprendizaje automático basado en IA, utilizando un utilizando algoritmo de aprendizaje supervisado, árbol de decisión. Además, la creación y estructuración de una base de datos que les permitió predecir, analizar y pronosticar el grado de afectación en los pacientes contagiados de Covid-19.
Teniendo en cuenta las fases del Machine Learning, se tiene lo siguiente:
El dataset contiene contienen el nombre de 1895 juegos con 34 características de contenido de calificación ESRB con el nombre y la consola como características para cada juego.
Un solo punto de datos se representa como un valor binario 0-1 para la consola y un vector binario para las características del contenido de ESRB.
Variables de entrada
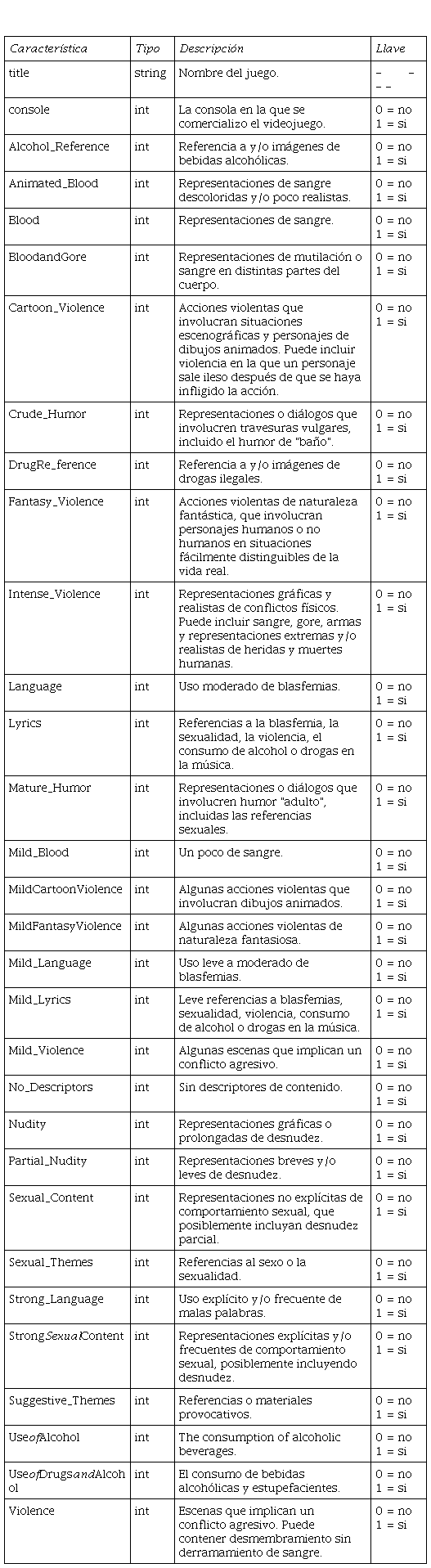
Variable de salida
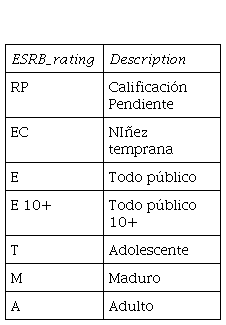

Fig. 1.

Fig. 2.
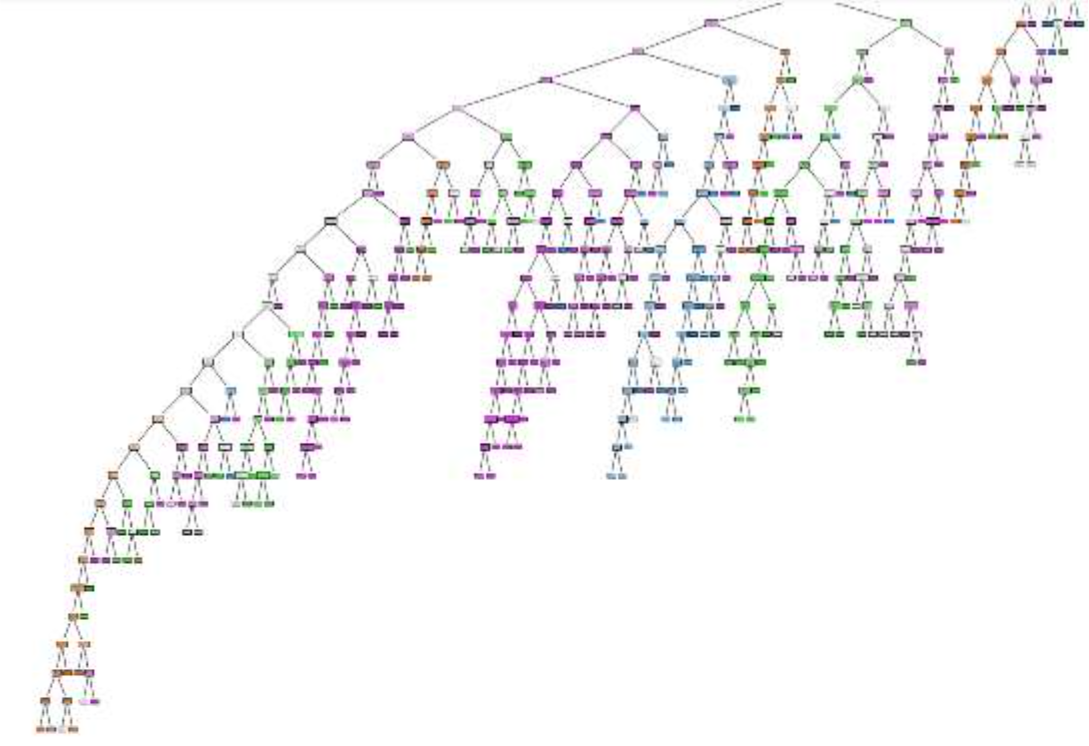
Fig. 3.
En esta fase se tiene una cantidad enorme de datos, de la cual separamos una parte para entrenar al algoritmo y darle toda esta información para que encuentre los patrones necesarios y después pueda hacer predicciones.
El resto de los datos que quedan, se van a utilizar para hacer las pruebas. Así podemos desarrollar algunas preguntas al algoritmo y evaluar si las respuestas están bien o mal, y saber si está aprendiendo o no. Si vemos que no llegan a coincidir los datos, se tiene que añadir más datos o cambiar el método que se esta utilizando. Pero si se observa que hay entre un 70% a 90% de respuestas correctas, podemos decir que hay un buen grado de aprendizaje y poder utilizar este algoritmo.
Como se observa en la Figura la precisión después de la fase de entrenamiento es de 0.71 en 6 niveles y completo es de 0.86. A continuación, se muestra una comparación entre los árboles arrojados.
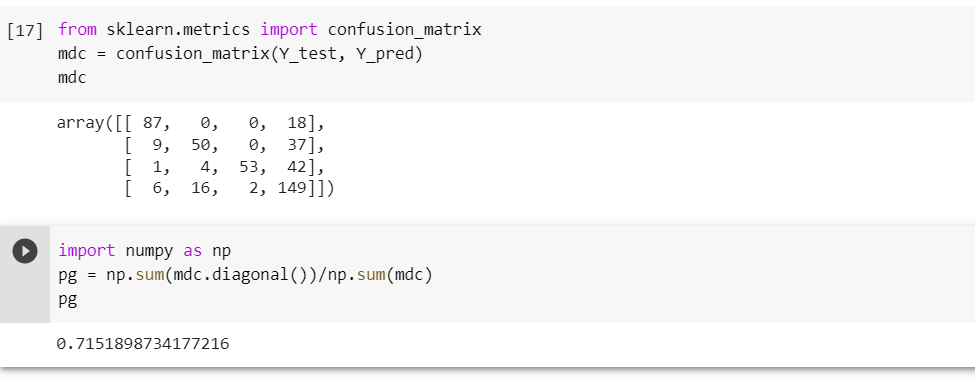
Fig. 4.
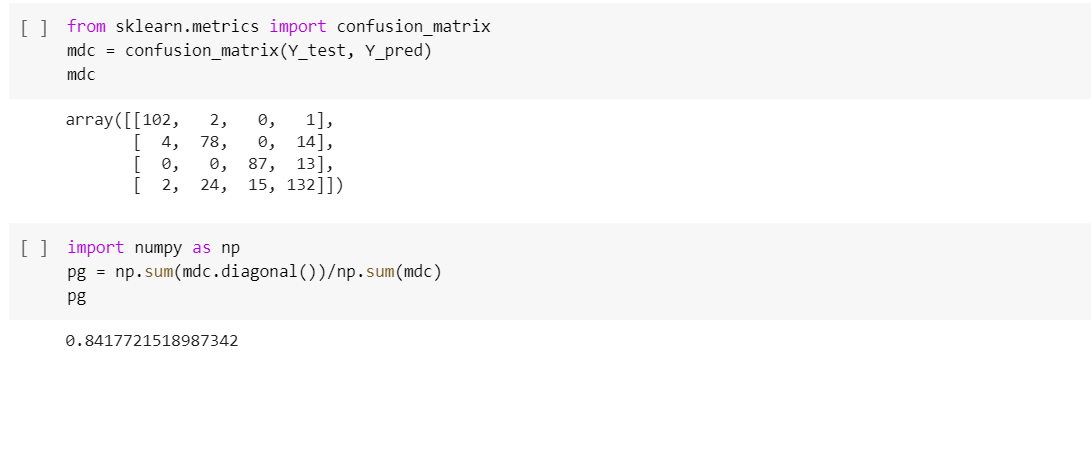
Fig. 5.
Los resultados obtenidos con el modelo de clasificación por árboles de decisión, indican que este es capaz de generar modelos consistentes con la realidad observada y el respaldo teórico, basándose únicamente en los datos obtenidos por el DataSet, con una precisión del 0,71 que depende de la cantidad de datos de entrenamiento que se le proporciona.
Como trabajos futuros se plantea utilizar otros clasificadores para comparar con estos resultados, además de ver que tan efectivo sería nuestro modelo, y para aumentar el porcentaje de evaluación se podría utilizar tanto un dataset que contenga más pruebas como otras técnicas de machine learning o aplicar tareas descriptivas de minería de datos como asociación y agrupación, con el fin de encontrar relaciones y similitudes.
https://colab.research.google.com/drive/1E1K12bAVVTXY77fkcidt6Rb8Gc49N6c5?usp=sharing#scrollTo=pNKE5qVR7sGs
https://www.kaggle.com/datasets/imohtn/video-games-rating-by-esrb
Rodrigo Sebastián Huamán Maqque: Conceptualización, Curación de datos, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Graciela Condori Anahua: Conceptualización, Curación de datos, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Fátima Gigi Rojas Carhuas:Conceptualización, Curación de datos, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Rodolfo Robert Quispe Huacho: Conceptualización, Curación de datos, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Tipo de artículo:: Artículos originales
Temática:: Inteligencia Artificial
Variables de entrada
Variable de salida
Fig. 1.
Fig. 2.
Fig. 3.
Fig. 4.
Fig. 5.
