Artículos originales
Uso de las redes neuronales para determinar la calificación de una aplicación publicada en Google Play Store
Use of neural networks to determine the rating of an application published in the Google Play Store
Uso de las redes neuronales para determinar la calificación de una aplicación publicada en Google Play Store
Innovación y Software, vol. 4, núm. 1, pp. 161-197, 2023
Universidad La Salle

Esta obra está bajo una Licencia Creative Commons Atribución 4.0 Internacional.
Recepción: 05 Febrero 2023
Aprobación: 13 Marzo 2023
Publicación: 30 Marzo 2023
Resumen: La inteligencia artificial es la combinación de algoritmos escritos en forma de código computacional con el fin de que se ejecuten en una computadora para emular comportamientos similares a la inteligencia humana. En este trabajo, se buscará el uso de las redes neuronales, las cuales son parte de la inteligencia artificial y, nos permiten solucionar problemas de predicción. Se modificará un dataset basado en las descargas de aplicaciones de Google Play Store y sus características y se procesará la información para obtener información de salida.
Palabras clave: Redes neuronales, numpy, flujo tensorial, valores perdidos, valores atípicos.
Abstract: Artificial intelligence is the combination of algorithms written in the form of computer code in order to be executed on a computer to emulate behaviors similar to human intelligence. In this work, the use of neural networks will be sought, which are part of artificial intelligence and allow us to solve prediction problems. A dataset based on Google Play Store app downloads and their features will be modified and the information processed to obtain output information.
Keywords: Neural networks, numpy, tensorflow, missing values, outliers..
INTRODUCCIÓN
La inteligencia artificial es la combinación de algoritmos escritos como código computacional con el fin de que las computadoras en donde se ejecuten estos códigos ejecuten comportamientos similares a la inteligencia humana. Desde su invención, ha tenido muchas aplicaciones. Las aplicaciones que se le pueden dar a la Inteligencia Artificial han estado incrementando en casi todos los dominios de la vida humana desde los sistemas de recomendación para compras, gestión de inventarios y aspectos logísticos hasta la solución de problemas de salud [1].
Existe un gran número de problemas dentro de la ingeniería en los cuales se puede aplicar Inteligencia Artificial pero debido a la naturaleza de los datos con los que se trabaja no se puede tratar de las formas tradicionales. Esto tardó ya que recién en los años 70 entendieron el hecho de que era imposible el manejo de los millones de combinaciones posibles necesarias para poder evaluar situaciones reales, esto debido al infinito número de perturbaciones que pueden existir dentro de una sola situación [2]. Las redes neuronales son sistemas de procesamiento de información, que a su vez son reconocidas como un paradigma matemático de computación. Son ampliamente utilizadas en diversos ambientes teóricos y prácticos, son un conjunto de unidades llamadas neuronas artificiales conectadas [3].
Como un problema relacionado con los aspectos logísticos está relacionado con el desarrollo de software para móviles y si una empresa que inicia puede saber si una aplicación va a ser exitosa o no podría condicionar el desarrollo, evitando pérdidas económicas o buscando mayores ganancias al redefinir el proyecto. Estudios realizados por diferentes organizaciones demuestran que la tasa de éxito de los proyectos está alrededor del 32%, y de proyectos fallidos alrededor del 24% [4].
A través de este proyecto se busca predecir a partir de factores vinculados al software desarrollado , que calificación se puede obtener al ser puesto al público, a través de Google Play, que es la tienda de aplicaciones creada por Google donde puedes encontrar juegos, películas, música, libros y más, la cual está disponible para cualquier dispositivo móvil que cuente con sistema operativo Android [5], aunque hay estudios que aclaran que la calificación de una aplicación no necesariamente indica que será la más popular [6].
Para lograr tal fin, se usará una de las herramientas de la inteligencia artificial la cual son las redes neuronales, porque son un método de resolver problemas, por ejemplo, el mapeo autoorganizado suelen ser utilizado como herramienta para la predicción de tendencias y como clasificador de conjuntos de datos. [7]. Las cuales consisten en unidades de procesamiento interconectadas de manera densa, llamadas neuronas; una de sus características más importantes es la capacidad del aprendizaje adaptativo mediante datos dados, además pueden ser combinadas con otras herramientas como la lógica difusa, los algoritmos genéticos o los sistemas expertos [8].
Marco Teórico
Logística
Para Ferrel, Hirt, Adriaenséns, Flores y Ramos, la logística es "una función operativa importante que comprende todas las actividades necesarias para la obtención y administración de materias primas y componentes, así como el manejo de los productos terminados, su empaque y su distribución a los clientes"[9]
Redes neuronales
Las redes neuronales simulan la estructura y el comportamiento del cerebro, usan lo que se conoce como procesos de aprendizaje para dar solución a los problemas para los que fueron programadas; son un conjunto de algoritmos matemáticos que encuentran las relaciones no lineales entre conjuntos de datos; suelen ser utilizadas como herramientas para la predicción de tendencias y como clasificadoras de conjuntos de datos.[18]
Se denominan neuronales porque están basadas en el funcionamiento de una neurona biológica cuando procesa información.[10]
Data Cleaning
Se conoce como al proceso que se encarga de corregir los errores en los datos, se convierte por tanto en un mecanismo necesario para que las estadísticas, los informes y en última instancia las decisiones que se tomen por los directivos sean confiables, pues en la medida en que esté garantizada la calidad de los datos, así mismo habrá seguridad y fiabilidad en las acciones posteriores que se produzcan a partir de su análisis.[11]
Data Set
Un Dataset no es más que un conjunto de datos tabulados en cualquier sistema de almacenamiento de datos estructurado. El término hace referencia a una única base de datos de origen, la cual se puede relacionar con otras, cada columna del Dataset representa una variable y cada fila corresponde a cualquier dato que estemos tratando[12]
Red Neuronal Secuencial
Una red neuronal sequential es un tipo de modelo de red neuronal que se conforma por capas de neuronas, cada capa se agrega una después de la otra. La metodología usada durante la construcción del modelo es paso a paso y trabajando en una sola capa en un momento determinado.
Herramientas
Colab Research
Es una herramienta para escribir y ejecutar código Python en la nube.de Google. También es posible incluir texto enriquecido, “links” e imágenes. En caso de necesitar altas prestaciones de cómputo, el entorno permite configurar algunas propiedades del equipo sobre el que se ejecuta el código.[13]
Python
Python es un lenguaje de programación de alto nivel que se utiliza para desarrollar aplicaciones de todo tipo. A diferencia de otros lenguajes como Java o .NET, se trata de un lenguaje interpretado, es decir, que no es necesario compilarlo para ejecutar las aplicaciones escritas en Python, sino que se ejecutan directamente por el ordenador utilizando un programa denominado interpretador, por lo que no es necesario “traducirlo” a lenguaje máquina.[15]
TensorFlow
Tensor Flow es una biblioteca de software de código abierto para computación numérica, que utiliza gráficos de flujo de datos. Los nodos en las gráficas representan operaciones matemáticas, mientras que los bordes de las gráficas representan las matrices de datos multidimensionales (tensores) comunicadas entre ellos.
Tensor Flow es una gran plataforma para construir y entrenar redes neuronales, que permiten detectar y descifrar patrones y correlaciones, análogos al aprendizaje y razonamiento usados por los humanos.[16]
Keras
Keras es una biblioteca que funciona a nivel de modelo: proporciona bloques modulares sobre los que se pueden desarrollar modelos complejos de aprendizaje profundo. A diferencia de los frameworks, este software de código abierto no se utiliza para operaciones sencillas de bajo nivel, sino que utiliza las bibliotecas de los frameworks de aprendizaje automático vinculadas, que en cierto modo actúan como un motor de backend para Keras.[17]
Métodos y Metodología computacional
Se usó para el desarrollo de este detector de sitios web fraudulentos usamos el modelo CRISP-DM, la cual comprende de seis fases: análisis del problema, análisis de Datos, preparación de los Datos, modelado, evaluación y explotación [10].
-
La fuente de información fue un Dataset.csv, esto fue sacado de internet con datos reales, para poder construir un árbol de decisión utilizando las librerías sklearn, y se hizo uso de las funciones que nos brinda.
-
Análisis del problema: Identificamos qué tipos de clasificación tendrán las páginas que se van a probar, viendo que pueden ser tres, y también identificamos la información necesaria para poder hacer esta clasificación.
-
Análisis de Datos: con el dataset que obtuvimos, vimos que cantidad de información tiene, y las variables lingüísticas las clasificamos en números para su uso correcto con la librería que se trabajaría.
-
Preparación de Datos: Se hizo una limpieza del dataset, con las funciones que nos brinda la libre, como eliminación de campos vacíos, datos irrelevantes.
-
Modelado: Seleccionamos la técnica adecuada para poder hacer la clasificación.
-
Evaluación: Tuvimos que corroborar efectivamente que el modelo escogido se ajuste a lo que estamos buscando, en este caso poder clasificar los diferentes sitios web.
Resultados y Discusión
Análisis del Problema
Los datos de las aplicaciones de Play Store tienen un enorme potencial para impulsar a las empresas para la creación de aplicaciones exitosas.
Por lo cual pretendemos realizar una red neuronal que permita la predicción de ratings usando como datos de entrenamiento una fuente de datos provenientes de un dataset recolectado de las descargas de la Google Play Store, este consiste en datos extraídos de la web de 10,000 aplicaciones de Play Store.
Análisis de los Datos
Fase de data cleaning:
El dataset posee 13 variables (columnas) las cuales son: App, Category, Rating, Reviews, Size, Installs,Type, Price, Content Rating, Genres, Last Updated, Current Ver y Android Ver. Se cuenta con 10841 filas. Luego de la descarga del dataset se procedió al análisis para eliminar los valores missing.
Fase de Transformación:
En la fase de transformación, en la sección Genre se detectó que existían datos múltiples valores en la variable, pues esta variable proveía mas de un valor en sus celdas, por lo que se decidió dividir la cadena en dos tokens usando el símbolo “;” y quedándonos con el primer token obtenido.
En el caso de la variable “Content Rating”,”Category”, se decidió conservar cada uno de sus datos para la codificación. Mientras que para las variables “Last Updated”, se procedió a la transformación de sus valores restando la fecha indicada en la fila y el año de publicación aproximado del dataset. La variable “Android Ver”, se transformó en un número de tipo float, debido a que el orden de precedencia de las versiones esta determinado por la posición que ocupa. Con respecto a la variable “Size”, se quitó y transformó cada valor por el sufijo que tuvo al final. Por ejemplo si el valor es “233k”, entonces esto indicaría que debemos multiplicar 233*0.001, mientras que si se tenía “233M”, se conservaría igual, en síntesis, se transformó y se puso en una misma unidad de medida en la variable “Size”. Con respecto a la variable “Installs” se transformó a números enteros y se les redimensiona a un valor general que es el valor actual entre 100,000.
Cabe destacar que todos los valores “Varies with Device” en las filas de “Android Ver”, “Size”, entre otras, fueron eliminadas pues no representan una gran cantidad de datos y se decidió eliminarlas debido a la falta de datos que este valor provee.
Fase de eliminación de Outliers:
Para la fase de eliminación de outliers se procedió a identificar los cuartiles de los datos que fueron convertidos en la anterior fase. El método usado para la eliminación de outliers que se usó fue la eliminación por el valor máximo y mínimo dados por el Método Caja y Bigotes.
En el cual se determina que el valor máximo y minimo estan dados en la siguiente formula:
máximo = q3+(1.5*iqr)
mínimo = q1+(1.5*iqr)
Donde “q1” es el cuartil que divide a los datos en 25% y 75%. Mientras que “q3”, representa el tercer cuartil representa que los valores por debajo de ese valor son el 75% de los datos. Con respecto a “iqr”, es la diferencia entre el tercer cuartil y el primero. Los valores de máximo y mínimo son los valores que nos ayudarán a identificar los outliers de nuestra gráfica de Caja y Bigotes.
Se procedió a reemplazar(en algunos casos eliminar) a los valores outliers con la media del total de valores, de esta manera no afectamos al balance de los datos y por lo tanto se conservó los demás atributos de esas filas para el entrenamiento de nuestro modelo Secuencial de red Neuronal.
Fase de creación de red neuronal:
En esta fase se identifican cada uno de los valores como “Categórico” o “Continuo”, por lo tanto las variables “Content Rating”,”Category” se consideran categóricos mientras que las variables “Android Ver”, “Installs”,”Reviews” son considerados valores continuos, pues los valores pueden incrementar o disminuir, pero no se mantienen en un rango fijo de valores a los cuales es posible clasificarlos.
Luego de este análisis, se procedió a categorizar todos los valores como una variable en específico, es decir todos los valores categóricos han sido puestos como características propias de la Aplicación. De este modo si hay las características categóricas A,B y C, se le asigna este tipo de codificación a sus valores:
| Nombre de la Aplicación | A | B | C |
| App A | 1 | 0 | 0 |
La tabla anterior representa que la aplicación “App A” tiene la característica A, y no tiene las características B y C. Esto beneficia al modelo Secuencial, pues los valores altos o secuenciales 1,2,3,4,5 pueden afectar a los pesos de cada neurona. Por lo tanto este modelo de codificación tendrá más precisión a la horade entrenar nuestro modelo de red neuronal.
Preparación de los datos
Los valores missings se trataron asi:
- A continuación se muestran la tabla de variables que contienen valores missing y sus respectivos porcentajes:
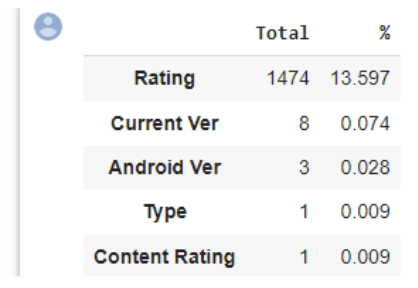
Fig. 1.
- Luego de eliminar los valores missing en la variable objetivo “Rating”, es muestra los valores missing restantes:
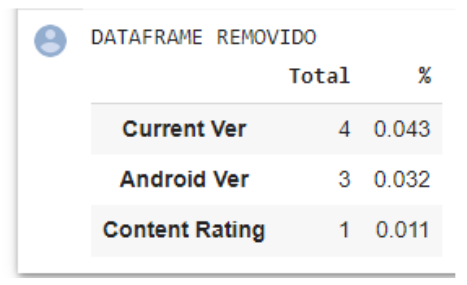
Fig. 2.
- Se eliminan los otros missing Values
- Se observa las filas anteriores con respecto las nuevas filas sin valores missing:

Fig. 4.
Se procede a un análisis de las columnas a utilizar
-
'App' : No se utilizara porque es el nombre
-
'Category': Si se utilizara
-
'Rating': Es nuestro OUTPUT
-
'Reviews': Si se utilizara
-
'Size': Si se utilizara
-
'Installs': Si se utiliza
-
'Type': No se utilizara porque la mayoría son valores Free
-
'Price': No se utilizara porque la mayoría son valores 0
-
'Content Rating': Si se utilizara
-
'Genres': No se utilizara porque era redundante respecto a Category.
-
'Last Updated': Se utilizara
-
'Current Ver': No se utilizará porque es un valor subjetivo dependiendo del creador de la App.
-
'Android Ver': Se utilizara
En este sentido las únicas variables a usar son: Reviews, Category, Rating,Size, Installs, Content Rating, Last Updated, Current Ver, Android Ver.
Se arreglan los datos de algunas columnas
- Al ya haber realizado la obtención de los datos, se deben analizar cuáles requieren de una transformación para que sean útiles.
- Para arreglar los datos del campo Size debemos convertir todos sus datos a la misma base, en este caso serían kilobytes, para ello se asigna un valor para poder convertir los datos a esta base, y esta acción se repite en todas los registros de la tabla eliminando el carácter y transformando el dato en un float y reemplazandolo en la tabla.

Fig. 5.
- Ahora también existe un valor no numérico “varies in device” que básicamente indica que el tamaño depende del dispositivo en el cual se instale la aplicación evaluada, debido a que no debemos indagar el peso de la aplicación en otra fuente, debemos descartar estos y para eso tenemos un else dentro del bucle que contabiliza cuantas veces se repite este valor en el campo Size de la tabla

Fig. 6.
- Después de haber evaluado cada fila de la tabla se nos muestra la siguiente información y los datos ya registrados como floats de 64 bits
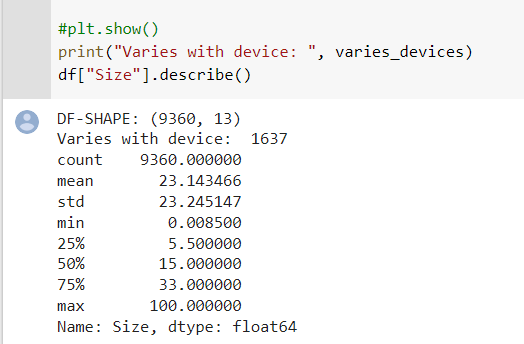
Fig. 7.
- Como ya se ha evaluado toda la tabla ya tenemos una vista más limpia de los datos de el campo Size con datos numéricos y ya retirados los valores “varies in device”
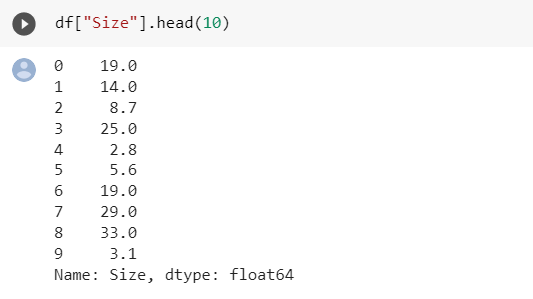
Fig. 8.
- Para arreglar los datos del campo Installs, lo que se requiere es eliminar el signo “+”, además que en algunos casos se están trabajando con números demasiado grandes, por lo que convendría reducirlos para no ocupar tanto espacio por el tamaño de los números

Fig. 9.
- Para lo cual se ha tomado como base el valor de 100.000 para poder reducir el tamaño de los valores originales. logrando así reducir espacio, y al retirar el símbolo “+” se establecen como floats de 64 bits

Fig. 10.
- Como ya se ha evaluado toda la tabla ya tenemos una vista más limpia de los datos de el campo Installs con datos numéricos más manejables
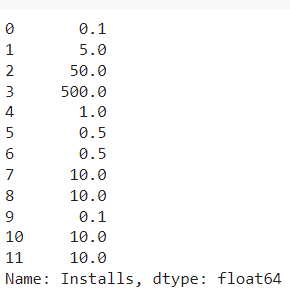
Fig. 11.
- Ahora en el caso del campo Reviews, lo único que se hace es establecer el tipo del campo como floats ya que los datos originales de por sí son manejables y no requieren mayor conversion

Fig. 12.
- Aquí se ve ya convertido a float los datos iniciales
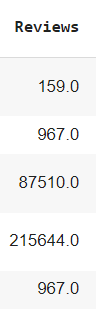
Fig. 13.
- Para el caso de Genres el obstáculo que tenemos es que algunos registros poseen más de un géneros y no podemos clasificar las fusiones de géneros para realizar análisis, afortunadamente cuando es más de un género en el registro están separados por un “;” por lo que este será el límite para separar dichas fusiones obteniendo todos los valores diferentes dentro de la tabla.

Fig. 14.
- Luego de hallar todos los valores diferentes pasamos a separar las fusiones en elementos individuales y así obtenemos los géneros únicos
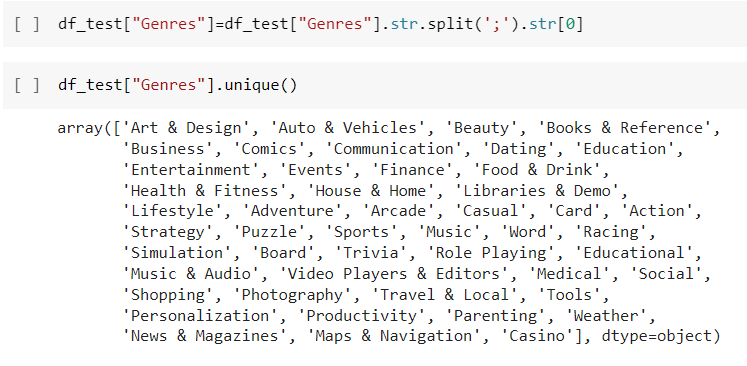
Fig. 15.
- Ya habiendo obtenido los géneros individuales ya se puede realizar un conteo de registros coincidentes con cada género.
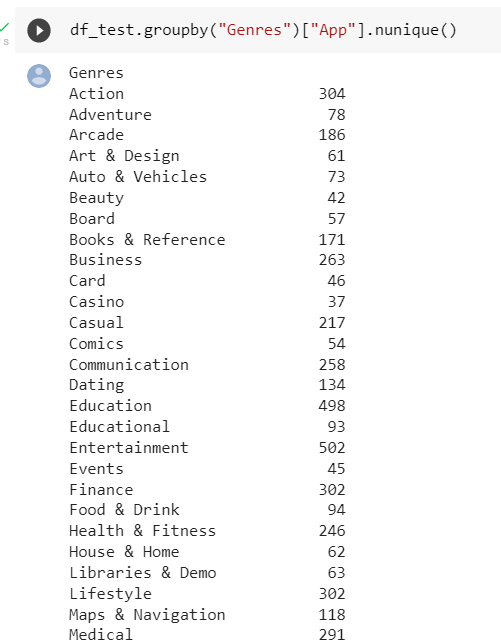
Fig. 16.
- Para el campo Last Update ya que se esta trabajando con fechas debemos convertir la cadena de caracteres de toda la tabla a un valor de tipo Date, y como el formato en el que se presentan en estas cadenas es en casi toda la tabla es solo separar los valores y registrarlos con el tipo Date
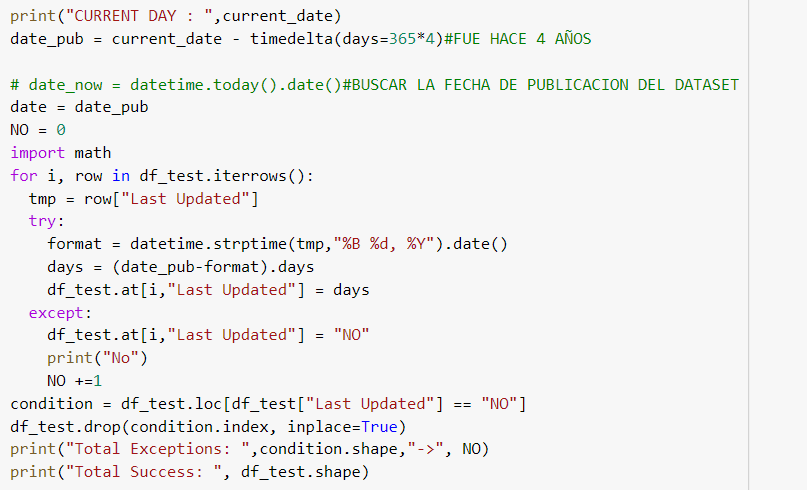
Fig. 17.
- Ya para trabajar es más sencillo trabajar con datos numéricos que con fechas cambiaremos el significado del campo, pasando de registrar la fecha de la última actualización, se contarán los días desde la última actualización de cada aplicación de la tabla hasta el dia de hoy y pasa de ser de tipo Date a tipo float
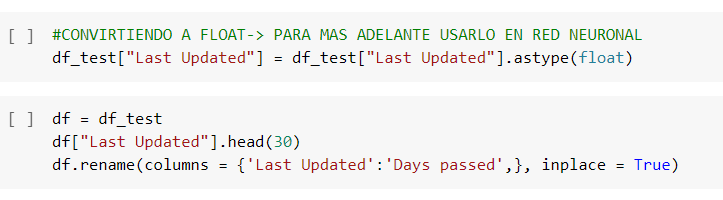
Fig. 18.
- Por último para arreglar los datos de Android ver, hay caracteres que obstaculizan el análisis, la cadena “and up”, “nan” y “NO”, lo primero se debe retirar dichos caracteres
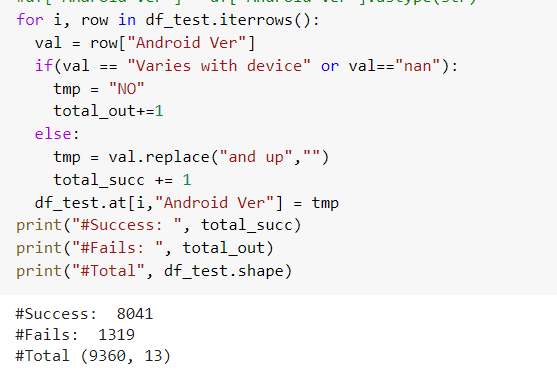
Fig. 19.
- Luego tenemos algunos rangos por ejemplo “4.0 - 5.0” en el cual se nos muestran 2 valores, en este caso se toma el primer valor osea el menor, así obtenemos todos los valores diferentes y realizamos un conteo
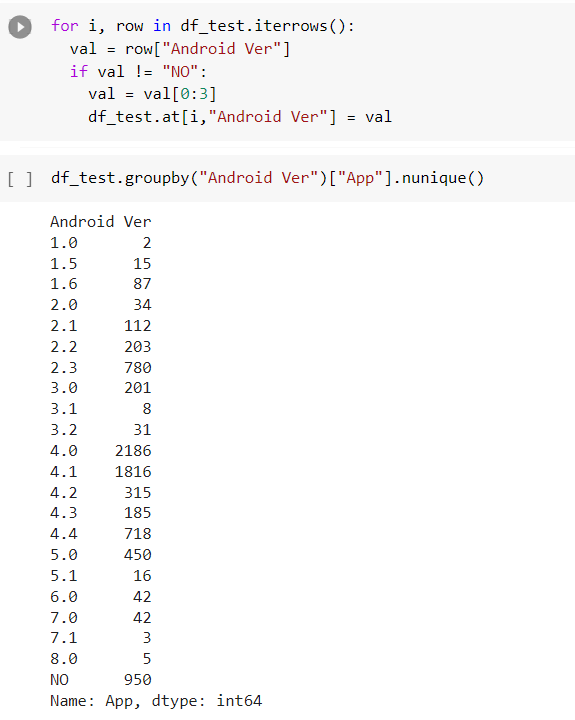
Fig. 20.
- Ya por ultimo convertimos estos valores de las versiones a floats

Fig. 21.
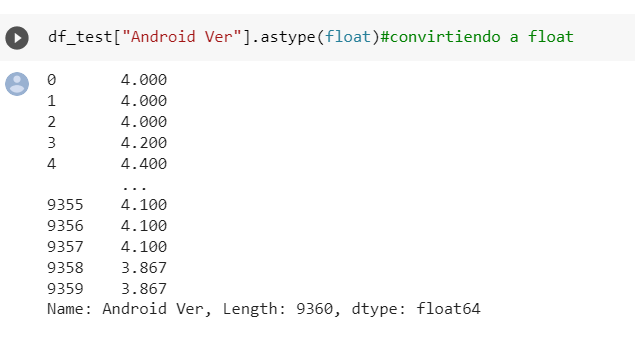
Fig. 22.
4. Los outliers se trataron asi:
En el paso anterior se arreglaron los datos con el fin de obtener coherencia en el resultado de la red neuronal. Se tiene el dataset con 13 columnas y 9360 filas
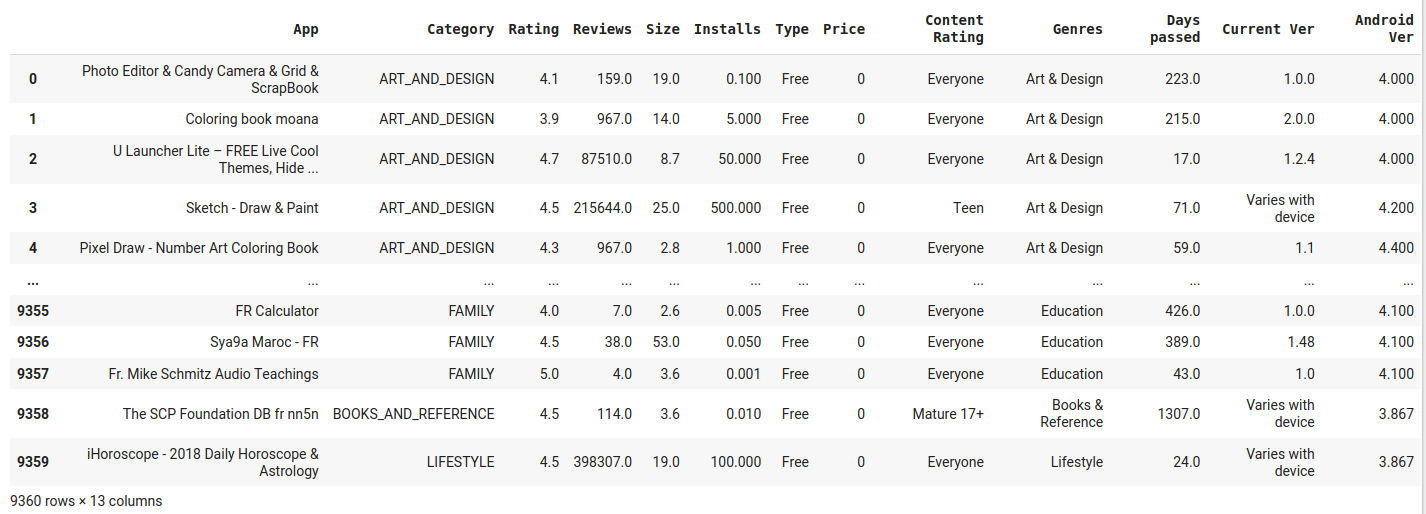
Fig. 23.
Se puede observar los tipos de datos, resumidos a object(string) y float64
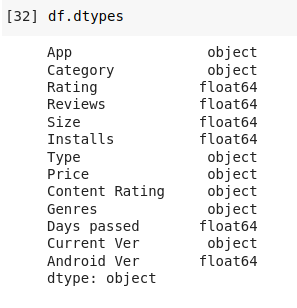
Fig. 24.
Se realizó una función que detecta outliers en las columnas del dataset (una observación anormal y extrema en una muestra estadística). Se calcula el valor iqr (Los Outliers son los puntos que caen a más de 1.5 veces el IQR, a partir de la caja) y se hallan límites superiores e inferiores, con los cuales se creará una estructura con los outliers y sus valores:
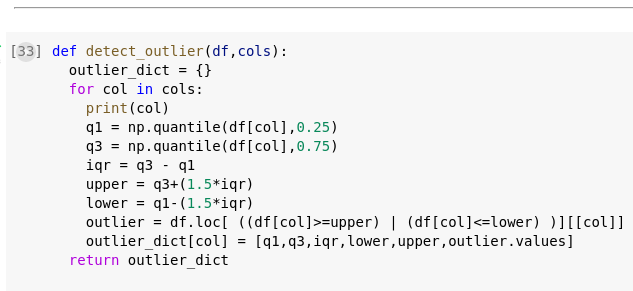
Fig. 25.
Función para remover outliers
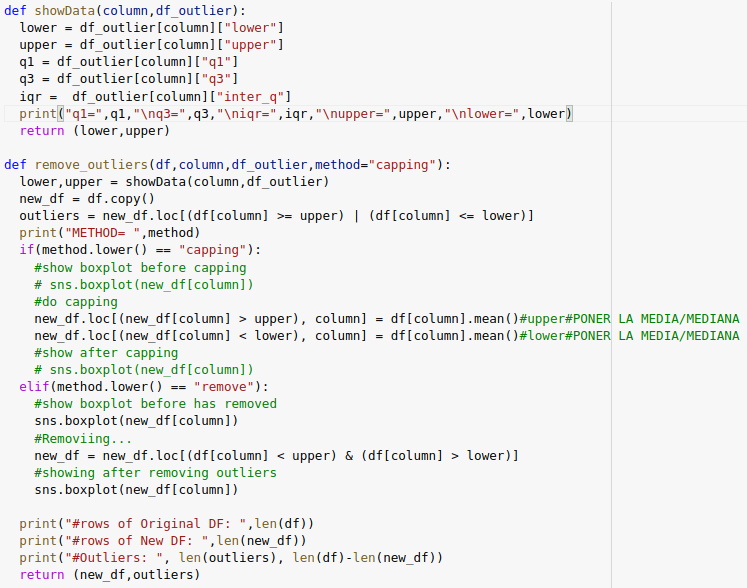
Fig. 26.
Al procesar la información con la función detect_outliers, se obtuvieron los siguientes valores

Fig. 27.
En base a esto, se corrigen los outliers para cada una de las variables de la tabla anterior
Para reviews se grafica primero para ver la magnitud del problema
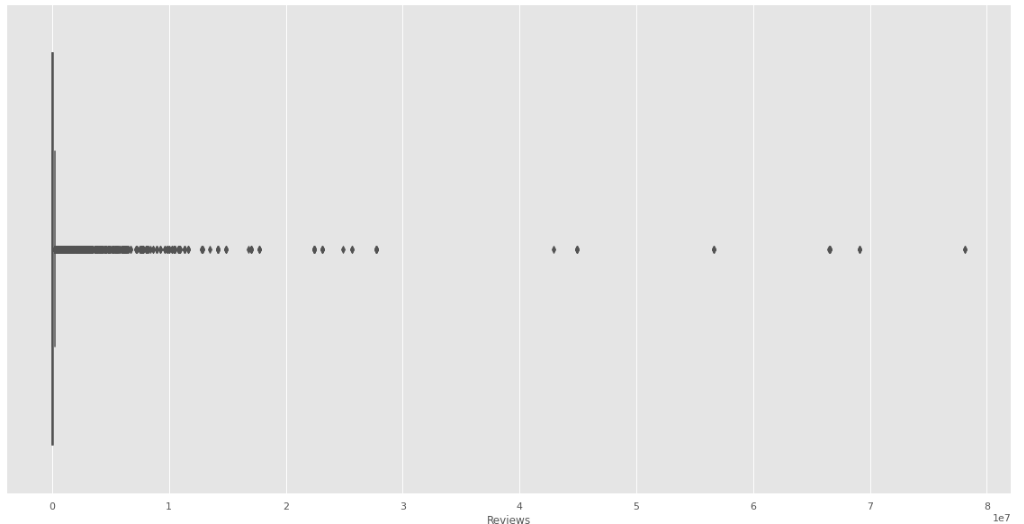
Fig. 28.
Se realiza un llamado a la función remove_outliers() para remover los outliers. Se ha de aclarar que se usará el método capping para tal fin:
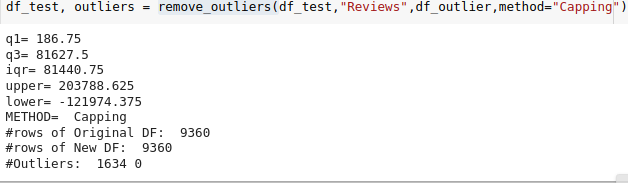
Fig. 29.
Se visualiza el gráfico de cajas y bigotes:
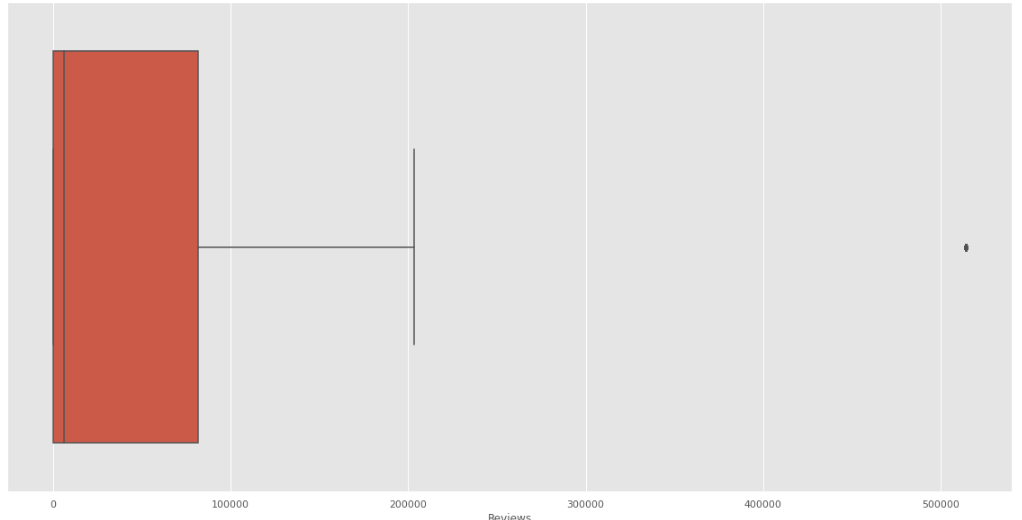
Fig. 30.
Se visualizan los resultados:
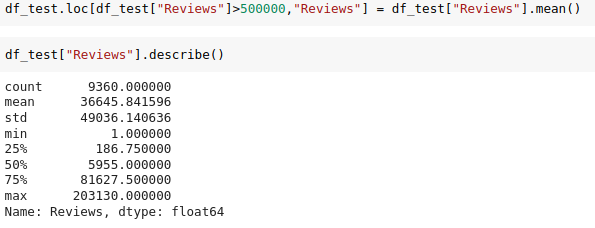
Fig. 31.
Para sizes tenemos lo siguiente:
Se visualiza el gráfico de cajas y bigotes donde se puede ver los puntos separados de la caja del diagrama:
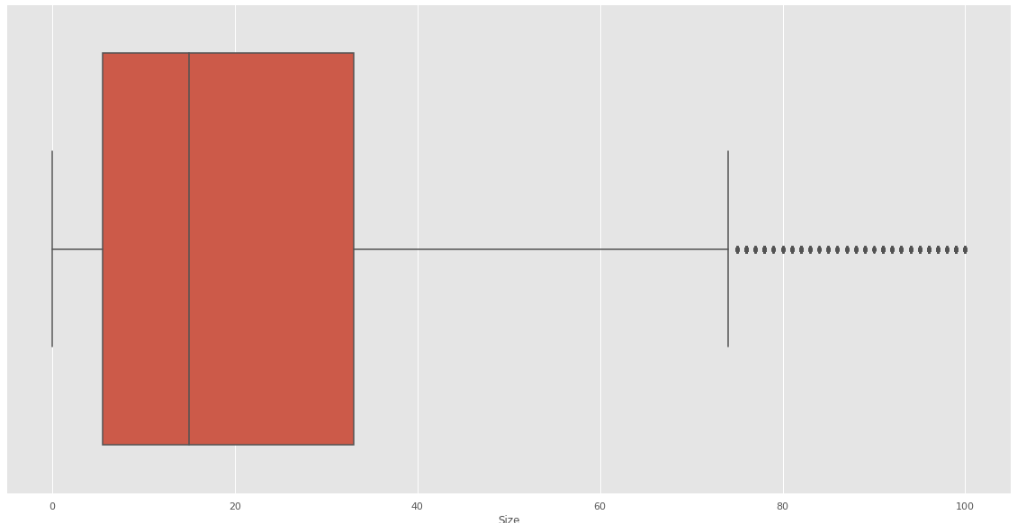
Fig. 32.
Un análisis de los datos arroja lo siguiente:
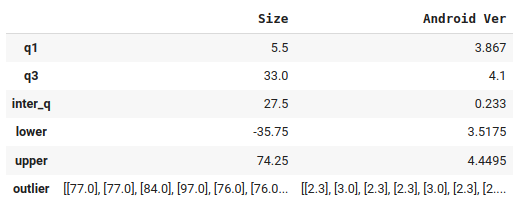
Fig. 33.
Se hace el llamado para corregir ese problema usando capping:
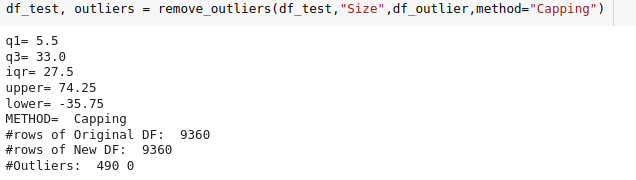
Fig. 34.
Se resolvió el problema de outliers:
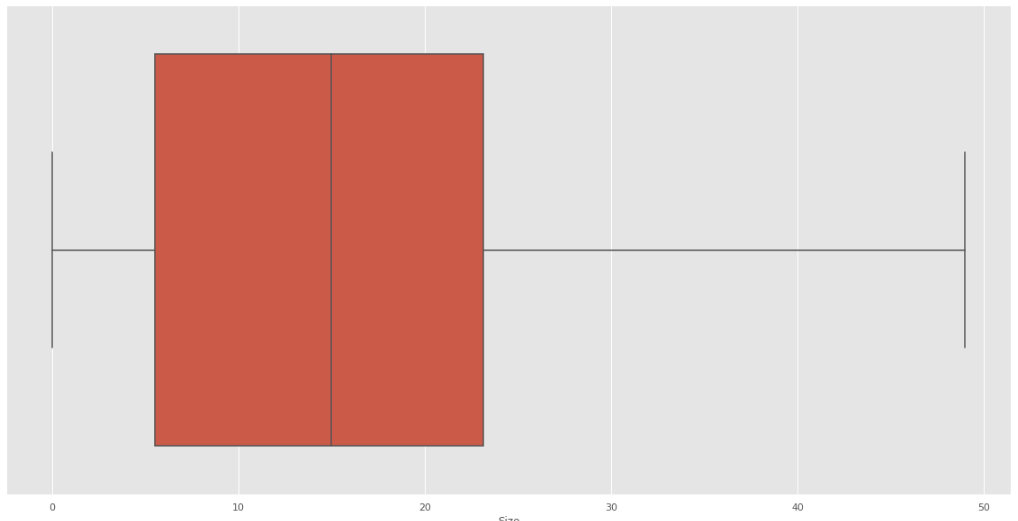
Fig. 35.
Para Installs tenemos que tiene puntos distanciados considerablemente de la caja:
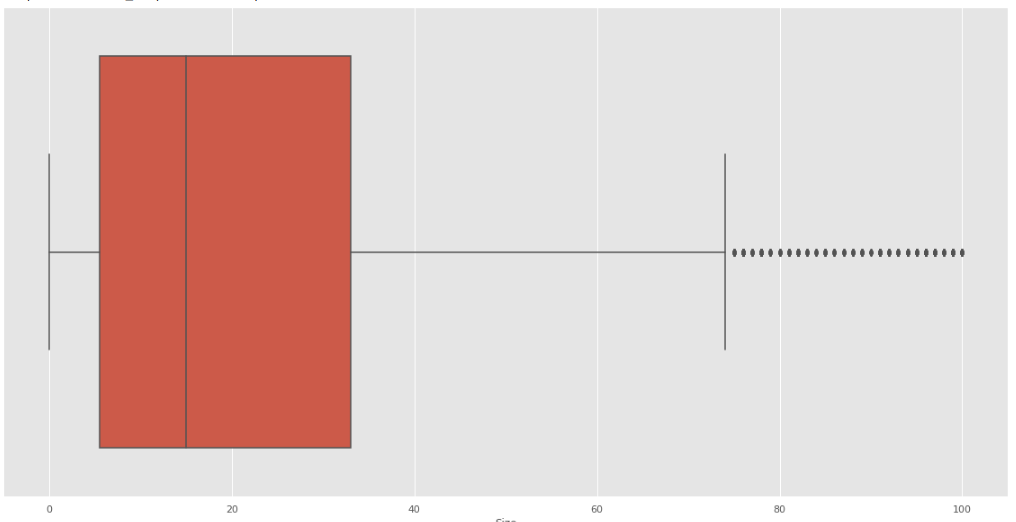
Fig. 36.
Análisis de límites de los datos y visualización de los outliers

Fig. 37.
Luego de la corrección se puede ver el siguiente gráfico en función a los datos corregidos :

Fig. 38.
Para Days Passed tenemos lo siguiente:
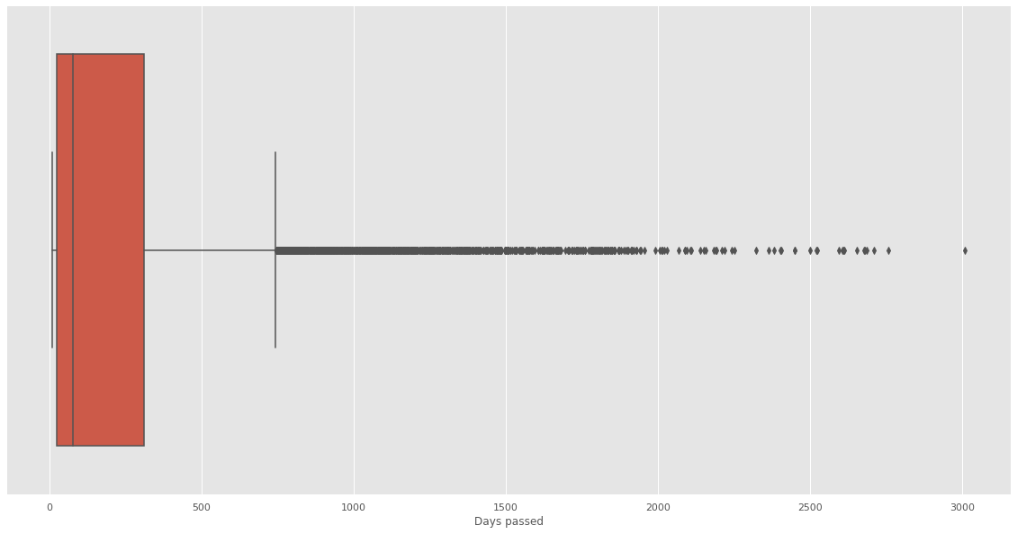
Fig. 39.
Se visualiza la corrección de los datos:
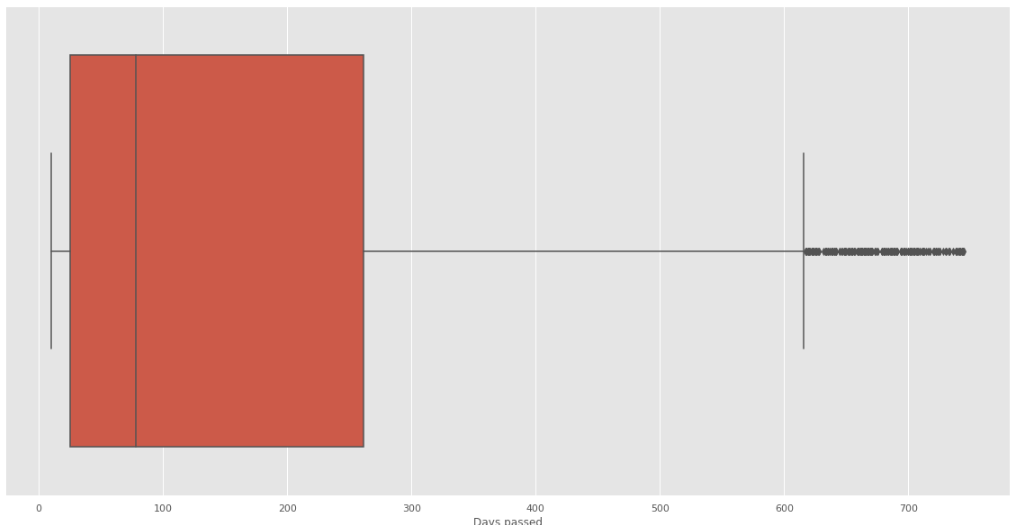
Fig. 40.
Para Android Version tenemos lo siguiente:
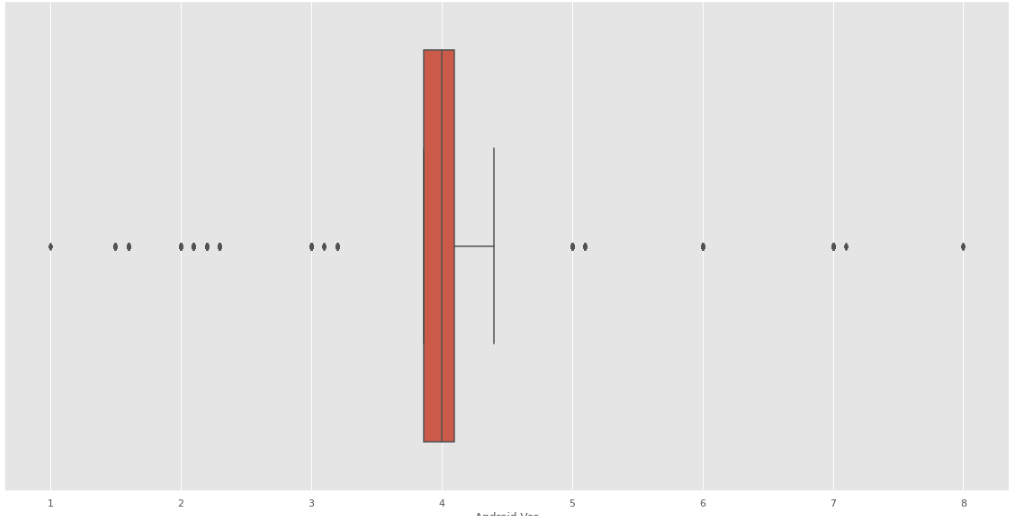
Fig. 41.
Finalmente se ve la corrección de los datos:
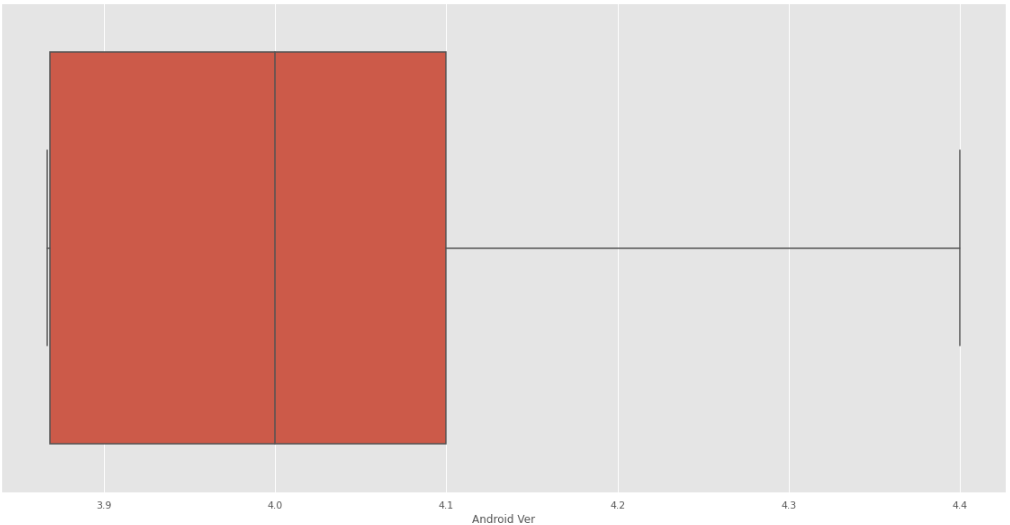
Fig. 42
5. Redes Neuronales
- Se seguirán unos ciertos pasos
Fig. 43.
- Ahora se removerán las columnas que no se utilizaran

Fig. 44.
- Luego se ordenara la tabla

Fig. 45.
- Observamos la columna “Category” esta columna.
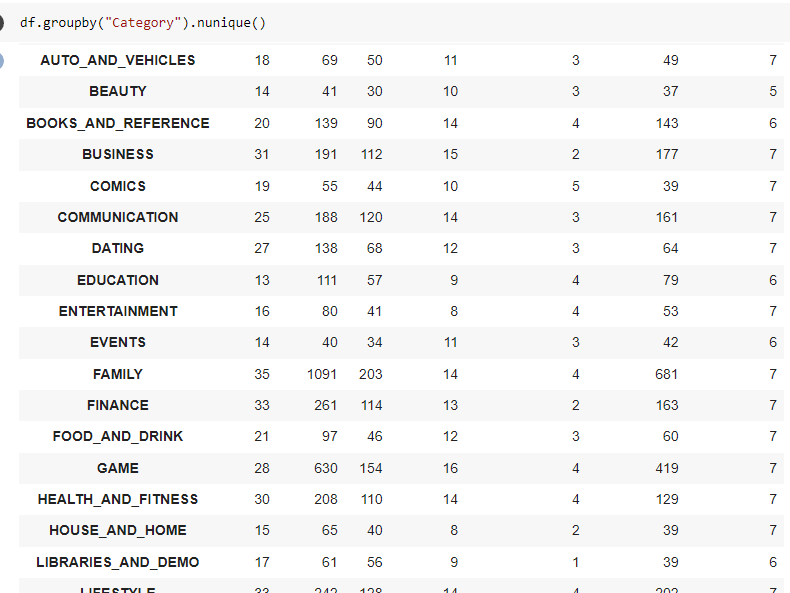
Fig. 46.
- Se procede a codificar “Category” y los valores que poseía esta columna

Fig. 47.
- Se procede a codificar “Rating y los valores que poseía esta columna”
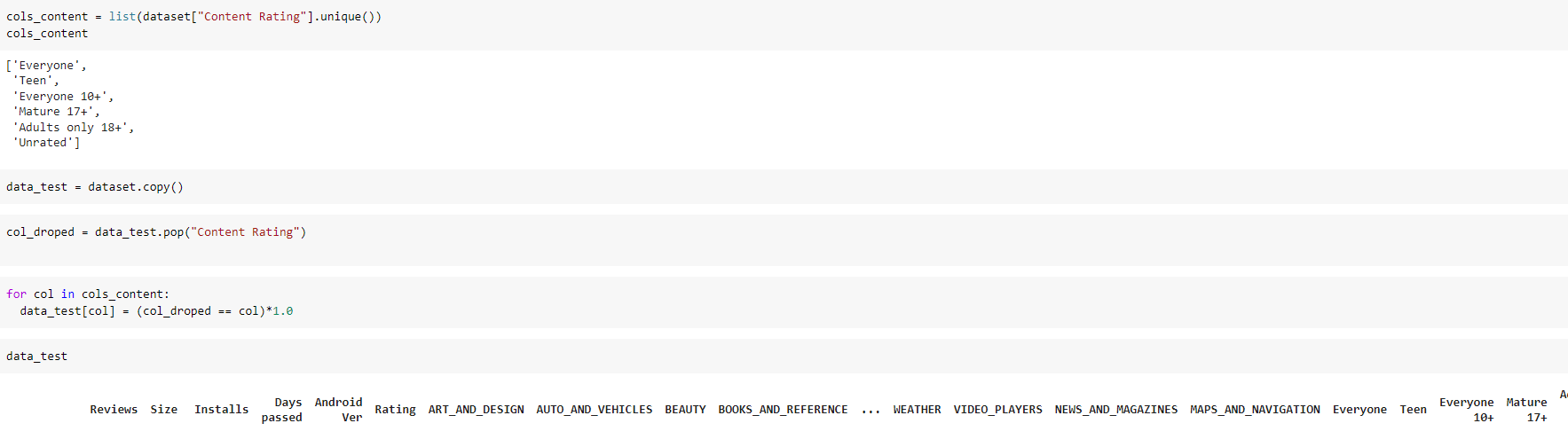
Fig. 48.
- Se procede a tener dos variables para entrenar y los datos para el testing

Fig. 49.
Ahora se procede a normalizar
- Primero se obtienen las estadísticas
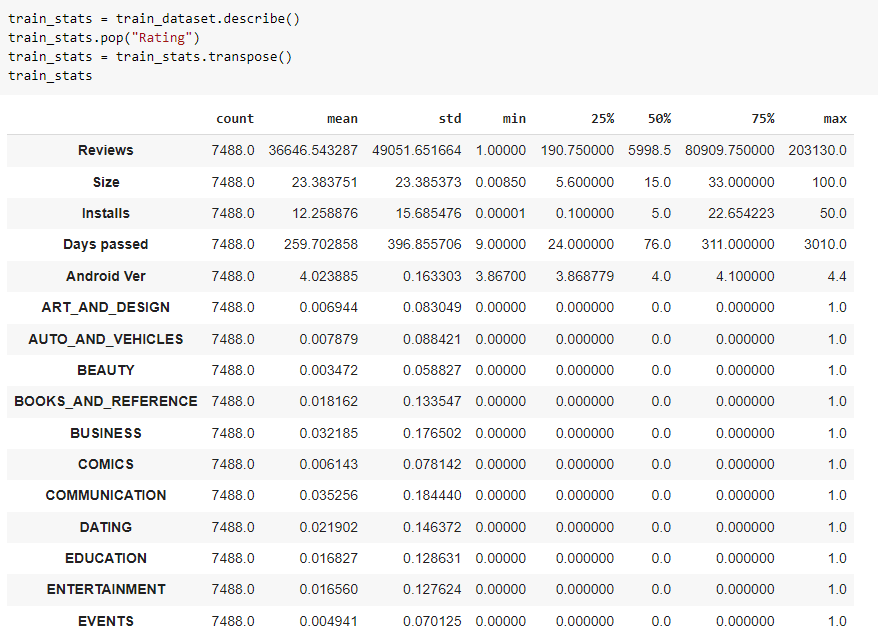
Fig. 50.
- Se obtienen las etiquetas del train y test (Se quita Rating porque es nuestro output)
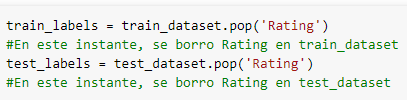
Fig. 51.
- Se normalizan los datos (Con los datos de traint_stats)

Fig. 52.
- Resultado de la tabla normed_train_data
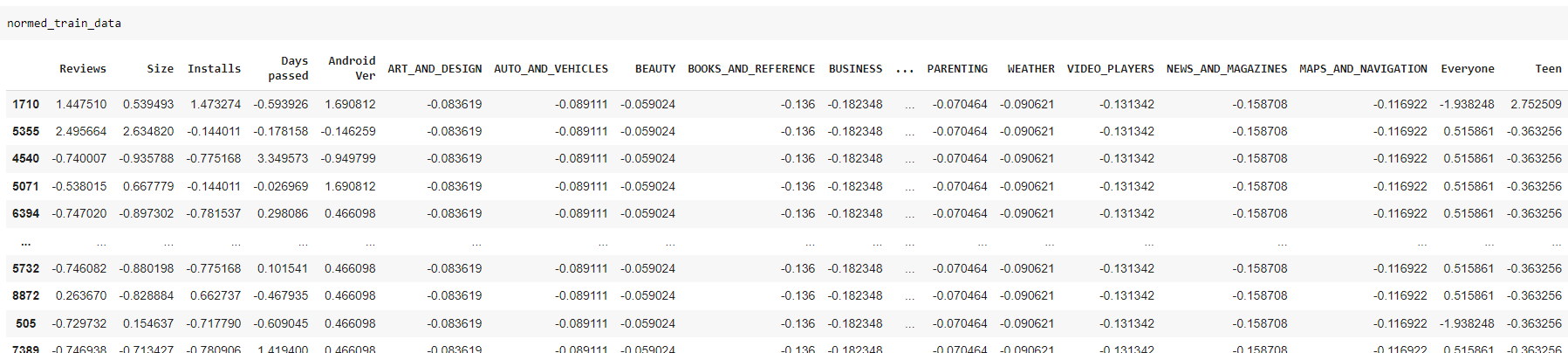
Fig. 53.
- Se construye el modelo y ejecuta

Fig. 54.
- Se entrena al modelo

Fig. 55.
- Se realiza un ejemplo de predicción
Fig. 56.
- Se imprime la historia de los 1000 epoch iterados
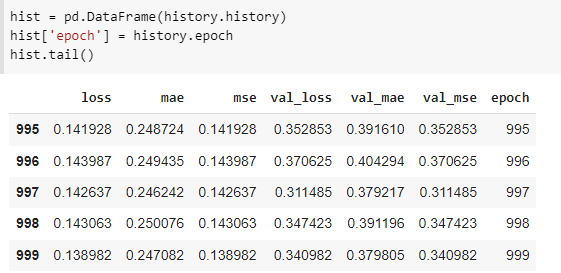
Fig. 57.
- Se crea una función para ver el error de entrenamiento

Fig. 58.
- Se grafica el error cuadrático medio y el error absoluto medio
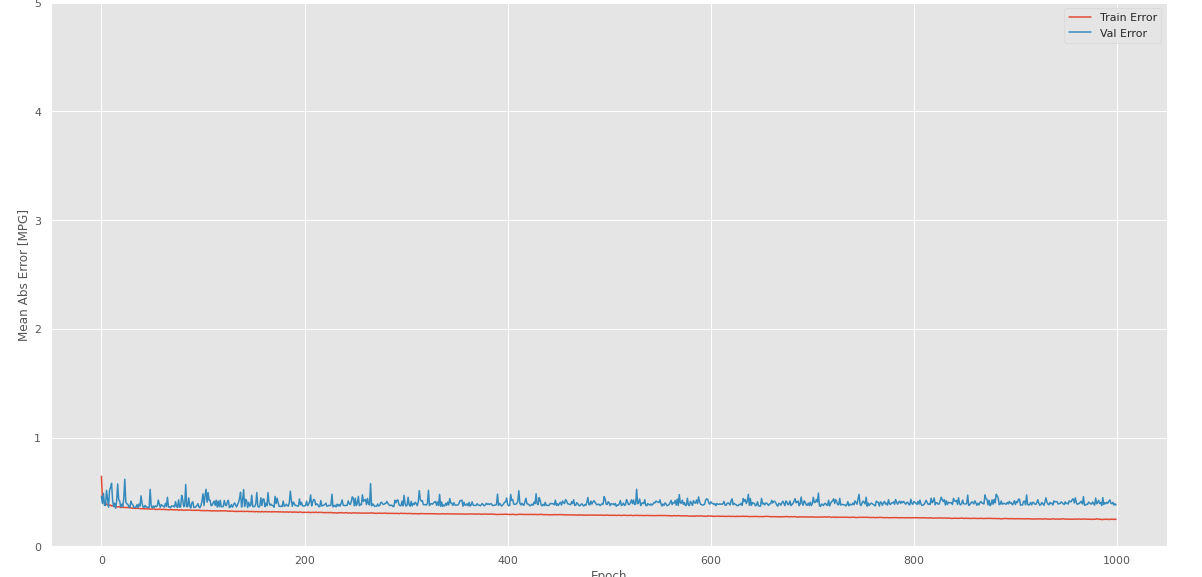
Fig. 59.
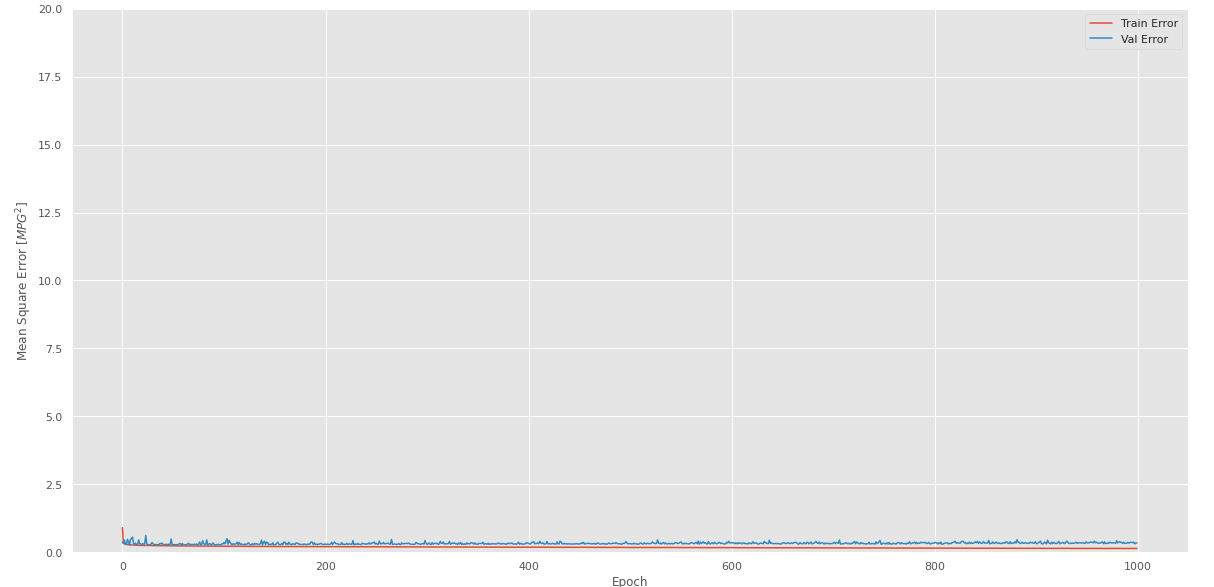
Fig. 60.
- Se analizan las predicciones

Fig. 61.
- Gráfico en el error medio absoluto
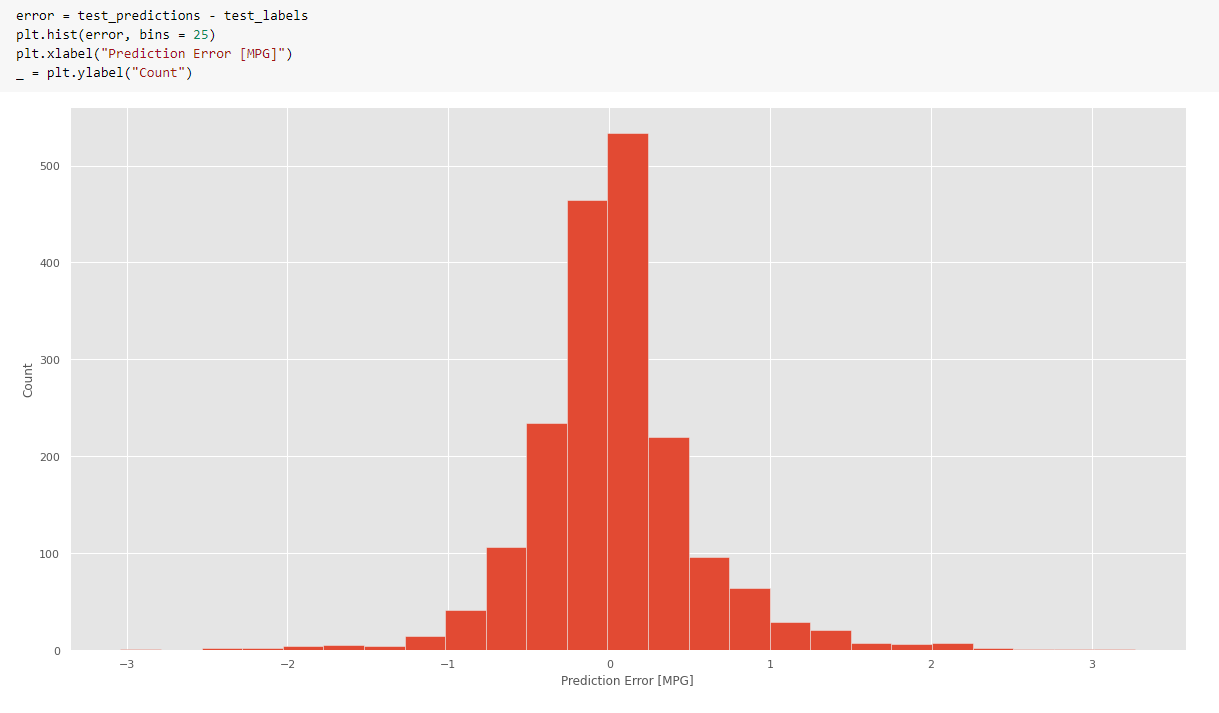 [Fig. 62.]
[Fig. 62.]- Se usa pairplot que genera una gráfica de pares de variables. nos permite ver tanto la distribución de variables individuales como las relaciones entre dos variables
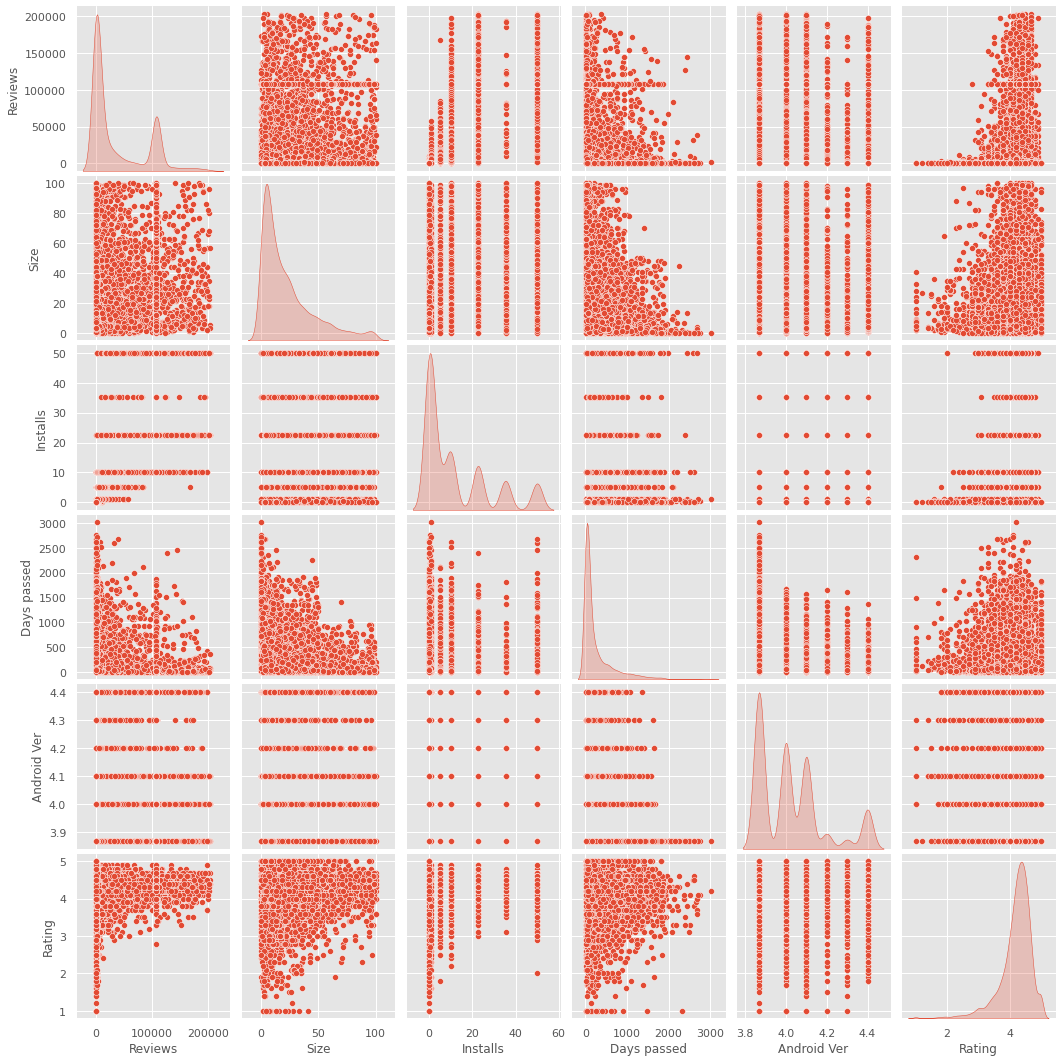
Fig. 63.
Evaluación
Para la evaluación de nuestros datos, se usaron dos variantes de un mismo modelo, en el cual el modelo versión 1, se implementó sin un modelo de estrategia determinado para corregir a la red neuronal con respecto al error cuadrático medio.
Mientras que en el modelo versión 2, si se usó una estrategia de corrección llamada “EarlyStopping”, este tipo de técnica logra corregir a la red neuronal según el error absoluto medio, el cual deberá bajar en cada iteración o época de entrenamiento, pero si el valor aumenta con respecto al anterior entonces se debe orientar a la red neuronal para que consiga un Error Absoluto Medio(considerado en el parámetro “monitor”) menor en cada iteración, para esto se debe especificar el parámetro “patience”, el cual indicará hasta cuantas épocas es permitido el valor de incremento y cada cuanto corregir este valor.
Modelo Genérico:
El modelo genérico para las dos versiones de siguientes está determinado por esta arquitectura:
- 1. La primera capa, está constituida por el Input Layer, donde entran los datos de las variables de cada columna.
- 2. La segunda, tercera y cuarta columna son las denominadas “Hidden Layers”, las cuales iniciarán con pesos aleatorios en sus conexiones y a medida se entrene el modelo, se modificarán las neuronas conforme a los patrones de los datos.
- 3. Y finalmente, la última capa es llamada “Output Layer”, donde se entregará el valor final de la variable Rating predecida.

Fig. 64.
Modelo 1:
A continuación, se muestra el Mean Absolute Error con respecto a cada época, se puede ver claramente que la diferencia entre el Mean Absolute Error entre los valores predecidos y los valores verdaderos se aleja a medida que las épocas se desarrollan.
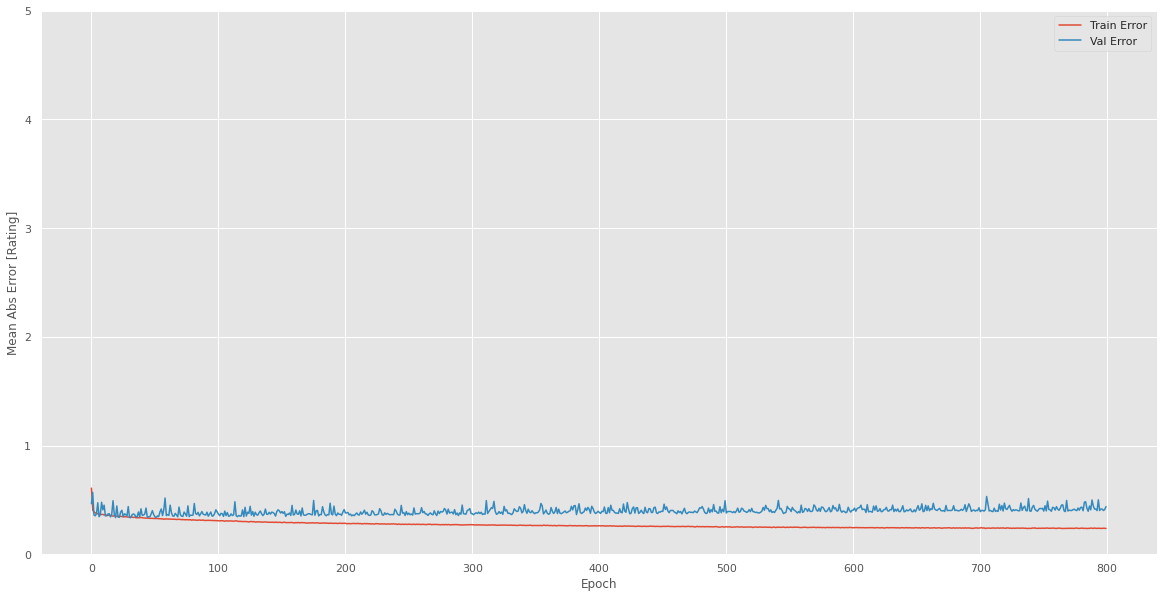
Fig. 65.
Modelo versión 2:
En este modelo, se puede ver a simple vista que los valores convergen y se acercan más y más, debido a la estrategia “EarlyStopping” que corregirá a los valores predecidos conforme al lote de testeo modificando así a las redes neuronales cada vez que las diferencias de Mean Absolute Error son mayores con una corrección de cada 10 épocas.
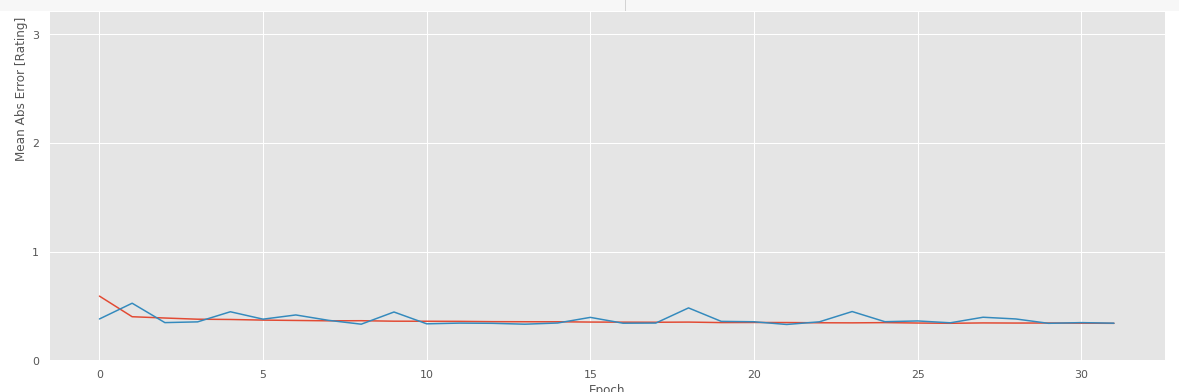
Fig. 66.
Métricas del Modelo 1 y Modelo 2:
Luego fueron desarrolladas las métricas con respecto a los dos modelos, como se presenta en la siguiente tabla de comparaciones:
| Modelo/Métricas | Mean Absolute Error | Mean Square Error |
| Modelo versión 1 | 0.4582 | 0.4286 |
| Modelo versión 2 | 0.3581 | 0.2870 |
Implementación
En base al análisis realizado se realizó la implementación de la red neuronal usando la herramienta Collaboratory de Google Research, el cual nos permite ejecutar código desde notebooks(páginas donde el código puede ser dividido , con el fin de poder ser ejecutados en pasos) . Se creó un directorio ubicado en el Google Drive personal de cada desarrollador (/MyDrive/INTELIGENCIA_ARTIFICIAL) donde se colocó el archivo original que contiene al dataset, este directorio también sirvió para poder recibir la respuesta de la aplicación, la cual contenía el dataset modificado en su fase de limpieza.
En el momento de la ejecución el servicio de google nos suministra todas las librerías, el almacenamiento, el poder de procesamiento y la RAM, por lo cual simplemente se ejecutan las instrucciones y se obtienen los resultados a través del navegador Web, sin consumir muchos recursos de nuestros sistemas.
Conclusiones
Las conclusiones al respecto de los modelos construidos es que tienen una grán relación entre las variables usadas para la predicción, así el modelo cumple en general con el objetivo de este trabajo, y puede ser una herramienta para la predicción de rating de una App, dada sus variables de input.
De tal manera el modelo hace posible analizar la relación del “Rating” con respecto a otras variables, y ayuda a predecir cómo se comporta la predicción frente a ciertas variables cuando las personas necesiten analizar cómo se comportaría su app en diversas situaciones estimadas o supuestas.
Como trabajo futuro, nos proponemos mejorar y probar el dataset con varios optimizadores, diferentes modelos, y probar con varias “Hidden Layers”. Con el fin de mejorar las predicciones.
Referencias
[1] NewsEuropeanParliament, “What is artificial intelligence and how is it used? | News | European Parliament,” News European Parliament, 2021.://www.europarl.europa.eu/news/en/headlines/society/20200827STO85804/what-is-artificial-intelligence-and-how-is-it-used (accessed Jun. 29, 2022).
[2] R. P. Diez, Introducción a la inteligencia artificial: Sistemas expertos, redes neuronales artificiales y computación evolutiva. Oviedo: Universidad de Oviedo, Servicio de Publicaciones, 2001.
[3] S. E. T. Sánchez, M. O. Rodríguez, A. E. Jiménez, and H. J. P. Soberanes, “Implementación de Algoritmos de Inteligencia Artificial para el Entrenamiento de Redes Neuronales de Segunda Generación,” Jóvenes En La Cienc., vol. 2, no. 1, pp. 6–10, 2016, Accessed: Jun. 29, 2022. [Online]. Available: ://www.jovenesenlaciencia.ugto.mx/index.php/jovenesenlaciencia/article/view/715.
[4] M. Gallego Gallego and J. Hernández Cáceres, “Identificación de factores que permitan potencializar el éxito de proyectos de desarrollo de software,” Sci. Tech., vol. 20, no. 1, p. 70, Mar. 2015, doi: 10.22517/23447214.9241. (accessed Jun. 29, 2022).
[5] GCFGLOBAL, “¿Cómo usar Android?: Qué es y cómo usar Google Play Store,” 2019. https://edu.gcfglobal.org/es/como-usar-android/que-es-y-como-usar-google-play-store/1/ (accessed Jun. 29, 2022).
[6] E. Noei and K. Lyons, “A Survey of Utilizing User-Reviews Posted on Google Play Store,” 2019, doi: 10.1145/1122445.1122456.
[7] “(PDF) Capítulo 1: Generalidades de las redes neuronales artificiales.” https://www.researchgate.net/publication/327703478_Capitulo_1_Generalidades_de_las_redes_neuronales_artificiales (accessed Jun. 29, 2022).
[8] E. Varela and E. Campbells, “Redes Neuronales Artificiales: Una Revisión del Estado del Arte, Aplicaciones y Tendencias Futuras,” Investig. y Desarro. en TIC, vol. 2, no. 1, pp. 18–27, 2011, Accessed: Jun. 22, 2022. [Online]. Available: http://revistas.unisimon.edu.co/index.php/identic/article/view/2455.
[9] F. O.C, Introducción a los Negocios en un Mundo Cambiante, 4a ed. México D.F.. México: McGraw-Hill Interamericana, 2004.
[10]“López Porrero - 2011 - Limpieza de datos reemplazo de valores ausentes y estandarización,” Accessed: Aug. 19, 2022. [Online]. Available: https://1library.co/title/limpieza-datos-reemplazo-valores-ausentes-estandarizacion.
[11]"¿Qué son los Datasets? [4 sitios donde encontrarlos]". KeepCoding Tech School. https://keepcoding.io/blog/que-son-datasets/ (accedido el 19 de julio de 2022).
[12]"Google colaboratory". Google Colab. https://colab.research.google.com/?hl=es (accedido el 25 de julio de 2022).
[13]"Mapa autoorganizado". Los diccionarios y las enciclopedias sobre el Académico. https://es-academic.com/dic.nsf/eswiki/683112 (accedido el 5 de agosto de 2022).
[14] J. M. Uriarte, “Google Drive: qué es, cómo funciona y características,” 2020, 2020. https://www.caracteristicas.co/google-drive/#ixzz7c8jGC900 (accessed Aug. 19, 2022).
[15] Santander Universidades, “¿Qué es Python? | Blog Becas Santander,” 2021. https://www.becas-santander.com/es/blog/python-que-es.html (accessed Aug. 19, 2022).
[16] “Todo lo que necesitas saber sobre TensorFlow, la plataforma para Inteligencia Artificial de Google – Puentes Digitales,” 2021. https://puentesdigitales.com/2018/02/14/todo-lo-que-necesitas-saber-sobre-tensorflow-la-plataforma-para-inteligencia-artificial-de-google/ (accessed Aug. 19, 2022).
[17] Ionos, “¿Qué es Keras? Introducción a la biblioteca de redes neuronales - IONOS,” 2020. https://www.ionos.mx/digitalguide/online-marketing/marketing-para-motores-de-busqueda/que-es-keras/ (accessed Aug. 19, 2022).
[18] F. Pérez and H. Fernández, “Las redes neuronales y la evaluación del Riesgo de Crédito,” Rev. Ing. Univ. Medellín, pp. 77–91, 2007, Accessed: Aug. 19, 2022. [Online]. Available: http://www.scielo.org.co/scielo.php?script=sci_arttext&pid=S1692-33242007000100007
Roles de Autoría
Rudy Roberto Tito Durand: Conceptualización, Curación de datos, Análisis formal, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Marcelo Andre Guevara Gutierrez: Conceptualización, Curación de datos, Análisis formal, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Jeampier Anderson Moran Fuño: Conceptualización, Curación de datos, Análisis formal, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Edsel Yael Alvan Ventura: Conceptualización, Curación de datos, Análisis formal, Investigación, Metodología, Software, Validación, Redacción - borrador original.
Información adicional
Tipo de artículo:: Artículos originales
Temática:: Inteligencia Artificial
Enlace alternativo
https://revistas.ulasalle.edu.pe/innosoft/article/view/87 (html)
https://revistas.ulasalle.edu.pe/innosoft/article/view/87/111 (pdf)
https://revistas.ulasalle.edu.pe/innosoft/article/view/87/112 (html)