Monográfico junio 2022. Interacción del Marketing y la Inteligencia Artificial

Esta obra está bajo una Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.
Recepción: 10 Marzo 2022
Aprobación: 07 Junio 2022
DOI: https://doi.org/10.17979/redma.2022.26.1.9007
Resumen: La gestión del inventario de medicamentos es una de las tareas más complejas a realizar en una farmacia. Una buena estimación de las compras favorece el compromiso entre satisfacer la demanda de los usuarios y minimizar los costos de mantenimiento de inventario y de almacenamiento. Por ello, conocer a priori la demanda de un determinado medicamento ayuda a decidir qué cantidad se debe comprar de producto. Las aplicaciones inteligentes, como los sistemas de recomendaciones o los sistemas predictivos, son altamente demandados por la industria farmacéutica dado su potencial para optimizar la compra y/o tener un mayor control de los inventarios, entre otros beneficios. En este trabajo se proponen dos métodos para predecir la demanda de medicamentos de la Farmacia del Instituto del Seguro Social de Ecuador, en la ciudad de Ibarra; uno basado en series de tiempo y otro usando redes neuronales. Los métodos fueron aplicados a medicamentos que tenían un comportamiento estacional y cíclico. Los modelos se evaluaron usando el error cuadrático medio y el error absoluto y se escogió el de menor error, que, en este caso, fue el modelo generado por la red neuronal.
Palabras clave: modelos predictivos, gestión de inventario, sistemas inteligentes, marketing, farmacéuticas.
Abstract: Inventory management of medicines is one of the most complex tasks for a pharmacy. Accurate purchase estimation allows pharmacies to balance the need to meet user demand and minimise inventory maintenance and storage costs by reliably predicting how much of a drug should be purchased. This paper proposes two methods for predicting the demand for medicines from the Pharmacy of the Ecuadorian Social Security Institute (Ibarra): one based on time series, and one based on neural networks. The models were tested on medicines with a seasonal, cyclical demand, and assessed using mean square error and mean absolute error measurements. The model based on neural networks was found to have a lower error rate.
Keywords: predictive models, inventory management, intelligent systems, marketing, pharmaceutical industry.
1. INTRODUCCIÓN
Con los avances tecnológicos las empresas han encontrado una forma de cómo aumentar sus ventas, mantener su presencia en el mercado y/o tener un mayor control de sus inventarios a fin de permanecer en un mercado cada vez más competitivo. Con este fin, las empresas han incorporado aplicaciones inteligentes en sus procesos, como las que sugieren productos con base en las preferencias de los clientes (sistemas de recomendaciones), o que estiman los niveles de inventarios de sus productos (sistemas predictivos). Contar con información de la demanda que se espera de un producto en un horizonte de tiempo, ayuda a los responsables del control de inventarios a tomar decisiones acertadas sobre las compras, lo que incide en una mejor gestión del presupuesto y del espacio de almacenamiento de los productos.
Para las empresas farmacéuticas es importante conocer los niveles de inventarios de sus ítems, tanto para garantizar la disponibilidad de sus productos, brindando un servicio de calidad, como para hacer un mejor uso del presupuesto asignado. Este último punto busca evitar mantener inventarios altos en productos de poca demanda, sobre todo cuando sus costos pueden estar por encima de los cientos o miles de dólares, de tal manera que el presupuesto se pueda destinar a otras actividades, además de reducir el riesgo de que los ítems con poca demanda caduquen en la estantería.
En las farmacias de hospitales, la correcta estimación de los niveles de inventario es aún más importante, debido a que, en algunos casos, los medicamentos son requeridos con urgencia debido a que la vida del paciente depende de su administración, por lo tanto, se debe asegurar su existencia. En este contexto, una gestión eficiente debe tener en cuenta la planificación, supervisión y control de los servicios que se prestan en la farmacia.
Los modelos de inventario se utilizan como sistemas de apoyo en la toma de decisiones cuando se debe definir la cantidad de ítems a pedir, estimar el punto de reordenación o seleccionar los proveedores. Decisiones que necesitan tener en cuenta información como: costos de inventarios, almacenamiento y envío, demanda del producto y precios del proveedor entre otras variables. Se han utilizado diferentes enfoques para estimar los niveles de inventario, entre ellos, los modelos de inventario probabilísticos para minimizar los costos que establecen políticas óptimas y asumen demandas probabilísticas e independientes (Pulido-Rojano et al., 2020; Zhang et al., 2018). Se han utilizado estrategias para reducir la complejidad de los modelos, como considerar que la demanda tiene un comportamiento determinista y estacionario, simplificaciones que ocasionan pérdidas en la precisión o rendimiento del sistema. Sin embargo, estas simplificaciones afectan los resultados, los cuales fueron analizados por Huseyin Tunc et.al. (2011).
La no estacionariedad de la demanda es una de las características que ha sido tomada en cuenta en diversos trabajos (Gutiérrez-Alcoba, et al., 2017; Sinaga, et al., 2016). Otros trabajos han propuesto modelos de programación lineal entera mixta para encontrar el nivel de inventarios usando modelos de clasificación ABC (Hakim, Ulfah, 2019) integrando diversos componentes de la red de suministro, tales como la fabricación de múltiples ciclos, políticas de seguridad, red de distribución global, entre otros, a fin de maximizar el beneficio (Susarla, N., and Karimi, 2018). También se han utilizado representaciones de demandas Markovianas (Nasr y Elshar, 2018) y otros modelos han incorporado restricciones de capacidad de almacenamiento, control periódico del inventario y políticas de emisión FIFO y LIFO mixtas para artículos perecederos con una demanda aleatoria no estacionaria (Janssen, et al., 2018).
El uso de nuevas tecnologías, como Big Data y el procesamiento en la nube, han facilitado el procesamiento de grandes volúmenes de datos con el propósito de extraer información valiosa de éstos. Los modelos de control predictivo (MPC) estocástico han utilizado el procesamiento masivo de datos en sus modelos. Variables como tiempo de envío, demanda del producto, restricciones de almacenamiento y de operación fueron tomadas en cuenta (Jurado, et al. 2016; Maestre, Fernández y Jurado, 2018; Álvarez-Rodríguez, Normey-Rico y Flesch 2017). Estrategias basadas en escenarios también han sido incorporados a los MCP estocásticas (Fernández et al., 2021). Estos trabajos han sido realizados en farmacias de centros de salud en España.
Junto al procesamiento masivo de datos se han usado diferentes algoritmos con el objeto de encontrar modelos que describan el comportamiento de la demanda (Gunasekaran et al., 2017). Se han usado algoritmos de Máquinas de Soporte Vectorial (Ahmed y Farzana, 2020), y algoritmos de regresión lineal o series de tiempo (Liu, et al., 2021; Miller, et al., 2020; Zhou, et al, 2019,Pavlyshenko, 2019), que utilizan métodos de analítica de datos y brindan apoyo para decidir los niveles de inventario.
En este trabajo se presentan dos métodos para predecir la demanda de medicamentos en la farmacia del Instituto Ecuatoriano del Seguro Social (IESS). Los métodos de series de tiempo y redes neuronales son aplicados al conjunto de datos históricos de las demandas en la farmacia en un periodo de 3 años. Los resultados obtenidos se comparan a partir de los errores cuadráticos de cada uno.
- 1. En la sección 2 se presentan las consideraciones teóricas de los modelos utilizados.
- 2. En la sección 3 se describe la metodología utilizada.
- 3. En la sección 4, se muestran los resultados obtenidos.
- 4. Finalmente, en la sección 5, se presentan la discusión de los resultados y se dan las conclusiones más importantes de este trabajo.
2. MARCO TEÓRICO
2.1 Series de tiempo
Una serie de tiempo es una colección de observaciones de unas variables registradas secuencialmente durante un período. Por tanto, una serie de tiempo establece una relación entre la variable en estudio y el tiempo en que se captura su valor; este tiempo puede ser diario, semanal, mensual, etc. El conjunto de datos se representa como X(t), t = 1,2,3,… donde X representa los valores observados de la variable de tipo discreta, por ejemplo, temperatura, y t es el tiempo transcurrido entre una observación y la siguiente, siendo el espaciado de tiempo entre observaciones igual.
Las series de tiempo permiten predecir los valores de la variable en estudio a partir de extraer regularidades de sus valores en el pasado y, bajo el supuesto de que las condiciones estructurales que conforman el objeto de estudio permanezcan constantes, se puede encontrar un patrón de comportamiento.
-
T(t): Tendencia, el incremento o decremento de los datos en el tiempo.
-
S(t): Estacionalidad, patrón que se repite en un periodo de tiempo.
-
C(t): Clico, cambios cíclicos en un periodo de tiempo.
-
E(t): Ruido, provocan fluctuaciones irregulares e impredecibles.
Una serie es vista como un proceso estocástico, es decir, la variable X tiene un comportamiento aleatorio. Si las propiedades estadísticas de esta variable, como la media, varianza y la autocorrelación, no cambian, se dice que la serie es estacionaria. La autocorrelación indica qué tanto depende la variable X en un momento en relación con lo que pasaba con ellos en un tiempo anterior (Hamilton, 2020).
Para predecir un tiempo t+d en una serie temporal, se debe encontrar una función f: 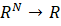 que relacione las . observaciones anteriores, es decir:
que relacione las . observaciones anteriores, es decir:
X(t+d) = f(X(t-1), X(t-2),...,X(t-N+1))
La función puede tomar en cuenta la estacionalidad, ciclicidad, tendencia y el ruido de la serie, o basarse en el comportamiento estocástico de la variable tomando en cuenta su estacionalidad y la autocorrelación de los datos, tales como los modelos autorregresivos de medias móviles o modelos generalizados como ARMA y ARIMA.
2.2. Redes neuronales
Las redes neuronales están inspiradas en las redes neuronales biológicas, las cuales utilizan algoritmos de aprendizaje y tienen un procesamiento no lineal, por lo que la red aumenta su capacidad para aproximar funciones y clasificar patrones, además de ser menos propensas al ruido. La red está constituida por un gran número de nodos interconectados, cada uno de los cuales recibe una entrada desde otra unidad o fuente externa, donde cada entrada tiene un peso asociado, 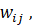 que se va ajustando durante el proceso de aprendizaje.
que se va ajustando durante el proceso de aprendizaje.
Cada unidad aplica una función de activación, f, a la función base, la cual puede ser una función dependiente de las entradas u(w,x)=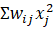 o una función de segundo orden u(w,x)=
o una función de segundo orden u(w,x)=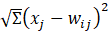 . La función de activación, f, es responsable de transformar la función base en la salida
. La función de activación, f, es responsable de transformar la función base en la salida 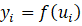 .
.
-
la capa de entrada, que contiene los pesos representa la importancia de cada atributo.
-
una o más capas ocultas.
-
la capa de salida
La Figura 1 muestra la arquitectura base de una red neuronal.
En las redes neuronales supervisadas, los datos de entrenamiento están formados por datos de entradas y de salida. Conocer la salida permite a la red ajustar sus pesos en la próxima etapa para obtener la salida deseada.
Un modelo de regresión lineal puede ser utilizado para predecir un valor, dado un conjunto de entradas que pueden ser implementadas como una red neuronal.
3. METODOLOGÍA
La metodología para descubrir conocimiento basada en base de datos (KDD de sus siglas del inglés) fue la utilizada en este trabajo. La metodología establece cinco fases, estas son: selección de los datos, preprocesamiento, transformación de los datos, minería de datos para encontrar los modelos y evaluación de los modelos (Fayyad, Piatetsky-Shapiro and Smyth, 1996).
3.1 Selección de los datos
En esta fase se identificaron qué atributos eran necesarios para la predicción de la demanda. Se analizaron los datos almacenados en la base de datos MySQL del sistema de información médico (MIS-AS400). Este sistema contiene toda la data de los servicios de emergencia, hospitalización, consulta externa, laboratorio, farmacia, etc. Datos como nombre, edad, sexo, ciudad, número de identificación, entre otros, fueron descartados ya que no guardan relación con la demanda de medicamentos. Debido a que el atributo diagnóstico está relacionado con los medicamentos, se tomó en cuenta. Además, se extrajo de la base de datos información como la fecha de la venta, el código del diagnóstico y la cantidad despachada. La data generada contiene las ventas de los últimos tres años precedentes.
3.2 Preprocesamiento de los datos
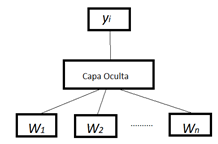
En esta fase, para garantizar que los datos no contienen basura o están incompletos, se eliminaron los registros incompletos y luego, se construyeron histogramas de frecuencia para conocer la demanda promedio de cada medicamento (ver Figura 2) e identificar el comportamiento de la demanda. Como se puede observar en la Figura 3, la demanda de medicamentos se aproxima al comportamiento de la función de distribución normal. Dado que el número de medicamentos que se manejan en la farmacia es alto, se seleccionó solo un subconjunto de medicamentos para entrenar y evaluar los modelos. El histograma de la Figura 2 se utilizó para encontrar los medicamentos con mayor demanda, estos fueron los seleccionados para este trabajo. Asimismo, se exploró la relación entre los atributos seleccionados inicialmente. Se observó que el código diagnóstico tenía indicaciones similares en sus medicamentos, sin embargo, el comportamiento de este atributo, salvo casos especiales como en la gripe, mostraba un comportamiento aleatorio, por lo que no guardaba relación directa con la demanda. Por tanto, este atributo fue descartado. El trabajo se realizó sólo con las medicinas que mostraban, en su demanda, un comportamiento estacional. La demanda de cada medicamento se agrupó semanalmente, tal como se muestra en la Tabla 1.
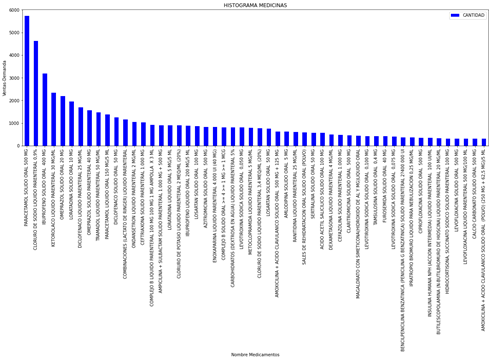
Figura 2
Histograma de frecuencia de la venta del Paracetamol sólido
elaboración propia
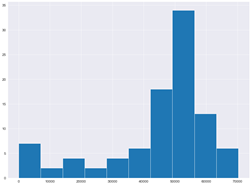
Figura 3
Histograma de frecuencia de la venta del Paracetamol sólido
elaboración propia
Fragmento de la demanda semanal del Paracetamol sólido
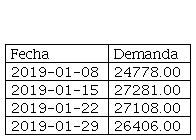
elaboración propia
3.3 Transformación de los datos
En esta fase se realizaron las transformaciones necesarias de los datos con objeto de utilizar los algoritmos de entrenamiento de series de tiempo y de redes neuronales. En el caso de las series de tiempo, el atributo Fecha de la Tabla 1 fue convertido en el índice de la tabla. En el caso de la red neuronal, se quería tener más de una entrada por neurona, por ello, se crearon entradas adicionales. Estas entradas se generaron separando los campos de la fecha, es decir, se crearon los atributos año, día, mes y año-mes (ver Tabla 2).
Fragmento de la transformación realizada a la tabla de demanda del Paracetamol
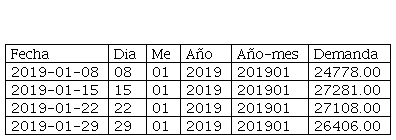
elaboración propia
Adicionalmente, se analizó la demanda de cada medicamento para observar su comportamiento con respecto a la estacionalidad, ciclicidad, tendencia y estacionalidad. La Figura 4 visibiliza la tendencia de las ventas de Paracetamol, que muestra una tendencia decreciente. Es necesario recordar que, durante el periodo de estudio, el hospital se enfocó en la atención de pacientes con COVID-19, por lo que varios medicamentos presentaron una caída en sus demandas. La Figura 5 muestra la estacionalidad de la demanda del mismo medicamento, se observa qué demanda presenta un comportamiento estacional y se observan cambios de ciclos. En cuanto a la variabilidad de la media, la desviación y la autocorrelación de la demanda, se observó que no se mantenía constante, por tanto, se trata de una serie no estacionaria y los métodos a utilizar debían tomar en cuenta estas características. Estudios similares se realizaron a cada uno de los medicamentos seleccionados.
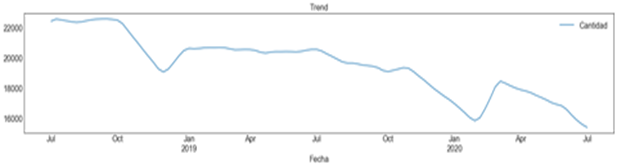
Figura 4
Gráfica de estacionalidad de paracetamol
elaboración propia
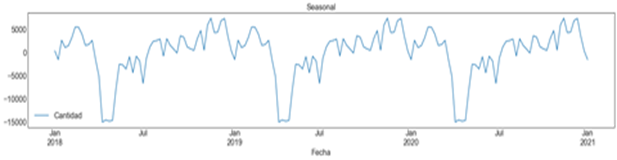
Figura 5
Gráfica de estacionalidad de paracetamol
elaboración propia
3.4 Minería de datos
-
p, que indica el número de términos autorregresivos.
-
d, para establecer el número de veces que la serie debe ser diferenciada para hacerla estacionaria.
-
q, el número de términos de la media móvil invertible.
Para el modelo basado en una red neuronal se seleccionó una red con una sola capa oculta. El entrenamiento en ambos modelos se realizó con el 70% de los datos y el 30% restante se utilizó para probarlos. En la serie de tiempo se tomó, para el entrenamiento los primeros 120 datos, mientras que para la red neuronal se tomó la data de forma aleatoria. La Figura 6 se muestran la gráfica con la demanda de los datos de prueba (color azul) y los datos obtenidos con el modelo de la serie de tiempo generado con el ARIMA (color verde). Asimismo, la Figura 7 muestra la gráfica con los datos de prueba (color azul) y los datos obtenidos con el modelo generado por la red neuronal (color naranja), los datos en este último modelo fueron seleccionados aleatoriamente, por lo que no existe un orden cronológico en las fechas del archivo de prueba.
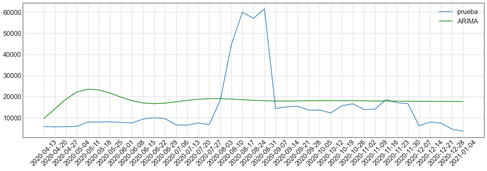
Figura 6
Gráfica de demanda real Vs demanda estimada por la red neuronal
elaboración propia
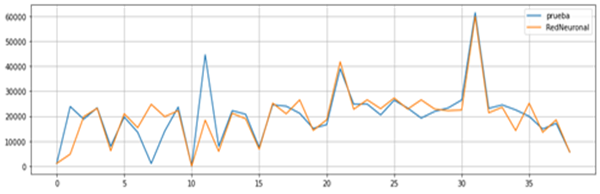
Figura 7
Gráfica de demanda real Vs demanda estimada por la red neuronal
elaboración propia
4. RESULTADOS
Para seleccionar el modelo que mejor se aproxime a la demanda real, se calculó el error cuadrático medio (MSE de sus siglas del inglés) y el error absoluto medio (EAM) de cada modelo y con base a estos resultados se seleccionó el modelo con menor error. Como se puedo observar en la Tabla 3, el modelo con un menor error es el generado por la red neuronal.
Error cuadrático medio y absoluto de cada modelo

elaboración propia
La Figura 8 muestra la demanda que el modelo obtenido con la red neuronal predijo para el mes de enero.
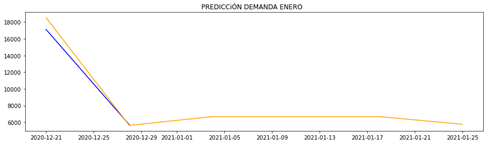
Figura 8
Demanda estimada por la red neuronal para el mes de enero
elaboración propia
5. DISCUSIÓN Y CONCLUSIONES
La innovación tecnológica, en el campo del aprendizaje automático, ofrecen métodos para estimar el comportamiento de las ventas a futuro, información útil en el proceso de planificación al momento de decidir cuánto comprar de un medicamento. Un buen plan deberá satisfacer la demanda de los consumidores, manejar de forma eficiente el presupuesto y reducir tanto los costos de almacenamiento como la posibilidad de que éstos caduquen en las estanterías.
Se generó un modelo para predecir la demanda de los medicamentos que en un periodo de tiempo (mensual, trimestral, semestral) tienen movimientos en sus inventarios y muestran un comportamiento estacional y cíclico. Los medicamentos con demandas muy pequeñas (1 o 2 unidades mensuales) y con demanda esporádica, sujetos a eventos estocásticos, no fueron tomados en cuenta en este trabajo. Por tanto, de los 310 ítems que se adquieren en la farmacia se elaboraron modelos predictivos, en este trabajo, sólo a 14 medicamentos, ya que sus ventas superaron las 1000 unidades (ver Tabla 1).
Dado que las demandas de los medicamentos pueden sufrir cambios en el tiempo, es necesario actualizar cada modelo de forma automática. Por ejemplo, a medida que los casos de hospitalización por contagios del COVID-19 disminuyan, la demanda de algunos medicamentos cambiará y, por tanto, los modelos predictivos se deben actualizar. El uso de modelos predictivos permite a los sistemas aprender de los nuevos comportamientos, a fin de que sus modelos se ajusten a los cambias de los consumidores.
Además de la demanda estimada por los modelos, es necesario estimar el nivel mínimo de inventario que se debe mantener de los medicamentos con demandas periódicas; para ello, es necesario tener en cuenta el tiempo de entrega de los proveedores y la demanda estimada en ese periodo de tiempo. El nivel mínimo garantiza la demanda durante el tiempo de reposición del inventario.
Los modelos generados serán integrados al Sistema de Administración, para apoyar el proceso de planificación de compras en la farmacia.
Finalmente, los modelos evaluados en este trabajo, al estar integrados en un sistema de aprendizaje, podrán ser usados en industrias o empresas donde las preferencias de los consumidores cambien periódicamente, pudiendo adaptar los patrones de compra a estos cambios, lo que permitirá contar con planes de compras alineados a estos comportamientos.
6. REFERENCIAS BIBLIOGRÁFICAS
Ahmed, N., and Farzana, F. (2020). Forecasting supply chain sporadic demand using support vector machine approaches. Fuzzy Sets and Systems, 10, 87-102.
Álvarez-Rodríguez, D. A., Normey-Rico, J. E., and Flesch, R. C. C. (2017). Model predictive control for inventory management in biomass manufacturing supply chains. International Journal of Production Research, 55(12), 3596-3608. https://doi.org/10.1080/00207543.2017.1315191
Fayyad, U., Piatetsky-Shapiro, G., and Smyth, P. (1996). The KDD process for extracting useful knowledge from volumes of data. Communications of the ACM, 39(11), 27-34.
Frank, R. J., Davey, N., and Hunt, S. P. (2001). Time series prediction and neural networks. Journal of intelligent and robotic systems, 31(1), 91-103.
Fernández, M. I., Chanfreut, P., Jurado, I., and Maestre, J. M. (2020). A Data-Based Model Predictive Decision Support System for Inventory Management in Hospitals. IEEE Journal of Biomedical and Health Informatics, 25(6), 2227-2236. https://doi.org/10.1109/JBHI.2020.3039692
Gunasekaran, A., Papadopoulos, T., Dubey, R., Wamba, S. F., Childe, S. Hazen, B., and Akter, S. (2017). Big data and predictive analytics for supply chain and organizational performance. Journal of Business Research, 70, 308-317. https://doi.org/10.1016/j.jbusres.2016.08.004
Gutiérrez-Alcoba, A., Rossi, R., Martin-Barragan, B., and Hendrix, E. M. (2017). A simple heuristic for perishable item inventory control under non-stationary stochastic demand. International Journal of Production Research, 55(7), 1885-1897. https://doi.org/10.1080/00207543.2016.1193248
Hakim, I. M., and Ulfah, W. M. (2019, September). Model Development to Determine Optimal Drugs Inventory in Indonesia Public Health Services. In Proceedings of the 2019 5th International Conference on Industrial and Business Engineering (pp. 28-32). https://doi.org/10.1145/3364335.3364368.
Hamilton, J. D. (2020). Time series analysis. Princeton University Press.
Janssen, L., Sauer, J., Claus, T., and Nehls, U. (2018). Development and simulation analysis of a new perishable inventory model with a closing days constraint under non-stationary stochastic demand. Computers & Industrial Engineering, 118, 9-22. https://doi.org/10.1016/j.cie.2018.02.016
Jurado, I., Maestre, J. M., Velarde, P., Ocampo-Martínez, C., Fernández, I., Tejera, B. I., and del Prado, J. R. (2016). Stock management in hospital pharmacy using chance-constrained model predictive control. Computers in biology and medicine, 72, 248-255. https://doi.org/10.1016/j.compbiomed.2015.11.011
Liu, I., Colmenares, E., Tak, C., Vest, M. H., Clark, H., Oertel, M., and Pappas, A. (2021). Development and validation of a predictive model to predict and manage drug shortages. American Journal of Health-System Pharmacy, 78(14), 1309-1316. https://doi.org/10.1093/ajhp/zxab152
Maestre, J. M., Fernández, M. I., and Jurado, I. J. C. E. P. (2018). An application of economic model predictive control to inventory management in hospitals. Control Engineering Practice, (71), 120-128. https://doi.org/10.1016/j.conengprac.2017.10.012
Miller, S., El-Bahrawy, A., Dittus, M., Graham, M., and Wright, J. (2020, April). In Proceedings of the web conference 2020 (pp. 2669-2675). https://doi.org/10.1145/3366423.3380022
Nasr, W. W., and Elshar, I. J. (2018). Continuous inventory control with stochastic and non-stationary Markovian demand. European Journal of Operational Research, 270(1), 198-217.
Pavlyshenko, B. M. (2019). Machine-learning models for sales time series forecasting. Data, 4(1), 15. https://doi.org/10.3390/data4010015
Pulido-Rojano, A., Pizarro-Rada, A., Padilla-Polanco, M., Sánchez-Jiménez, M., and De-la-Rosa, L. (2020). Un enfoque de optimización para costos de inventario en modelos de inventario probabilísticos: Un caso de estudio. Ingeniare. Revista chilena de ingeniería, 28(3), 383-395. http://dx.doi.org/10.4067/S0718-33052020000300383
Sinaga, S., Pertiwi, L. S., and Ardian, T. (2016). Inventory simulation optimization under non stationary demand. International Journal of Applied Engineering Research, 11(1), 524-529.
Susarla, N., and Karimi, I. A. (2018). Integrated production planning and inventory management in a multinational pharmaceutical supply chain. In Computer aided chemical engineering, 41, 551-567). https://doi.org/10.1016/B978-0-444-63963-9.00022-1Getr
Tunc, H., Kilic, O. A., Tarim, S. A., and Eksioglu, B. (2011). The cost of using stationary inventory policies when demand is non-stationary. Omega, 39(4), 410-415. https://doi.org/10.1016/j.omega.2010.09.005
Zhang, Y., Hua, G., Wang, S., Zhang, J., and Fernandez, V. (2018). Managing demand uncertainty: Probabilistic selling versus inventory substitution. International Journal of Production Economics, 196, 56-67. https://doi.org/10.1016/j.ijpe.2017.10.001
Zhou, Q., Han, R., Li, T., and Xia, B. (2019). Joint prediction of time series data in inventory management. Knowledge and Information Systems, 61(2), 905-929. https://doi.org/10.1007/s10115-018-1302-y
