Eléctrica
Evaluación de descriptores para la detección automática de fallas en fabricación utilizando máquinas de soporte vectorial
Merger of Descriptors for Automatic Detection of Failures in Manufacturing Using Support Vector Machine

Evaluación de descriptores para la detección automática de fallas en fabricación utilizando máquinas de soporte vectorial
Scientia Et Technica, vol. 24, núm. 4, pp. 566-572, 2019
Universidad Tecnológica de Pereira
Recepción: 02 Mayo 2019
Aprobación: 20 Diciembre 2019
Resumen: Este documento presenta la evaluación de un método de clasificación de fallas en productos terminados utilizando la combinación de descriptores de color, forma y textura. Se utiliza una Máquina de Vectores de Soporte multiclase (SVM-Support Vector Machine) y se construye una base de datos anotada capturando botellas de plástico con 11 situaciones de fabricación entre botellas en buen estado y botellas con imperfectos como rasgaduras, golpes, hendiduras, etc; bajo diferentes condiciones no controladas (ruido, iluminación, escala, entre otras). La etapa de fusión propone una combinación lineal de características y para calcular el desempeño de descriptores y fusión de datos, se utilizó una metodología de validación cruzada aplicando el método de Montecarlo. La configuración de SVM utiliza la metodología multiclase “One-vs-All” con Kernel Radial Gaussiano. La detección se realiza inicialmente aplicando descriptores individuales y combinados.
Palabras clave: Fusión de Datos, Máquina de Soporte Vectorial, Descriptores de Color, Forma y Textura, Control de Calidad.
Abstract: This document presents the evaluation of a method of classifying faults in finished products using the combination of color, shape and texture descriptors. Subsequently, a Multiclass Support Vector Machine (SVM-Support Vector Machine) is used to detect possible faults. To validate the model an annotated database is built capturing plastic bottles with 11 manufacturing situations, including bottles in good condition and bottles with imperfections such as tears, bumps, cracks, etc. A cross validation was used applying the Monte Carlo method in order to obtain the statistical relevance of the proposed method. The SVM configuration uses the "One-vs-All" multiclass methodology with Gaussian Radial Kernel. A comparison is made with other art state methods in order to show advantages and disadvantages of the proposal. This work allows us to see the contribution of each descriptor modality in the classification of faults, where an efficiency greater than 85% is observed, due to the fusion of the descriptors.
Keywords: Data fusion, Descriptors, Quality control, Supervised Learning, Support Vector Machine.
I. INTRODUCCIÓN
El continuo desarrollo del sector industrial, la demanda de productos exige que estos cumplan con estándares de calidad, más aún cuando se desea competir en mercados globales que se rigen por los tratados de libre comercio [1, 2]. Es común encontrar la necesidad de fabricación en masa y en poco tiempo. Estos factores generan la fabricación de producto con fallas, por lo que la inspección visual es necesaria. Sin embargo, el proceso se realiza por personal calificado y se ve afectado por errores de humanos. Todo esto ha forzado a la implementación de procedimientos que permitan identificar cualquier irregularidad en los productos [3]. En Visión por computador se ha logrado generar una amplia gama de aplicaciones que van desde los sistemas de control e inspección, sistemas de movimiento, automatización, entre otros [4, 5, 6]. Los métodos utilizados en estos sistemas, utilizan características que facilitan la descripción de patrones de color, forma y textura presentes en los productos evaluados. Estos cambios son considerados importantes para describir las características únicas del patrón que se puede presentar en un proceso de control de calidad, tales como golpes, rayones, cambios de forma, etc [7, 8, 9, 10]. Aunque muchas de estas metodologías han demostrado ser útiles para el reconocimiento de patrones, en los ambientes industriales no siempre se cuenta con la posibilidad de garantizar unas condiciones controladas de trabajo (iluminación, vibración, entre otros), bajo las cuales pueda operar el sistema de identificación. Estas condiciones hacen que algunos descriptores no se adapten a diferentes situaciones. Ejemplo de ello se evidencia con los descriptores de color, los cuales no son robustos a cambios de iluminación [11]; en el caso de los descriptores morfológicos, estos no son robustos a oclusiones parciales o totales del objetivo o al ángulo con que incide la cámara sobre este [12]. Esto evidencia que un solo tipo de descriptor no es suficiente para caracterizar una amplia variedad de patrones en ambiente no estructurado, por lo que la combinación de los mismos es un enfoque que mejora el factor discriminante de una observación aprovechando las ventajas individuales de cada descriptor [13, 14]. Por lo tanto, no se reporta en el estado del arte un estudio donde se evalué la eficiencia para descripción de patrones en una base de datos fallas de fabricación utilizando la combinación de descriptores de color, forma, textura y SVM (Support Vector Machine) [15, 16, 17]. Este trabajo compara los métodos clásicos de identificación de patrones en inspección visual como lo son histogramas RGB (Red, Blue, Green), CMYK (Cyan, Magenta, Yellow, Key), TSL (Tinte, Saturation, Lightness), SURF (Speeded-Up Robust Features), MSER (Maximally Stable Extremal Regions), HOG (Histogram of Oriented Gradients), SOBEL y CANNY, con el método de combinación de descriptores propuesto, con el fin de demostrar que la combinación descriptores ofrece un mejor desempeño de detección de patrones que las metodologías antes mencionadas. Para el estudio se construye una base de datos anotada con la captura de botellas de plástico (en buen y mal estado), donde se capturan 10 diferentes tipos de fallos (hendiduras, rayones, golpes, etc). Posteriormente se plantea una etapa de extracción de características utilizando los descriptores nombrados anteriormente y se construye una matriz de entrenamiento, donde se evalúan diferentes combinaciones de descriptores. Por último, se realiza un experimento de Montecarlo para validar el funcionamiento del clasificador SVM.
II. METODOLOGÍA
El objetivo principal de este trabajo es el análisis de la combinación de descriptores (color, forma y textura) y comparar su rendimiento con los métodos clásicos de identificación de patrones como RGB, CMYK, TSL, SURF, MSER, HOG, SOBEL y CANNY. La metodología propuesta consta de cinco etapas fundamentales. En la primera etapa se construyó la base de datos anotada con el fin de realizar la extracción de características. Posteriormente se combinaron los datos a nivel de características para formar un descriptor con mayor poder discriminante y así clasificar utilizando aprendizaje supervisado (SVM). Por último, se muestra el proceso de validación cruzada que tuvo como objetivo la evaluación de la eficiencia de cada descriptor planteado con clasificación SVM. En la Fig. 1 se puede observar el diagrama de bloques de la metodología.
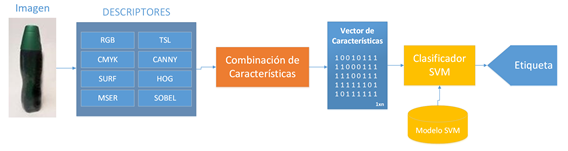
Fig. 1
Esquema general de implementación.
Autor
A. Construcción de la base de datos
La base datos construida en este trabajo, no buscó generar un ambiente controlado de iluminación, sin embargo, se buscó para evitar problemas de segmentación. Este control se debe a que el enfoque principal de este trabajo es la fusión de características y clasificación de patrones. La base de datos construida se creó con botellas plásticas elegidas por su morfología y color, características ideales para el objeto de estudio de este trabajo. La base de datos presenta secciones difusas de color negro que tienen como objetivo no revelar la marca de las botellas debido a derechos de copyright. Cabe resaltar que el trabajo y los resultados se obtuvieron con las imágenes originales sin difuminación. La base de datos fue adquirida con la cámara del celular Samsung S3-SGH I-747 a una resolución de 720 x 1280. Se capturaron 50 ejemplos de cada patrón involucrando diversas situaciones de fabricación como hendiduras, rayones, falta de etiquetas, entre otros. Cada patrón se observa en la tabla I y Fig. 2. Los recuadros de color rojo destacan las características que definen cada clase. Cabe resaltar que esta base de datos tiene gran variedad de rotaciones, escalas y perspectiva para cada una de las clases propuestas. Esto hace que esta base de datos tenga mayor nivel de dificultad para ser clasificada por modelos de aprendizaje de máquina.

Autor

Fig. 2
Ejemplo para clases de botellas.
Auto
B. Extracción de características
El proceso de extracción de características tiene como objetivo mejorar la separabilidad de los datos provistos por el sensor. En este trabajo se proponen tres descriptores de color (Histogramas: RGB, TSL y CMYK), tres descriptores de forma (HOG, Histogramas SURF y MSER) y dos descriptores de textura (Histogramas Sobel y Canny). Para así observar sus efectos de descripción en la clasificación con una SVM.
Histograma con características de Color:
Los histogramas de color son una representación de la distribución del color que existen en una escena. Para la construcción del histograma se obtiene la información de intensidad de cada canal del espacio y se calcula el histograma por canal utilizando un número N de bins para el conteo del mismo.
Para la construcción de los histogramas se propone las configuraciones de la tabla II.

Histograma con características de Textura:
Los métodos como Canny y Sobel identifican información de interés como cambios bruscos de intensidad (bordes) que son asociados a las texturas presentes en el objeto [21]. Para el realizar el cálculo de Sobel, se realiza la convolución de la imagen con los Kernels propuestos en [22]. Para obtener el descriptor, se calcula la distribución espacial de las coordenadas [x,y] de los bordes y se calcula un histograma de coordenadas con 50 bins. Esto permite obtener el vector de características (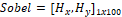 ).
).
Para aplicar el método de Canny, se aplica el mismo procedimiento de Sobel hasta obtener la magnitud G, luego se aplica supresión de no máximos para eliminar bordes falsos. Por último, se realiza el proceso de histéresis para determinar el rango de magnitudes de gradiente aceptables [23]. Los umbrales que se utilizados en la histéresis va desde 4 a 7. El descriptor se obtiene calculando un histograma con 50 bins (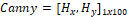 ).
).
Descriptor HOG: Este es un descriptor morfológico que describe la orientación de los bordes del objeto. Este método divide la imagen en celdas y calcula el histograma proveniente de los gradientes orientados, identificando en qué dirección y magnitud [24]. En el cálculo del descriptor HOG, se utiliza la configuración de 0 a 360° el cual es adecuado para descripción de objetos no humanos, se utiliza un tamaño de celda de 32 x 32 sin traslape generando un descriptor de dimensión 1 x 3420.
Descriptor SURF: El método SURF es una descripción visual de una escena utilizando puntos de interés que tiene robustez a cambios de escala y rotación [25]. Para realizar el cálculo del descriptor, se computa el vector de características generado por cada punto de interés y posteriormente se calcula la media 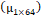 , desviación estándar
, desviación estándar 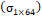 y curtosis
y curtosis 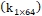 para cada una de las dimensiones utilizando la información de todos los puntos. Gracias a esto se obtiene el vector de características, en Ec.1.
para cada una de las dimensiones utilizando la información de todos los puntos. Gracias a esto se obtiene el vector de características, en Ec.1.
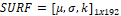 (1)
(1)Descriptor MSER: Este es un método de reconocimiento de regiones utilizando la intensidad entre píxeles. Para realizar el cálculo de una región se evalúa la conexión de un conjunto de píxeles umbralizando el nivel de intensidad con un valor arbitrario t. Posteriormente se realiza una medida de inestabilidad 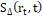 , evaluando la taza de cambio de la región para diferentes tamaños de umbral. En la Ec.2 se puede observar el cálculo del
, evaluando la taza de cambio de la región para diferentes tamaños de umbral. En la Ec.2 se puede observar el cálculo del 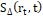 .
.
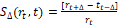 (2)
(2)Se considera que una región es máximamente estable si 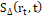 es mínimo para t [25]. Para realizar el cálculo del descriptor, se computa el vector de características generado por cada punto de interés y posteriormente se calcula la media , desviación estándar y curtosis , utilizando la información de todos puntos. Este procedimiento permite obtener un vector de características Ec.3.
es mínimo para t [25]. Para realizar el cálculo del descriptor, se computa el vector de características generado por cada punto de interés y posteriormente se calcula la media , desviación estándar y curtosis , utilizando la información de todos puntos. Este procedimiento permite obtener un vector de características Ec.3.
 (3)
(3)C. Combinación de datos
La combinación de datos es fundamental para obtener un mayor rendimiento dado las fortalezas del espacio de características que cada descriptor puede brindar. En este trabajo la combinación de los descriptores calculados en la etapa de extracción de características consiste en la concatenación de los descriptores elegidos para formar un vector de características extendido, que aumenta las dimensiones del espacio de características, aumentado la probabilidad de mejorar la frontera de separación para el método de aprendizaje, tal y como se aprecia en la Fig. 3.
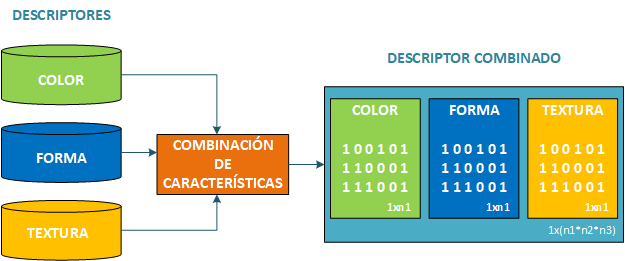
Fig. 3.
Fusión de datos de los tres descriptores mencionados.
Autor
D. Validación del Modelo de Clasificación
En esta etapa se evalúa el desempeño del clasificador considerando la entrada de elementos desconocidos para el mismo. Para lograr este procedimiento, se utiliza el método Montecarlo para encontrar la convergencia del desempeño y garantizar la relevancia estadística de la prueba. Para la etapa de clasificación, se utilizó una máquina de vectores de soporte multiclase con estrategia de clasificación “One-vs-All”; este método de aprendizaje utiliza un Kernel gaussiano con radio adaptativo y la estimación de los vectores de soporte es calculada con el método Sequential Minimal Optimization (SMO). Para realizar el procedimiento de evaluación del modelo se utilizó una estrategia de validación cruzada, fraccionando la base de datos con el 70% para el entrenamiento y 30% para evaluación en cada iteración de MonteCarlo; este proceso realiza las iteraciones con criterio de paro 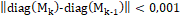 , donde
, donde 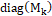 es el vector generado por la diagonal de la matriz de confusión y k es la iteración actual. Las estadísticas obtenidas en el experimento consisten en el cálculo de la matriz de confusión y el comportamiento promedio del porcentaje de acierto y su desviación estándar σ.
es el vector generado por la diagonal de la matriz de confusión y k es la iteración actual. Las estadísticas obtenidas en el experimento consisten en el cálculo de la matriz de confusión y el comportamiento promedio del porcentaje de acierto y su desviación estándar σ.
III. RESULTADOS Y DISCUSiÓN
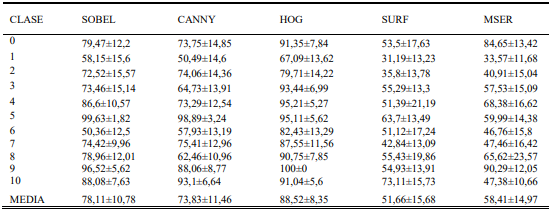
En esta sección se presentan los resultados al validar el desempeño de clasificación de 11 patrones propuesta en la base de datos. Esta etapa presenta los resultados obtenidos al validar el desempeño de la clasificación aplicando el método Montecarlo. En los resultados solo se presenta la diagonal principal de la matriz de confusión debido a que estos valores corresponden al porcentaje de acierto de clasificación por clase; los demás valores de esta matriz indican el error en la clasificación. Esto optimiza la presentación de los resultados ya que las matrices de confusión consumen demasiado espacio, dificultando el análisis de estos. Inicialmente se presentará el resultado de detección utilizando individualmente cada descriptor, posteriormente se realiza un análisis comparativo para determinar el método con mayor descripción en detección de patrones y así realizar la fusión de descriptores. Por último, se muestra los resultados obtenidos al clasificar las fallas utilizando la fusión para después realizar una comparación detallada de metodologías.
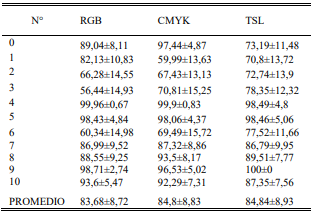
La tabla III, muestra que los descriptores de color evidencian resultados con desempeños mayores al 80% de eficiencia, variando en el rango de [82,13-100]% para la mayoría de sus clases. De los descriptores de color, TSL presenta detección del 100% para la clase 9. Como se observa en la tabla IV, el descriptor HOG también identifica la clase 9 con un acierto del 100% y su rendimiento para las demás clases es confiable. Los resultados de los descriptores de textura presentan clases con eficiencias que superan el 80%, pero su nivel general de clasificación es bajo. Finalmente se observa que los descriptores SURF y MSER presentan los resultados más bajos de eficiencia teniendo casos como el de la clase 1.
Autor
De los descriptores morfológicos, HOG es la metodología que presenta la mayor eficiencia promedio en la aplicación con un valor de 88,55±8,35%, siendo un valor aceptable en este tipo de aplicaciones, tal y como se observa en la tabla IV. La eficiencia de los modelos de color es mayor al 80%, lo que indica que los descriptores basados en estos modelos son aptos para este tipo clasificación, sin embargo, es importante tener en cuenta que las clases 1, 2, 3 y 6 presentan la eficiencia más baja con un rango de variación entre 56,44% y 82,13%. Se evidencia que los resultados obtenidos con los métodos SURF y MSER presentan la eficiencia más baja del conjunto descriptores, razón por la cual, no sería conveniente su uso en la detección de las clases propuestas ya que no detectan alguna clase con un desempeño mayor al 80%.
Autor
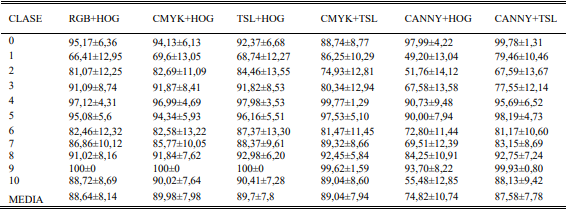
Dado a los resultados de las tablas III y IV, se evidencia que existen patrones difíciles de detectar por lo que la fusión de algunos descriptores puede ayudar a resaltar la discriminación para todas las clases utilizando las ventajas individuales de cada característica.
La tabla V muestra que la combinación RGB+HOG tiene un aumento significativo en la eficiencia de las clases 0, 2, 3, 6, 8, 9 y 10. Solo la clase 1 presenta un desempeño menor (66,41±12,45%) al de los descriptores individuales, ya que el resto de las clases mantuvieron una buena eficiencia. La combinación CMYK+TSL presenta un rendimiento confiable con detecciones mayores al 80% excepto para la clase 2. La eficiencia general de las clases presenta un aumento significativo, sin embargo, en algunos casos como en la clase 10, la eficiencia de los descriptores RGB, CMYK y HOG era superior antes de la fusión. Para el caso CANNY+HOG, se muestra un bajo rendimiento en la detección de la mayoría de sus clases, sin embargo, se alcanza apreciar que las clases 0 y 9 presentan eficiencias cercanas al 100%. Su variación es alta, superando el 10% de error, lo que lleva a pensar que el descriptor CANNY empeora el resultado de la fusión. Se puede observar que más del 90% de las detecciones en la fusión de datos varían en el rango [80-100] %. Este rango de eficiencia se considera adecuado y permite una detección confiable de estos patrones. Por último, se muestra que la fusión de descriptores brinda mejores resultados que al usar cada descriptor individualmente, logrando obtener resultados en el rango [74,82-89,7] %.
Autor
IV. CONCLUSIONES
Se puede concluir que realizó la evaluación de descriptores de forma, textura y color para el reconocimiento de fallas de un producto terminado, aplicando combinación de características y Máquinas de Soporte Vectorial. Gracias a esto se logra obtener desempeños superiores al 88% de eficiencia para las diferentes fusiones propuestas. Además, se verifica la capacidad de cada descripción individual que tiene los métodos para la identificación de patrones con variaciones no controladas de forma, color, textura, perspectiva, escala y rotación.
El descriptor que mejor se adapta a las condiciones no controladas de la base de datos, es el descriptor HOG logrando un desempeño del (88,52±8,35%). Los descriptores de color, demuestran ser aptos para la caracterización de este tipo de patrones logrando clasificaciones con eficiencias de (83,68±8,72%) usando RGB, (84,8±8,83%) con CMYK y (84,84±8,93%) para TSL. El modelo TSL presenta rendimiento confiable en este tipo de aplicaciones superando los modelos RGB y CMYK.
El análisis de los descriptores permite conocer las ventajas individuales de cada descriptor para la clasificación de fallas utilizando SVM. Al realizar la combinación de descriptores, se comprueba que el rendimiento en la identificación mejora notablemente al lograr eficiencias que superan el 91% de eficiencia. Esto se debe a que las fallas presentadas son ampliamente descritas por espacios de color y sus variaciones en forma son lo suficientemente notables para que clasificador pueda identificarlas con la combinación de estas características. La metodología para la combinación de datos presenta un alto desempeño para la identificación de características de un objeto. Se demuestra que la combinación permite aumentar la eficiencia en la detección para este tipo de aplicaciones y la mejor combinación (TSL&HOG) presenta una eficiencia del (89,70±7,8%).
REFERENCIAS
[1] Núñez J., Carvajal J.C., Bautista L.A. “El TLC con Estados Unidos y su impacto en el sector agropecuario colombiano: Entre esperanzas e incertidumbres,” Revista Electrónica de la facultad de Derecho, vol.1 (2), pp. 118-133, 2004. DOI: 10.15332/s2248-4914.2012.0020.03
[2] Contreras V.A., Gutiérrez C., León M.E., Cadena Y., León F.E. “Iso 9001-2: un compromiso posible en la era del TLC,” Revista Teoría Y Praxis Investigativa, vol.3 (2), pp. 52-60, 2008. DOI: 10.1109/IST.2011.5962196
[3] Arley A.B, Calvo A.F. “Escáner 3D para control de calidad de piezas metalúrgicas,” Trabajo de Grado, Facultad de Ingeniería, Universidad Tecnológica de Pereira. Pereira, 2012. DOI http://hdl.handle.net/11059/4 705
[4] Florez N., Sánchez L.P., Ramírez F.G. “Visión Artificial para Detección de Fallas Estructurales en Botellas de Vidrio,” Tesis de Maestría, Instituto Politécnico Nacional. Ciudad de México. 72 p, 2011.
[5] C. Relf, “Image acquisition and processing with LabVIEW,” Boca Raton, Flor.: CRC Press, 2004. pp. 85-137.
[6] Murray C.J. “3D machines vision comes into focus.” Trade Publication, vol.67 (2), pp. 36, 2014.
[7] K. van de Sande, T. Gevers and C. Snoek, "Evaluating Color Descriptors for Object and Scene Recognition," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 9, pp. 1582-1596, 2010.
[8] C. Spinola et al., "Image processing for surface quality control in stainless steel production lines," IEEE International Conference on Imaging Systems and Techniques, Thessaloniki, pp. 192-197, 2010.
[9] M. Sharifzadeh, S. Alirezaee, R. Amirfattahi and S. Sadri, "Detection of steel defect using the image processing algorithms," IEEE International Multitopic Conference, Karachi, pp. 125-127, 2008.
[10] P. L. Mazzeo, L. Giove, G. M. Moramarco, P. Spagnolo and M. Leo, "HSV and RGB color histograms comparing for objects tracking among non overlapping FOVs, using CBTF," 8th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Klagenfurt, pp. 498-503, 2011.
[11] A. E. Abdel-Hakim and A. A. Farag, “CSIFT: A SIFT Descriptor with Color Invariant Characteristics,” IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06), pp. 1978-1983, 2006.
[12] Akita, R. M., “User based data fusion approaches,” Proceedings of the Fifth International Conference on Information Fusion, Vol. 2, 1457-1462, 2002.
[13] Sarmiento M., Pedro. "Reseña de "El cerebro y el mito del yo. El papel de las neuronas en el pensamiento y el comportamiento humanos" de Rodolfo Llinás". Persona y Bioética, vol. 7, no. 19, Editorial Universidad de La Sabana, pp. 84-87, 2003.
[14] F. Khan, J. van de Weijer and M. Vanrell, “Modulating Shape Features by Color Attention for Object Recognition,” International Journal of Computer Vision, vol. 98, no. 1, pp. 49-64, 2011.
[15] H. Harzallah, F. Jurie and C. Schmid, "Combining efficient object localization and image classification" IEEE 12th International Conference on Computer Vision, Kyoto, pp. 237-244, 2009.
[16] Elfiky, N. M., Khan, F. S., Van De Weijer, J., & Gonzalez, J., “Discriminative compact pyramids for object and scene recognition", Pattern Recognition, Vol 45, Issue 4, pp.1627-1636, 2012.
[17] Mo, S., Cheng, S., & Xing, X., “Hand gesture segmentation based on improved kalman filter and TSL skin color model,” International Conference on Multimedia Technology, Hangzhou, pp. 3543-3546, 2011.
[18] T. Ghosh, S. K. Bashar, S. A. Fattah, C. Shahnaz and K. A. Wahid, "A feature extraction scheme from region of interest of wireless capsule endoscopy images for automatic bleeding detection," IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Noida, pp. 000256-000260, 2014.
[19] William K. Pratt. “Digital Image Processing: PIKS Inside” (3rd ed.). John Wiley & Sons, Inc., New York, NY, USA, 2001.
[20] G. Hao, L. Min and H. Feng, "Improved Self-Adaptive Edge Detection Method Based on Canny," 5th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, pp. 527-530, 2013.
[21] Prats J.M. “Control Estadístico de Procesos Mediante Análisis Multivariante de Imágenes,” Tesis de Doctorado, Universidad Politécnica de Valencia, Valencia, 2005. DOI. 10.15665/rp.v16i2.1495
[22] E. Zaytseva and J. Vitrià, “A search based approach to non maximum suppression in face detection,” 19th IEEE International Conference on Image Processing, Orlando, FL, pp. 1469-1472, 2012. DOI: 10.1109/ICIP:2012.6467148.
[23] Borrego-Jiménez M.A. “Calidad en los procesos gráficos” España. Editorial IC, 1-5 p, 2016.
[24] Bay H., Tuytelaars T., Van Gool L. “SURF: Speeded Up Robust Features,” Computer Vision – ECCV, Lecture Notes in Computer Science, vol 3951. Springer, Berlin, Heidelberg, 2006. DOI: 10.10007/11744023_32
[25] S. Alyammahi, E. Salahat, H. Saleh and A. Sluzek, “A hardware accelerator for real-time extraction of the linear-time MSER algorithm,” IECON - 41st Annual Conference of the IEEE Industrial Electronics Society, Yokohama, pp.9-65, 2015. DOI: 10.1109/IECON.2015.7392966
Notas de autor

Andrés Felipe Calvo
Autor
Was born in February 1988 in Pereira, Colombia. He received his bachelor's degree in electronic engineering and master's degree in electrical engineering from the Technological University of Pereira in 2012 and 2015, respectively. He is a professor and the head of the electronic engineering department at Technological University of Pereira. His research focuses on the application of machine learning systems in industrial and agronomic sectors.

Edward Jhohan Marín García
Autor
Was born in the city of Cartago on May 15, 1980. He graduated as a master’s in electrical engineering at the Technological University of Pereira in 2008, in addition, he is an Electronic Engineer and Electronic Technologist at the University of Quindío, graduated in the years 2006 and 2001 respectively.
He has been a university professor for thirteen (13) years and currently serves as a professor at the Universidad del Valle, Cartago headquarters as a nominee. Today he is the director of the Research Group on Innovation and Development in Applied Electronics (GIIDEA) at the Universidad del Valle, Cartago headquarters. Colombia; specializes in control and instrumentation.

José Bestier Padilla Bejarano
Autor
Was born in armenia, Quindío, Colombia in 1973. Bachelor of Electricity and Electronics, he received the title of Specialist in Communication Networks from the Universidad del Valle in 1999, the master’s in electrical engineering from the Technological University of Pereira in 2011 and is currently studying PhD in Technology and Innovation Management at the Universidad Pontificia Bolivariana. Research Professor of the program in Technology in Electronic Instrumentation of the University of Quindío since 2006. Leader of the research group in technological developments - GIDET - attached to the Faculty of Basic Sciences of the University of Quindío. Expert in topics of electronic instrumentation and electrical circuits, innovation manager, consultant in technological development and technology transfer issues.