ARTÍCULOS
Interpretación auditiva de enunciados interrogativos directos pronominales con y sin matiz de cortesía por aprendientes coreanos en clases de nivel avanzado: un estudio comparativo
Auditive interpretation of pronominal questions with and without courtesy nuance by native Korean speaker learners of Spanish in advanced level classes: a comparative study
Interpretación auditiva de enunciados interrogativos directos pronominales con y sin matiz de cortesía por aprendientes coreanos en clases de nivel avanzado: un estudio comparativo
marcoELE. Revista de Didáctica Español Lengua Extranjera, núm. 30, 2020
MarcoELE
Recepción: 06 Marzo 2020
Aprobación: 20 Marzo 2020
Resumen: En este artículo se efectúa un análisis de errores cometidos por 60 oyentes (Avanzado 2) en la interpretación auditiva de un estímulo compuesto por enunciados declarativos, enfáticos e interrogativos directos, tanto de valor absoluto como pronominales sin matiz de cortesía, para comparar sus resultados con los obtenidos en nuestro análisis de errores previo aplicado a 61 oyentes (Avanzado 1) sobre la interpretación auditiva de un estímulo formado por los mismos enunciados con la única diferencia de que los interrogativos directos pronominales sí poseían matiz de cortesía. Los oyentes de ambos grupos fueron alumnos hablantes nativos de coreano matriculados en clases de conversación de nivel avanzado (B2), al tiempo que que los informantes de los estímulos fueron los mismos en ambas ocasiones. Buscamos así confirmar nuestra hipótesis, que predice una mayor incidencia relativa de errores del tipo de enunciado interrogativo directo pronominal interpretado como declarativo [(?p) por (.)] cuando los enunciados interrogativos pronominales del estímulo no poseen matiz de cortesía, como también observar las diferencias que la sustitución en el estímulo de los enunciados interrogativos pronominales con matiz de cortesía por los desprovistos de él introducen en las jerarquías de clases de enunciados por su grado de dificultad interpretativa para el perfil de estudiante considerado.
Palabras clave: interpretación auditiva de enunciados, enunciados interrogativos directos pronominales, matiz de cortesía, alumnos hablantes nativos de coreano, nivel avanzado (B2).
Abstract: This paper presents an analysis of errors committed by 60 listeners (Group 2) on the auditive interpretation of a stimulus composed of declarative, emphatic and interrogative sentences (absolute and pronominal questions without nuance of courtesy), to compare its results with those obtained in our previous error analysis applied to 61 listeners (Group 1) on the auditive interpretation of a stimulus formed by the same sentences with only one difference: pronominal questions did have a shade of courtesy. The listeners of both groups were native Korean speaker students enrolled in advanced level conversation classes (B2) and the two informants of the stimuli (male and female) were the same for both groups (1 and 2). The final goal was double. First, to confirm the hypothesis that predicts a higher relative frequency of pronominal questions interpreted as declarative when pronominal questions do not have nuance of courtesy. Second, to observe the differences that the substitution in the stimulus of pronominal questions with nuance of courtesy by the ones without it involves into the sentence type ranking by interpretative difficulty.
Keywords: auditive interpretation of sentences, pronominal questions, courtesy nuance, native Korean speaker learners of Spanish, advanced level (B2).
1. INTRODUCCIÓN
1.1. OBJETIVOS
El presente trabajo aborda un análisis de errores acaecidos en la interpretación auditiva de enunciados declarativos, enfáticos, interrogativos directos de valor absoluto e interrogativos directos pronominales sin matiz de cortesía y compara sus resultados con los obtenidos en un estudio anterior (Barajas, 2018) en el que los enunciados interrogativos directos pronominales presentes en el estímulo sonoro sí poseían matiz de cortesía. Los dos experimentos tuvieron por oyentes a alumnos de la Universidad Hankuk de Estudios Extranjeros (HUFS por sus siglas en inglés), los cuales eran estudiantes de conversación en Español Lengua Extranjera (ELE) al tiempo que hablantes nativos de coreano, cuya competencia comunicativa en español era de nivel avanzado -B2 del Marco Común Europeo de Referencia para las Lenguas (MCER) y del Plan Curricular del Instituto Cervantes (PCIC)-.
Con tal ejercicio comparativo buscamos confrontar el grado de dificultad en la interpretación auditiva de cada una de las cuatro clases de enunciados del estímulo sonoro cuando este presentaba sus enunciados interrogativos directos pronominales provistos de matiz de cortesía (condición 1) con el grado de dificultad propio cuando dicho estímulo los presentaba sin el mencionado matiz (condición 2). Para ello, efectuamos escalas de clases de enunciados en función del grado de dificultad interpretativa de estos para el perfil de aprendiente considerado bajo ambas condiciones experimentales y las contrastamos entre sí. (Asumimos en este punto el axioma de que una mayor frecuencia relativa de errores en la interpretación de una determinada clase de enunciado implica una mayor dificultad interpretativa de esa clase de enunciado).
Nuestras investigaciones, inspiradas en las que llevara a cabo Cortés (1998; 1999) con alumnos sinohablantes nativos de varios niveles de competencia comunicativa en español, responden al empeño de llevar a la práctica la recomendación de dicho autor (Cortés, 2002a: 72) que consiste en secuenciar los contenidos adscritos a la enseñanza / aprendizaje de la entonación en ELE por orden de dificultad creciente para el perfil de alumno del que se trate, mediante un diseño curricular acorde que encuentre su reflejo en los sílabos (objetivos didácticos, actividades, evaluación, etc.) de los diferentes cursos en función del nivel de competencia comunicativa en español del discente en cada uno de estos. No en vano, nuestro diseño experimental no es otro que el propuesto por el mismo Cortés a tal efecto (2002b: 78-79 y 155-158).
1.2. HIPÓTESIS DE TRABAJO
Para la formulación de la hipótesis que buscamos verificar con nuestra investigación nos basamos en las similitudes y diferencias existentes en los patrones entonativos o perfiles melódicos de los enunciados declarativos, interrogativos directos de valor absoluto e interrogativos directos pronominales con y sin matiz de cortesía, en español y en coreano.
Así, consideramos que, como puede leerse en Blecua et al. (2011: 467-468, 471 y 475):
Una de las diferencias entre la entonación enunciativa y la interrogativa absoluta en castellano radica en la terminación final, que en el caso de la interrogativa es marcadamente ascendente (…). El contorno interrogativo se inicia en un tono medio en las sílabas iniciales. A continuación se produce un descenso del tono durante la primera sílaba acentuada seguido de un descenso del tono que ocupa el cuerpo central de la interrogación hasta la tónica final (el núcleo), que siempre se pronuncia en un tono grave; finalmente, a partir del núcleo, se produce la trayectoria marcadamente ascendente típica de la interrogación absoluta castellana. Cuando la secuencia contiene una palabra oxítona final, todo el movimiento terminal grave y ascendente se concentra en esta sílaba.
(…) El contorno melódico de las preguntas pronominales tiene una forma típicamente declarativa. Por un lado, se caracteriza por la presencia de un movimiento melódico ascendente inicial que se sitúa sobre el pronombre interrogativo. Después de este, la línea melódica va descendiendo de forma suave en el decurso de la frase hasta la última sílaba tónica. A partir de esta, el descenso se hace aún mayor, ya que el núcleo recibe un acento tonal de tipo descendente. Por último, las sílabas postónicas se producen en un tono grave.
(…) Las construcciones interrogativas parciales, también denominadas pronominales y adverbiales, (…) presentan por lo general una configuración descendente en su parte final. Tradicionalmente se ha observado la semejanza melódica de estos enunciados con los aseverativos, pues el pico tonal suele coincidir, en ambos casos, con el alcanzado en la primera sílaba acentuada, que suele ser el pronombre o el adverbio interrogativo. A partir de este, suele iniciarse una declinación que se resuelve en una cadencia descendente.
Todo ello, junto a la observación de que el patrón entonativo de los enunciados interrogativos directos pronominales con matiz de cortesía se asemeja al de los interrogativos directos de valor absoluto (Quilis, 1999: 431), nos permitió enunciar nuestra hipótesis de trabajo en los términos que siguen: los oyentes confundirán con mayor frecuencia, por interpretación auditiva, los enunciados interrogativos directos pronominales sin matiz de cortesía y los enunciados declarativos, que los interrogativos directos pronominales con dicho matiz y los declarativos, pues en español existe más parecido entre la curva entonativa de los enunciados declarativos y la de los interrogativos pronominales sin matiz de cortesía, que entre la de los declarativos y la de los interrogativos pronominales con tal matiz.
Además, y teniendo en cuenta el análisis contrastivo de configuraciones ofrecido en Barajas (2018: 3-4), pensamos que la relativa similitud entre los enunciados declarativos en español y en coreano por la dirección del movimiento del fundamental en sus junturas terminales, caracterizada por un descenso tonal en ambos casos, si bien puede coadyuvar a la correcta interpretación de esta clase de enunciados en español por oyentes hablantes nativos de coreano, constituirá con probabilidad un rasgo que contribuya a agudizar la confusión entre dichos enunciados declarativos y los interrogativos directos pronominales sin matiz de cortesía, ya que el discente coreano tenderá a percibir la curva entonativa de los enunciados interrogativos directos pronominales sin matiz de cortesía en español, semejante a la de los declarativos en español, como similar a la de los enunciados declarativos en coreano, dados los hábitos perceptivos inherentes al dominio de su lengua materna.
1.3. OTRAS CONSIDERACIONES TEÓRICAS
A propósito de las similitudes y diferencias entre los patrones entonativos de las clases de enunciados en las distintas lenguas, conviene recordar el carácter motivado de la entonación al que Cantero (1988: 113) alude explícitamente y en el que se fundamenta la apreciación de Cortés (2002a: 74) relativa a la gran utilidad de la competencia entonativa en una primera lengua (L1) o lengua materna cuando se trata de interpretar curvas melódicas del español como lengua extranjera (LE) o segunda lengua (L2). En una posición algo alejada de esta última opinión se halla la de Poch (1993: 198) cuando afirma que una de las competencias de más difícil adquisición por el aprendiente de una LE es la entonativa, la cual no entra en contradicción con el parecer de Cortés, al que llega después de realizar varios experimentos (1999; 2002c; 2002d), de que el aprendizaje de la entonación muestra más dificultades que el de la acentuación para el estudiante de ELE. En esta línea se situaba ya Navarro Tomás (1944: 8-9) cuando aseveraba que el pudor de desnudarse de los hábitos de la lengua extranjera (refiriéndose por ella a la lengua nativa del discente) encontraba en la entonación su más fuerte reducto, postura basada en la función expresiva de esta[1].
No podemos concluir este apartado sin recordar la relevancia de la entonación en el plano fónico en tanto que suprasegmento que influye de manera determinante en la estructura segmental del habla. En virtud de esto, resulta evidente que una adecuada enseñanza / aprendizaje de la entonación (y del suprasegmento de la acentuación) constituirá un elemento facilitador de la correcta pronunciación de los fonemas por los aprendices de ELE o de español como L2, como lo es para los niños en el proceso de adquisición de su lengua materna. Han defendido esta tesis, entre otros autores, Bowen y Stockwell (1960: 4), Vuletic y Cureau (1976: 88-89), Neuner et al. (1979: 14) y Lahoz (2007: 707-708).
2. MÉTODO
2.1. PARTICIPANTES[2]
Los colaboradores del autor en ambas pruebas de interpretación auditiva de enunciados fueron dos informantes (A y B), en un primer estadio, y dos grupos de oyentes, en una fase posterior. El primer grupo de oyentes (Avanzado 1) provino de cuatro grupos de alumnos matriculados en la asignatura de conversación en español de nivel avanzado (B2 del MCER y del PCIC), mientras que el segundo (Avanzado 2) lo hizo de tres grupos de dicha asignatura.
Las voces de los informantes A y B, mujer y hombre respectivamente, fueron grabadas para obtener el estímulo auditivo en dos ocasiones distintas: una cuando A contaba con 33 años de edad y B lo hacía con 37, y otra en la que sus edades eran de 38 años en el caso de A y de 42 en el de B. El estímulo grabado en la primera ocasión sirvió a nuestra investigación con Avanzado 1, mientras que el registrado en la segunda se utilizó con el test de Avanzado 2. Tanto el informante A como el B son hispanohablantes nativos de norma estándar en posesión de títulos de posgrado españoles, así como de nivel socioeconómico medio. La informante A pertenece a la variedad canaria aunque observamos que su habla había sido influida por la castellana de Madrid tras residir durante siete años en dicha región, al tiempo que el informante B habla la variedad castellana de Madrid.
En relación con los oyentes, la muestra estadística de Avanzado 1 estuvo integrada por 61: 49 mujeres (80,33 %) y 12 hombres (19,67 %)[3]. La de Avanzado 2, por 60: 41 mujeres (68,33%) y 19 varones (31,67%). De este modo, y atendiendo a las indicaciones orientadas a la consecución de una estadística inferencial solvente (Dörnyei, 2007: 99), el tamaño muestral supera en ambos casos el 1 % del universo, si consideramos que el dato más reciente disponible al respecto señala que el número de estudiantes universitarios de español en Corea del Sur (matriculados en clases de todos los niveles de competencia comunicativa) era de 3.379 en el año 2009 (Jiménez Segura y Cabrera, 2010: 25).
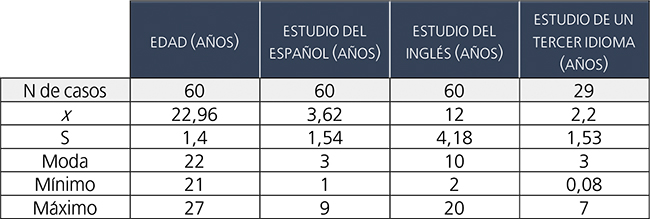
Como ya hicimos en su momento para Avanzado 1, la tabla 1 describe al grupo de oyentes de Avanzado 2 atendiendo a los parámetros de edad y años de estudio del español y otras lenguas extranjeras, mediante los estadísticos de número de casos (N), media aritmética (x), desviación estándar o promedio de variación con respecto a la media (S), moda, mínimo y máximo.
2.2. MEDIOS Y PROCEDIMIENTO
Los medios elaborados ad hoc para el experimento, tanto el llevado a cabo con Avanzado 1 como el realizado con Avanzado 2, consistieron en un documento impreso en papel con el fin de que los oyentes lo cumplimentaran, así como en dos estímulos auditivos (uno para Avanzado 1 y otro, distinto, para Avanzado 2) registrados en sendos archivos de audio.
El documento en papel, igual en Avanzado 1 y Avanzado 2, recogía, junto a las instrucciones para realizar el test y rellenarlo, un cuestionario bilingüe en español y coreano con ocho preguntas dirigidas a los oyentes sobre su sexo, edad y tiempo de estudio empleado en el aprendizaje del español, el inglés y una tercera lengua extranjera sin determinar. Los datos procurados mediante él por los oyentes sirvieron a la descripción estadística de los grupos llevada a término en 2.1. en ambos trabajos. Además, el impreso incluía una tabla en la que los oyentes debían consignar sus respuestas al estímulo sonoro, mostrando la clase de enunciado -declarativo, enfático o interrogativo directo- a la que interpretaban que pertenecía cada uno de los enunciados que escuchaban.
Por su parte, los estímulos auditivos consistieron en 24 enunciados (6 declarativos [.], 6 enfáticos [!], 6 interrogativos directos pronominales [?p] y 6 interrogativos directos de valor absoluto [?]), idénticos en su expresión escrita para Avanzado 1 y Avanzado 2, grabados en primer lugar por el informante A, y a continuación por el B en un orden distinto al del registro de A (V. 6. Apéndice). Así, el archivo de sonido de Avanzado 1, por un lado, y el de Avanzado 2, por otro, reunió los mismos 48 enunciados leídos en el mismo orden (24 leídos por A y otros 24 leídos por B) para ambos experimentos. Los enunciados interrogativos pronominales (?p) fueron materializados en el estímulo de Avanzado 1 como preguntas pronominales con matiz de cortesía, mientras que en el estímulo de Avanzado 2 lo fueron como preguntas pronominales sin dicho matiz (V. 1.1. Objetivos). Todos los enunciados fueron grabados con aproximadamente cinco segundos de silencio entre ellos, a una velocidad elocutiva propia de las interacciones conversacionales entre hablantes nativos y tratando de reproducir su naturalidad o espontaneidad.
Los 48 enunciados del estímulo auditivo guardaban correspondencia biunívoca con 48 filas presentes en la página de la tabla de respuestas; filas que se numeraron en orden correlativo del 1 al 48 de arriba a abajo y se dividieron en dos grandes columnas: una a la izquierda, con los números del 1 al 24, correspondientes a los enunciados leídos por el informante A, y otra a la derecha, con guarismos del 25 al 48 en representación de los enunciados leídos por el informante B. Ambas columnas comprendían tres subcolumnas con objeto de que los oyentes señalaran la clase de enunciado a la que creían que pertenecía el que acababan de escuchar en cada pregunta del test. Así, de izquierda a derecha, las tres casillas formadas para cada número (enunciado), se identificaban por las notaciones de (.), (!) y (?) respectivamente, simbolizando las tres clases de enunciados entre las que los oyentes debían discriminar auditivamente: declarativos, enfáticos e interrogativos directos, por este orden.
En ambas ocasiones (con Avanzado 1 y Avanzado 2), la grabación de los 48 enunciados se reprodujo dos veces consecutivamente, y los oyentes podían no marcar ninguna de las tres casillas de cada enunciado si creían no haber discriminado su clase con suficiente claridad.
Los oyentes respondieron al cuestionario sobre información personal y se sometieron a la prueba auditiva en las aulas asignadas a sus grupos durante una sesión de unos 25 minutos de duración en todos los casos.
3. RESULTADOS. INTERPRETACIÓN Y COMPARACIÓN
Con miras a su procesamiento, las respuestas de los oyentes de Avanzado 2 al cuestionario sobre información personal y a la prueba auditiva fueron registradas, tras codificarlas, en una hoja de cálculo de Excel. De ese modo, las contestaciones a la segunda se extendieron por un total de 2.880 celdillas (60 filas correspondientes al número de oyentes por 48 columnas dadas por el número de enunciados grabados en el archivo del estímulo sonoro). Del total de celdillas, tres (el 0,10%) quedaron en blanco debido a la ausencia de respuesta de un oyente en un enunciado y a la de otro en dos. En el caso de Avanzado 1, el hecho de que un oyente no contestara a uno de los enunciados condujo a que una celdilla (el 0,03%) quedara vacía (Barajas, 2018: 6).
3.1. INCIDENCIA DE ERRORES EN GENERAL
Atendiendo a las cifras de la tabla 2, en la que los porcentajes (%) de errores se calcularon sobre el total de ítem (2.880 para Avanzado 2 y 2.928 para Avanzado 1), advertimos que los oyentes de Avanzado 2 erraron en un 15,35% de las ocasiones mientras que los de Avanzado 1 lo hicieron en un 6,9%, con lo que los primeros fallaron un 8,45 % más que los segundos, cuyo porcentaje de errores resulta inferior a la mitad del de Avanzado 2. Podemos percibir que otro tanto sucede con la media de errores por oyente, donde la de Avanzado 2 supera el doble del valor numérico de la de Avanzado 1 (7,36 errores frente a 3,31), con una diferencia de 4,05 errores de una a otra. Por otro lado, los coeficientes de variación de Pearson (CV) manifiestan una muy considerable variabilidad en los números de errores de los distintos oyentes en ambos grupos, resultando algo mayor (un 6,74% superior) en Avanzado 1.
Si fijamos la atención en los mismos estadísticos, pero los aplicamos a los oyentes divididos en razón de su sexo, reparamos en que mientras en Avanzado 1 las mujeres cometieron relativamente más equivocaciones que los hombres, si bien solo un 2,11% más, en Avanzado 2 ocurrió al contrario, aunque también por un parvo 4,5% de diferencia. La media de errores por oyente aparece un 1,01% superior para las mujeres de Avanzado 1, al tiempo que, en Avanzado 2, la media de los varones excede a la de las féminas en un 2%. En cuanto a los coeficientes de variabilidad de Pearson (CV), estos indican que los hombres mostraron una mayor disparidad entre sí que las mujeres en la cantidad de yerros cometidos tanto en Avanzado 1 como en Avanzado 2, siendo las diferencias entre sexos del 15,74% y del 27,25% respectivamente.
Los histogramas recogidos en las figuras 1 y 2 hacen patente que la distribución de frecuencias de aciertos entre oyentes no era normal o gaussiana en ninguno de los dos grupos comparados en el estudio.
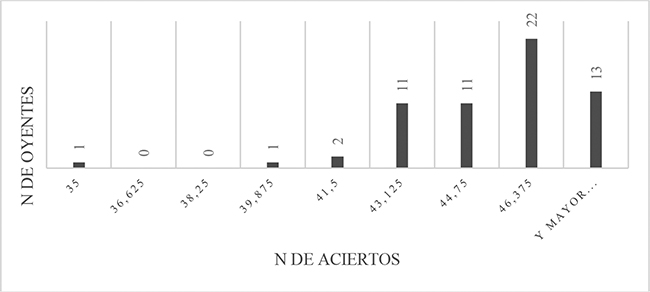
Figura 1
Distribución de frecuencias de aciertos entre los oyentes de Avanzado 1.
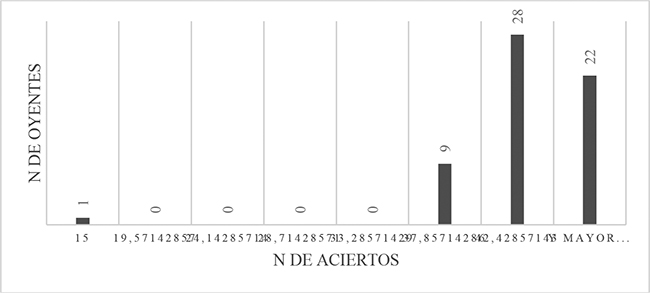
Figura 2
Distribución de frecuencias de aciertos entre los oyentes de Avanzado 2.
3.2. INCIDENCIA DE ERRORES POR CLASES DE ENUNCIADOS
Abordamos a continuación el análisis comparativo de errores que involucra a ambos grupos de oyentes, considerando la cantidad de yerros cometidos por ellos en cada una de las cuatro clases de enunciados presentes en el estímulo auditivo de nuestro estudio: declarativos (.), enfáticos (!), interrogativos pronominales (?p) e interrogativos absolutos (?). Para ello, la tabla 3 expone la cantidad de aciertos, errores y respuestas en blanco registradas en la interpretación de enunciados adscritos a cada una de las clases mencionadas, tanto en términos absolutos (N. registrado) como relativos (%). Los porcentajes fueron calculados sobre el número total de ítem pertenecientes a cada clase de enunciados (61 oyentes x 12 enunciados de cada clase = 732 en el caso de Avanzado 1, y 60 oyentes x 12 enunciados de cada clase = 720, en el caso de Avanzado 2). Asimismo, en la tabla 4 ofrecemos las cifras absolutas y relativas de errores acaecidos en la interpretación de los enunciados incluidos en cada una de tales clases, con cantidades porcentuales computadas sobre el número total de errores cometidos por cada grupo de oyentes (202 en Avanzado 1 y 442 en Avanzado 2). En aras de una mayor claridad expositiva, brindamos la información de las tablas 3 y 4 (solo la relativa a las cifras de errores en el caso de la primera) en las figuras 3 y 4 respectivamente, usando gráficos de barras agrupadas.
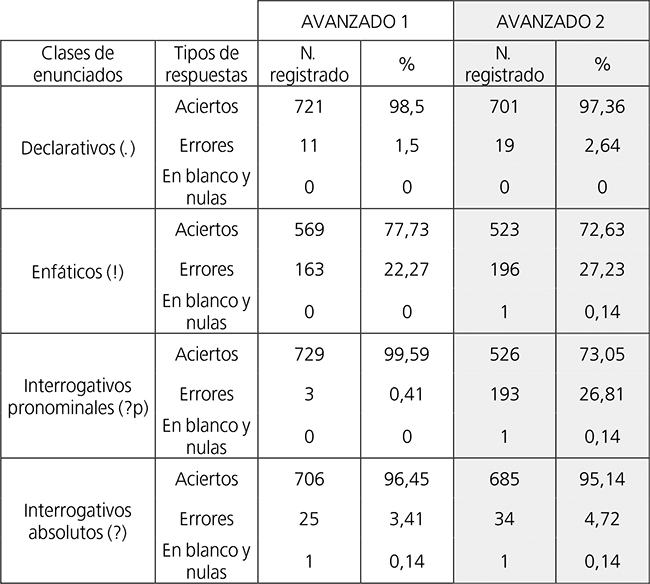
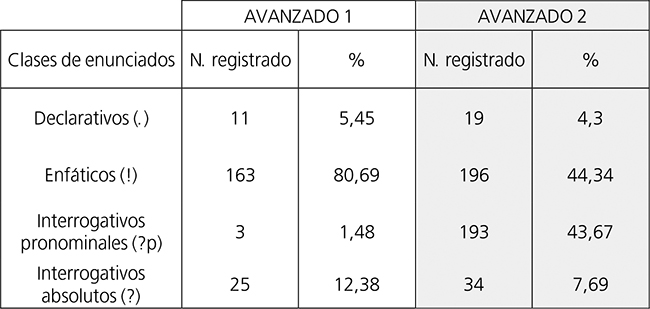
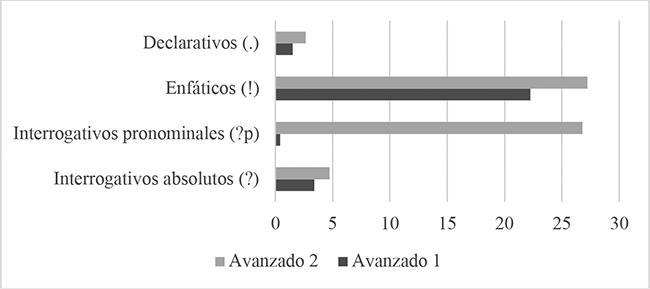
Figura 3
Distribución de frecuencias relativas de errores entre clases de enunciados calculadas sobre el total de errores.
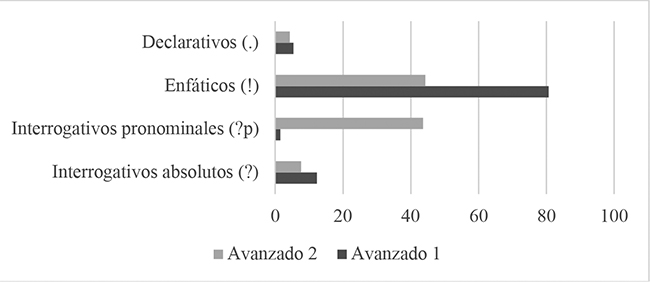
Figura 4
Distribución de frecuencias relativas de errores entre clases de enunciados, calculadas sobre el total de errores.
A la luz de los datos, advertimos que las escalas de clases de enunciados en razón de la cantidad relativa de errores registrados en cada clase difieren de un grupo a otro. Así, y procediendo de mayor a menor porcentaje de errores, el orden correspondiente a Avanzado 1 se muestra: 1º Enunciados enfáticos (!), 2º Interrogativos absolutos (?), 3º Declarativos (.) y 4º Interrogativos pronominales (?p). Paralelamente, la disposición hallada en Avanzado 2 aparece como sigue: 1º Enfáticos (!), 2º Interrogativos pronominales (?p), 3º Interrogativos absolutos (?) y 4º Declarativos (.). Queda de manifiesto, por tanto, que los enunciados enfáticos (!) ocupan el primer lugar en ambos grupos mientras que el resto de clases de enunciados se emplaza en posiciones distintas de un grupo al otro. En concreto, los interrogativos pronominales (?p) pasan del cuarto y último lugar al segundo de Avanzado 1 a Avanzado 2, a la vez que los interrogativos absolutos (?) se desplazan del segundo al tercer puesto y los declarativos (.) lo hacen del tercero al cuarto, en el mismo sentido. No obstante, hemos de señalar que la diferencia porcentual entre la cantidad de errores producidos en enunciados enfáticos (!) e interrogativos pronominales (?p) para Avanzado 2 resulta muy reducida (del 0,42% sobre el total de ítem de cada clase de enunciado y del 0,67% sobre el total de errores cometidos).
Si confrontamos los números relativos de errores propios de las diferentes clases de enunciados calculados sobre su total de ítem entre ambos grupos de oyentes, notamos que, de Avanzado 1 a Avanzado 2, los fallos en enunciados interrogativos pronominales (?p) aumentan de frecuencia en un 26,4%, así como que las equivocaciones en enunciados enfáticos (!) hacen lo propio en un 4,96%, al tiempo que los yerros en interrogativos absolutos (?) experimentan una subida del 1,31% y los vinculados a los declarativos (.), otra del 1,14%.
Una prueba Chi cuadrado de 2 x 4, x2 (2, 644) = 117,617, p = 0, indicó que las diferencias existentes en las frecuencias absolutas de errores (N. registrado) en cada una de las cuatro clases de enunciados entre ambos grupos de oyentes eran significativas en términos de inferencia estadística.
3.3. INCIDENCIA DE ERRORES EN FUNCIÓN DE SUS TIPOS
En un paso ulterior del análisis, y como demuestran las cifras absolutas y relativas de la tabla 5 y las figuras 5 y 6, nos fue dado indagar acerca de la distribución de las frecuencias de errores en función de la naturaleza o tipo de estos en los dos grupos estudiados. Por ello, adoptamos como categorías analíticas las posibilidades interpretativas erróneas inherentes a cada clase de enunciado del estímulo: para los enunciados declarativos (.), la de enunciado declarativo tomado por (o interpretado como) enfático [(.) por (!)] y la de enunciado declarativo tomado por interrogativo directo [(.) por (?)]; en el caso de los enfáticos (!), la de enfático interpretado como declarativo [(!) por (.)] así como la de enfático interpretado como interrogativo directo [(!) por (?)]; atendiendo a los interrogativos directos pronominales (?p), la de interrogativo directo pronominal percibido como declarativo [(?p) por (.)] junto a la de interrogativo directo pronominal percibido como enfático [(?p) por (!)]; y en relación con los interrogativos directos absolutos (?), las de interrogativo directo absoluto confundido con declarativo [(?) por (.)] e interrogativo directo absoluto confundido con enfático [(?) por (!)].
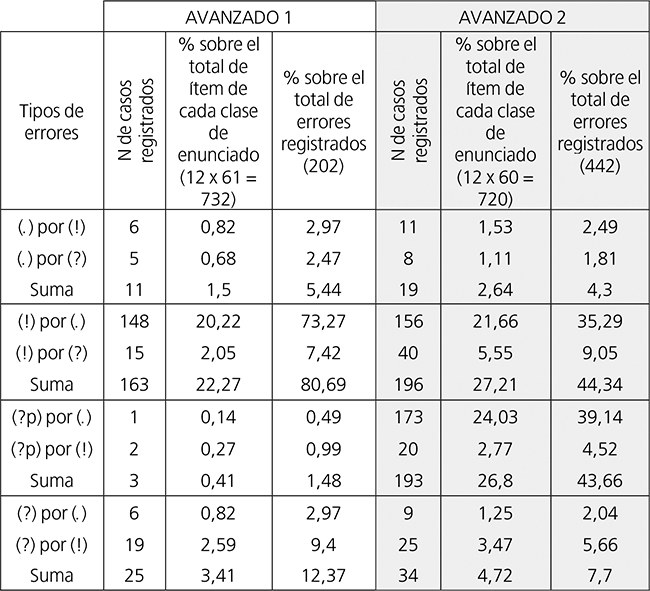
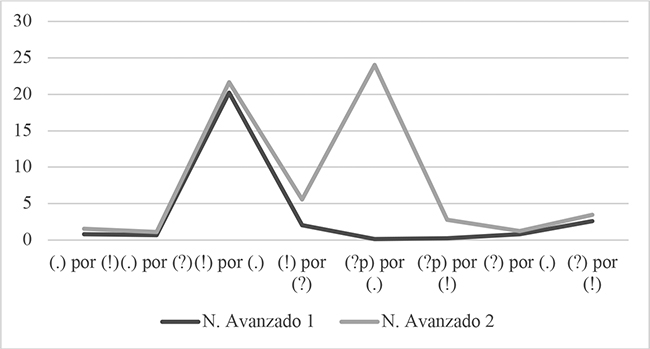
Figura 5
Comparación % de errores de cada tipo entre Avanzado 1 y Avanzado 2 sobre el total de ítem de las diferentes clases de enunciados.
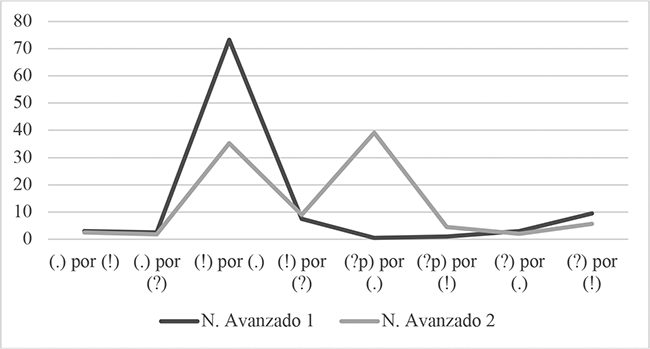
Figura 6
Comparación % de errores de cada tipo entre Avanzado 1 y Avanzado 2 sobre el total de errores.
Tomando como referencia las cantidades relativas de errores calculadas sobre el número total de ítem de cada clase de enunciado presentes en la tabla y la figura 5, notamos que, para Avanzado 2 -otro tanto, entre varias cuestiones, hicimos con Avanzado 1 en Barajas (2018: 10-14)- el tipo de error más frecuente no es otro que el de [(?p) por (.)], el cual se produjo en casi una cuarta parte de los ítem correspondientes a los enunciados interrogativos pronominales (?p) y se presenta un 2,37% más frecuente que el segundo en la escala de mayor a menor grado de incidencia, el de [(!) por (.)]. Del mismo modo, aparece claro que la diferencia relativa de este tipo de error con el tercero, [(!) por (?)], acaecido con una frecuencia casi cuatro veces inferior a la del segundo, es la más dilatada de la escala, de un 16,11%. El resto de frecuencias de tipos de error se encuentra comprendido en un rango del 3,47% al 1,11%, conformando diferencias porcentuales de 2,08 puntos entre el tercer y el cuarto tipo de la escala, de 0,7 puntos entre el cuarto y el quinto, de 1,24 entre el quinto y el sexto, de 0,28 entre el sexto y el séptimo, como también de 0,14 puntos entre el séptimo y el octavo. La tabla 6 muestra de manera esquemática el tipo de error situado en cada uno de los puestos que integran su escala de frecuencias.
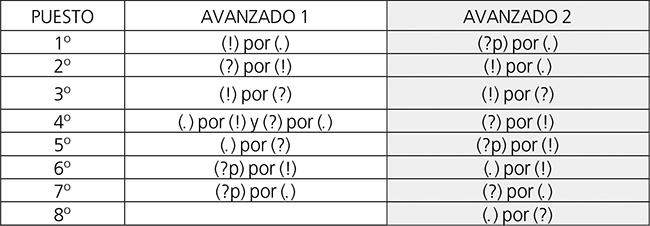
La tabla y figura 5 junto a la tabla 6 nos sirvieron asimismo a efectos de comparación de las escalas de tipos de errores y las frecuencias asociadas a cada uno de ellos entre grupos (a este efecto tomamos como referencia una vez más las tasas calculadas cobre el total de ítem de la clase de enunciado pertinente al caso). De este modo conocimos que todos los tipos de error concitaron una mayor frecuencia en Avanzado 2 que en Avanzado 1, como también que los dos vinculados a los enunciados interrogativos pronominales (?p) -[(?p) por (.)] y [(?p) por (!)]- ocuparon puestos más altos en la escala de frecuencias por grado descendente de Avanzado 2 que en la de Avanzado 1. El error de [(?p) por (.)] pasó del séptimo y último lugar en el grupo 1 al primero en el grupo 2, con un alza del 23,89% en la frecuencia de uno a otro, la mayor subida en la frecuencia de tipos de error en el presente estudio. El tipo de [(?p) por (!)], por su parte, ascendió del sexto puesto en Avanzado 1 al quinto en Avanzado 2, asociado a una diferencia porcentual del 2,5 %. Asimismo, supimos que el tipo de yerro [(!) por (?)] se mantuvo en el tercer grado de la escala, con un aumento en su incidencia del 3,5%. Percibimos también que el resto de tipos de errores descendió de lugar en la escala relativa de frecuencias de Avanzado 1 a Avanzado 2: [(!) por (.)] del primero al segundo, [(?) por (!)] del segundo al cuarto, [(.) por (!)] del cuarto al sexto, [(?) por (.)] del cuarto al séptimo, y [(.) por (?)] del quinto al octavo, en concurrencia con los saltos porcentuales más reducidos de un grupo a otro: 1,44%, 0,88%, 0,71% y 0,43% (idéntico para los dos últimos tipos de error), respectivamente.
Gracias a la inferencia estadística no paramétrica, comprobamos que las diferencias observadas en las frecuencias absolutas de tipos de errores (N. de casos registrados) entre Avanzado 1 y Avanzado 2 eran significativas, pues una prueba Chi cuadrado de 2 x 8, x2 (2, 644) = 128,281, p = 0, nos permitió constatarlo.
Una perspectiva más general en nuestro estudio fue la que consistió en considerar únicamente las tres grandes clases de enunciados entre las que los oyentes debían discriminar en la prueba auditiva ‑declarativos (.), enfáticos (!) e interrogativos directos (?)- a fin de adoptar como categorías analíticas los tres tipos de confusiones posibles entre ellas.
Así, en la tabla 7 comparamos las frecuencias relativas de dichos tipos de confusiones para los dos grupos de oyentes, con porcentajes calculados sobre el total de ítem de las clases de enunciados implicadas en cada tipo.

Reparamos así en que los porcentajes de confusiones, bastante exiguos en todos los tipos para ambos niveles, perfilan gradaciones descendentes por cantidad de casos distintas entre Avanzado 1 y Avanzado 2. Si bien el tipo de confusión entre (.) y (!) coincide en la primera posición de la escala para los dos grupos, mostrándose un 1,07% más frecuente en Avanzado 2, los otros dos tipos de confusiones intercambian sus puestos de Avanzado 1 a Avanzado 2: el que se produjo entre (!) y (?) fue el segundo más frecuente en Avanzado 1 pero el tercero en Avanzado 2, aunque para este último grupo la frecuencia registrada de dicho tipo de confusión resultó un 2,29 % superior, a la vez que con el acaecido entre (.) y (?) ocurre a la inversa, diferenciándose aquí las frecuencias entre grupos por un 8,24% más en Avanzado 2.
Las diferencias en las frecuencias absolutas de estos tres tipos de confusiones entre Avanzado 1 y Avanzado 2 se revelaron estadísticamente significativas a la luz de una prueba Chi cuadrado de 2 x 3, x2 (2, 644) = 101,937, p = 0.
Derivado del anterior, implementamos otro enfoque de análisis fruto de examinar las frecuencias de los seis tipos de error susceptibles de ser categorizados con las tres grandes clases de enunciados ‑declarativos (.), enfáticos (!) e interrogativos directos (?)- y de comparar dichas frecuencias por pares de tipos de error de naturaleza contraria u opuesta entre sí. La información relevante a este respecto se haya expresada en la tabla 8, con porcentajes calculados sobre el total de ítem de las clases de enunciado intervinientes en el tipo de error de que se tratase en cada caso.
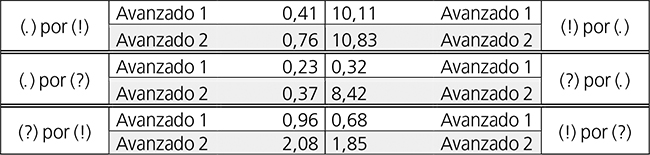
De este modo pudimos aprehender que los tipos de error consistentes en interpretar los enunciados enfáticos (!) como declarativos (.), los interrogativos directos (?) como declarativos (.), y los interrogativos directos (?) como enfáticos (!) se produjeron con mayor frecuencia que sus contrarios tanto en Avanzado 1 como en Avanzado 2 (si bien lo reducido de algunas cifras invita a la cautela en la afirmación), con diferencias porcentuales respectivas de 9,7, de 0,09 y de 0,28 puntos correspondientes al primer grupo, así como con la de 10,07, la de 8,05 y la de 0,23 en relación con el segundo. Asimismo, los cálculos evidencian aumentos en la mencionada prevalencia de los tipos de error [(!) por (.)] y [(?) por (.)] sobre sus opuestos del 0,37% y del 7,96% respectivamente de Avanzado 1 a Avanzado 2 (si bien debe repararse en lo nimio de la primera cantidad). La prevalencia del tipo [(?) por (!)] sobre [(!) por (?)], en cambio, disminuye del primer grupo al segundo, aunque solo el 0,05%.
La estadística inferencial no paramétrica indicó una vez más la significancia de las diferencias observadas entre Avanzado 1 y Avanzado 2, en esta oportunidad para las magnitudes absolutas de los seis grandes tipos de error considerados: Chi cuadrado de 2 x 6, x2 (2, 644) = 110,392, p = 0.
3.4. INCIDENCIA DE ERRORES EN FUNCIÓN DE SUS TIPOS Y EL SEXO DE LOS OYENTES
Un último punto de vista en el análisis de errores nos permitió examinar las frecuencias de los ocho tipos de equivocaciones ya empleados en una fase anterior de este estudio, tanto en cifras absolutas como relativas, cometidos por las mujeres (M) y por los varones (V) por separado, con objeto de establecer comparaciones entre sexos. A este propósito sirvió la información contenida en la tabla 9, con porcentajes calculados sobre el total de ítem de la clase de enunciado pertinente en cada tipo de error para el caso de las mujeres por un lado y para el de los hombres por otro. Vinculadas a ella, las figuras 7, 8 y 9 expresan gráficamente comparaciones efectuadas entre sexos en Avanzado 2, y otras llevadas a cabo para un mismo sexo cada vez entre Avanzado 1 y Avanzado 2. Las cantidades absolutas de Avanzado 1 (N de casos) pueden consultarse en Barajas (2018: 15).
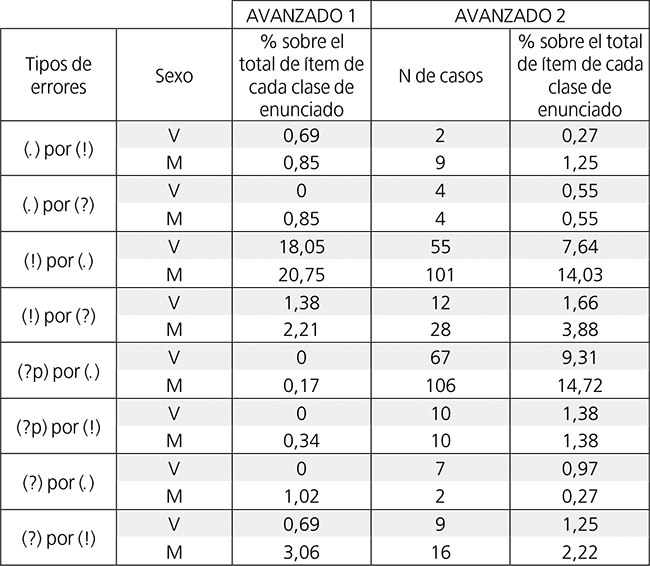
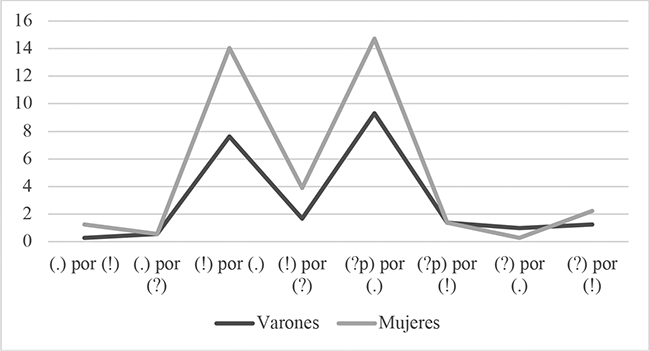
Figura 7
Comparación entre sexos de la distribución de frecuencias de tipos de errores en Avanzado 2 (% sobre el total de ítem de cada clase de enunciado).
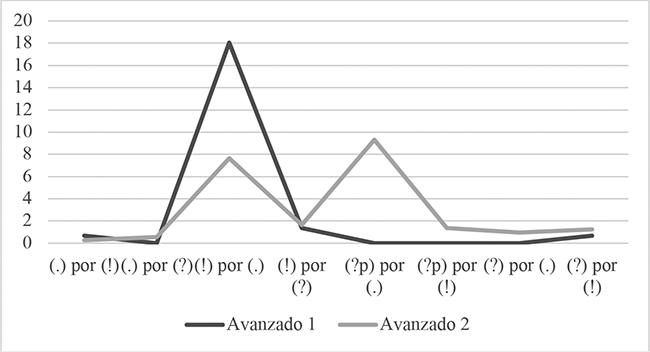
Figura 8
Comparación entre Avanzado 1 y Avanzado 2 de las frecuencias de tipos de errores en los varones (V) (% sobre el total de ítem de cada clase de enunciado).
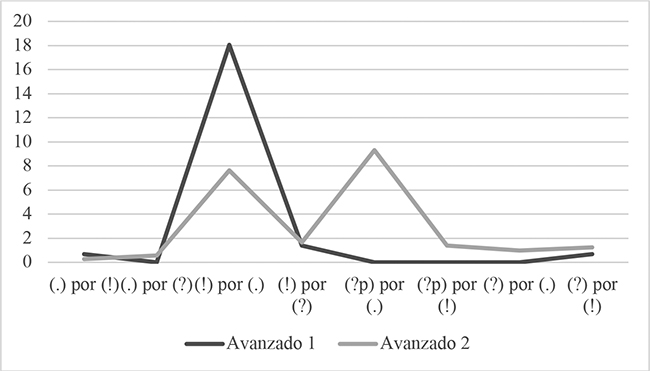
Figura 9
Comparación entre Avanzado 1 y Avanzado 2 de las frecuencias de tipos de errores en las mujeres (M) (% sobre el total de ítem de cada clase de enunciado).
El observar la tabla 9 y la figura 7 pone de manifiesto que las diferencias porcentuales en la frecuencia de tipos de errores entre sexos se extienden en un rango definido entre los 6,39 y los 0 puntos, siendo las mayores diferencias las registradas en el tipo [(!) por (.)], cuya cuantía es la ya referida de 6,39 puntos, y en el tipo [(?p) por (.)], de 5,41 puntos. El valor mínimo, de 0 puntos, se produjo en dos tipos de yerros: [(.) por (?)] y [(?p) por (!)]. Resulta ostensible, aunque siempre teniendo en cuenta la escasa entidad de los porcentajes en general, que en los tipos de error donde aparecieron diferencias relativas de frecuencia entre sexos, fueron las mujeres quienes registraron magnitudes superiores, a excepción del caso de [(?) por (.)], donde los hombres incurrieron en errores interpretativos un 0,7% más que las féminas.
En relación con lo anterior, y como evidencia la tabla 10, los puestos ocupados por los diferentes tipos de error (en una gradación descendente cuyo criterio era la frecuencia relativa sobre el número total de ítem de cada clase de enunciado) se mostraron idénticos en la mitad de los casos al comparar los resultados de ambos sexos entre sí para Avanzado 2; difirieron en el cuarto lugar, en el que se situó el tipo [(?p) por (!)] para los hombres y el [(?) por (!)] para las mujeres; en el quinto, con [(?) por (!)] en el caso de los primeros y [(?p) por (!)] en el de las segundas; en el sexto, ocupado por [(?) por (.)] y [(.) por (!)] respectivamente; y en el octavo, donde se emplaza el tipo [(.) por (!)] bajo el rubro de ellos pero el de [(?) por (.)] bajo el de ellas.
No nos fue posible comprobar si las diferencias en las frecuencias absolutas de tipos de errores entre mujeres y hombres en Avanzado 2 eran estadísticamente significativas, pues la prueba de Chi cuadrado no resultaba adecuada en este caso debido a que al menos el 20 % de las frecuencias esperadas eran menores de 5. Como vía alternativa, decidimos practicar una prueba Chi cuadrado para constatar la significancia de las diferencias entre las frecuencias absolutas de aciertos en las cuatro clases de enunciados del estímulo -declarativos (.), enfáticos (!), interrogativos directos pronominales (?p) e interrogativos directos absolutos (?)-, la cual reveló que no podía afirmarse con seguridad que existiese relación entre estas y el sexo de los oyentes en Avanzado 2: Chi cuadrado de 2 x 4, x2 (2, 2.435) = 1,31, p = 0,726.
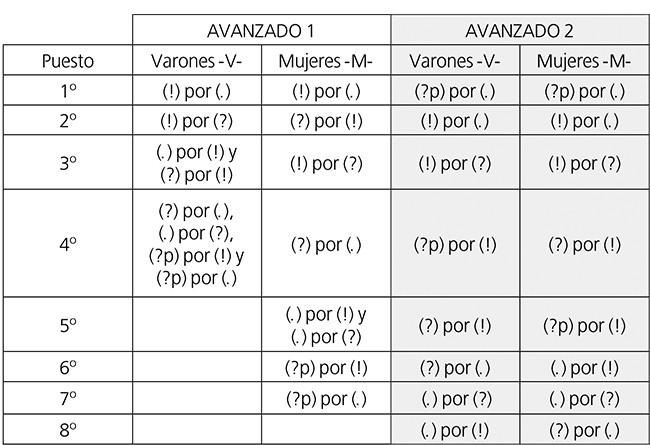
La tabla 10, como también la tabla 9 y las figuras 8 y 9, nos llevaron a advertir que en todos los casos excepto en uno los tipos de error no ocuparon el mismo puesto por frecuencia relativa en la escala descendente en Avanzado 1 y Avanzado 2, tanto para las mujeres como para los varones. Así, la única coincidencia se dio con el tipo [(!) por (?)] en el tercer lugar para las mujeres y con el de [(?p) por (!)] en el cuarto para los hombres. Notamos también que los varones cometieron más errores en términos relativos para Avanzado 2 en todos los tipos de error a excepción de en los contrarios [(.) por (!)] y [(!) por (.)], donde incurrieron en menos. Las mujeres, por su parte, aumentaron su frecuencia relativa de errores de Avanzado 1 a Avanzado 2 en la mitad de los tipos de error, registrándose descensos en los tipos de [(.) por (?)], [(!) por (.)], [(?) por (.)] y [(?) por (!)]. Las diferencias porcentuales en la frecuencia de cada tipo de error de Avanzado 1 a Avanzado 2 se encontraban comprendidas en un rango de 10,41 a 0,28 puntos para los hombres, al tiempo que de 14,55 a 0,3 puntos para las mujeres (apréciese en la tabla 9 y en las figuras 7, 8 y 9 la escasa entidad de las variaciones para la mayoría de los tipos de error intra e inter sexos).
Resultó impracticable el demostrar la significancia estadística de las diferencias observadas en la frecuencia de los diferentes tipos de error entre Avanzado 1 y Avanzado 2 para cada sexo, dado que en el caso de las chicas al menos el 20 % de las frecuencias esperadas era menor de 5, y en el de los chicos como mínimo una frecuencia esperada era inferior a 1. No ocurrió igual con las diferencias registradas entre Avanzado 1 y Avanzado 2 en la frecuencia absoluta de aciertos para las cuatro clases de enunciados del estímulo auditivo -declarativos (.), enfáticos (!), interrogativos directos pronominales (?p) e interrogativos directos absolutos (?)-, ya que una prueba Chi cuadrado de 2 x 4, x2 (2, 3.868) = 11,297, p = 0,0102, demostró su significancia estadística en el caso de las mujeres. No podemos decir otro tanto con seguridad en el de los varones, puesto que una prueba Chi cuadrado de 2 x 4, x2 (2, 1.292) = 7,199, p = 0,0658 mostró que, como el valor de probabilidad indicaba, el riesgo de concluir que existía una asociación entre las variables consideradas era aquí superior al 6 %.
4. CONCLUSIONES
El anterior análisis de los datos obtenidos tras la aplicación de la prueba auditiva a ambos grupos de oyentes (Avanzado 1 y Avanzado 2) del nivel de competencia comunicativa en español considerado (B2 del MCER y del PCIC) para su interpretación comparativa, nos permite sostener, en primer lugar, que los aprendientes sometidos al estímulo auditivo provisto de enunciados interrogativos directos pronominales con matiz de cortesía (Avanzado 1) incurrieron en algo menos de la mitad de errores que los expuestos al estímulo con enunciados interrogativos directos pronominales sin dicho matiz (Avanzado 2) en términos porcentuales calculados sobre el total de ítem, así como que existió una disparidad algo mayor entre oyentes en el número de errores cometidos para el caso de aquellos (Avanzado 1) que para el de estos (Avanzado 2) (V. 3.1. Incidencia de errores en general).
Asimismo, afirmamos que, si bien los oyentes que escucharon el estímulo con enunciados interrogativos directos sin matiz de cortesía (Avanzado 2) cometieron más errores en términos relativos sobre el total de ítem en las cuatro clases de enunciados -declarativos (.), enfáticos (!), interrogativos directos pronominales (?p) e interrogativos directos absolutos (?)- que los que escucharon el estímulo con enunciados interrogativos directos pronominales que poseían tal matiz (Avanzado 1), es la clase de los interrogativos directos pronominales (?p) la que captó por mucho una mayor variación porcentual de un grupo a otro (de 26,4 puntos con cifras calculadas sobre el total de ítem de la clase de enunciado), pasando de ser la última a la segunda por frecuencia relativa de equivocaciones de Avanzado 1 a Avanzado 2 (V. 3.2. Incidencia de errores por clases de enunciados).
Nuestra hipótesis de trabajo queda verificada (V. 1.2. Hipótesis de trabajo) al constatar el hecho de que el aumento en la frecuencia relativa de errores adscritos a los enunciados interrogativos directos pronominales (?p) de Avanzado 1 a Avanzado 2 se debió sobre todo al incremento de fallos consistentes en interpretar tal clase de enunciados como declarativos [(?p) por (.)], con una diferencia de 23,89 puntos entre ambos grupos, y, en bastante menor medida, al de los equívocos cuya naturaleza radica en interpretar los interrogativos directos pronominales (?p) como enfáticos (!) [(?p) por (!)], como evidencia su exiguo salto del 2,5 % de un grupo al otro (V. 3.3. Incidencia de errores en función de sus tipos). La repercusión de estas variaciones en las escalas de tipos de errores por grado de incidencia descendente se aprecia en que el tipo de [(?p) por (.)] pasó de ocupar el séptimo y último puesto en Avanzado 1 a situarse en el primero en Avanzado 2, a la vez que el de [(?p) por (!)] cambió del sexto lugar en Avanzado 1, cuando los interrogativos directos pronominales poseían matiz de cortesía en su entonación, al quinto en Avanzado 2, grupo para el que el estímulo auditivo presentaba los enunciados interrogativos directos pronominales privados de tal matiz.
Paralelamente, el primer tipo de error en la escala de Avanzado 1, el de [(!) por (.)], desciende al segundo lugar en la de Avanzado 2, aunque con un aumento de aquella a esta del 1,44% en su frecuencia calculada sobre el número total de ítem de la clase de los enunciados enfáticos (!). La prevalencia de dicho tipo de error, [(!) por (.)], en ambos grupos, observada también en nuestro estudio homólogo a este realizado con oyentes cuya competencia comunicativa en español era de nivel básico -A1 del MCER y del PCIC- (Barajas, 2019), puede explicarse por interferencia negativa al resultar coherente con la predicción cumplida que efectuamos entonces acerca del grado de incidencia de este tipo de error derivada del análisis contrastivo, dada la presencia de un descenso muy acusado del fundamental en las junturas terminales tanto de los enunciados enfáticos (!) en español presentes en el estímulo auditivo, como de los enunciados declarativos (.) en coreano (Barajas, 2018: 3-4).
Desde un punto de vista más general, y en relación con lo apuntado en el párrafo anterior, constatamos que las confusiones entre enunciados declarativos (.) y enfáticos (!) (las más frecuentes en Avanzado 1), continúan ocupando el primer lugar en la escala descendente por frecuencia relativa calculada sobre el total de ítem de los tipos de enunciados implicados en cada caso (de Avanzado 2). Esto es, las confusiones acaecidas entre (.) y (!) resultaron las más abundantes en términos relativos con independencia de que los enunciados interrogativos directos pronominales (?p) del estímulo auditivo contasen o no con matiz de cortesía, si bien en el segundo caso (el de Avanzado 2), dicho tipo se produjo el 1,07 % más que en el primero (el de Avanzado 1).
Al mismo tiempo, apreciamos que el tipo de confusión que implica a los enunciados declarativos (.) y a los interrogativos directos (?) asciende del tercer y último puesto al segundo en la mencionada escala de Avanzado 1 a Avanzado 2, mediante una diferencia de 8,24 puntos, la más dilatada de un nivel al otro entre los tres tipos de confusiones según impliquen estas a enunciados declarativos (.) y enfáticos (!), a declarativos (.) e interrogativos directos (?) o a enfáticos (!) e interrogativos directos (?).
De manera coherente con las observaciones que nos han permitido verificar nuestras hipótesis de trabajo (tanto la actual como la sostenida en Barajas, 2018), advertimos que el tipo de error de [(?) por (.)], si bien superior en frecuencia relativa a su opuesto, [(.) por (?)], en ambas condiciones (Avanzado 1 y Avanzado 2), lo es por 7,96 puntos porcentuales más en Avanzado 2 que en Avanzado 1, a la vez que el tipo de error de [(!) por (.)] se produjo en términos relativos más que su contrario, [(.) por (!)], también en los dos grupos, Avanzado 1 y Avanzado 2, pero con solo un 0,37 % más de frecuencia en el segundo que en el primero.
5. BIBLIOGRAFÍA
Barajas, D. (2019): “Interpretación auditiva de enunciados interrogativos directos pronominales con y sin matiz de cortesía por estudiantes coreanos en clases de nivel básico: un estudio comparativo”, marcoELE, Revista de didáctica ELE [en línea], enero-junio, 28 [3-5-2019]. ISSN 1885-2211, pp. 1-19. Disponible en web: https://marcoele.com/interpretacion-auditiva-de-enunciados-interrogativos-directos-pronominales/
Barajas, D. (2018): “Interpretación auditiva de enunciados declarativos, enfáticos e interrogativos directos por estudiantes coreanos en clases de nivel avanzado”, marcoELE, Revista de didáctica ELE [en línea], enero-junio, 26 [20-3-2018]. ISSN 1885-2211, pp. 1-21. Disponible en web: https://marcoele.com/interpretacion-auditiva-coreanos-avanzados/
Blecua, J.M. (coord.) et al. (2011), Nueva gramática de la lengua española. Fonética y fonología, Barcelona: Espasa.
Bowen, J.D. & Stockwell, R.P. (1960), Patters of Spanish Pronunciation: A drill book, Chicago: The University of Chicago Press.
Cantero, F.J. (1988), “Un ensayo de cuantificación de las entonaciones lingüísticas”, Estudios de Fonética Experimental, III: 112-134.
Cortés, M. (1998), “Percepción y adquisición de la entonación española por parte de hablantes nativos de chino”, Estudios de Fonética Experimental, IX: 67-134.
Cortés, M. (1999), Adquisición de la entonación española por parte de hablantes nativos de chino (tesis doctoral), Universitat de Barcelona, Facultad de Pedagogía, Departamento de Didáctica de la Lengua y la Literatura.
Cortés, M. (2002a), “Didáctica de la entonación: una asignatura pendiente”, Didáctica (Lengua y Literatura), volumen 14: 65-75.
Cortés, M. (2002b), Didáctica de la prosodia del español: la acentuación y la entonación. Madrid, Edinumen.
Cortés, M. (2002c), “Percepción y adquisición de la acentuación española en la lectura: el caso de los estudiantes taiwaneses, Estudios de Fonética Experimental, XII: 61-89.
Cortés, M. (2002d), “Producción y adquisición de la acentuación española en habla espontánea: el caso de los estudiantes taiwaneses”, Estudios de Fonética Experimental, XII: 91-103.
Dörnyei, Z. (2007), Research Methods in Applied Linguistics, Oxford: Oxford University Press.
Gil, J. (2007), Fonética para profesores de español: de la teoría a la práctica, Madrid: Arco/Libros.
Jiménez Segura, J. & Cabrera, J. (2010), El español en Corea del Sur, Centro de Investigación y Documentación del Instituto Cervantes (CIDIC).
Lahoz, J.M. (2007), “La enseñanza de la entonación en el aula de ELE: cómo, cuándo y por qué”, en Balmaseda, E. (ed.), Las destrezas orales en la enseñanza del español L2-LE: XVII Congreso Internacional de la Asociación del Español como Lengua Extranjera (ASELE): 27-30 de septiembre de 2006. Vol. 2, pp. 705-720. Logroño: Asociación para la Enseñanza del Español como Lengua Extranjera (ASELE), Servicio de Publicaciones de la Universidad de La Rioja.
Navarro Tomás, T. (1944), Manual de entonación española, Nueva York: Hispanic Institute.
Neuner, G. et al. (1979), Deutsch aktiv (nivel 1, libro del profesor), Berlín: Langenscheidt.
Poch, D. (1993) “La corrección fonética en español lengua extranjera”, en Miquel, L. y N. Sans (coords.), Didáctica del español como lengua extranjera, Expolingua 1993. Madrid: Fundación Actilibre. Reedición disponible en Monográficos marcoELE, 8 (2009): https://marcoele.com/monograficos/expolingua_1993
Preacher, K.J. (2001). Calculation for the chi-square test: An interactive calculation tool for chi-square tests of goodness of fit and independence [computer software]. Disponible en
Quilis, A. (1999), Tratado de fonología y fonética españolas, Madrid: Gredos
Vuletic, B. & Cureau, J. (1976), Enseignement de la prononciation: le système verbo-tonal: S.G.A.V.; suivi d’un précis de correction phonétique des francophones apprenant l’anglais, París: Didier
APÉNDICE
PRIMERA LISTA DE ENUNCIADOS: INFORMANTE A
1. Ya ha terminado de comer.
2. ¡Y yo qué sé cuándo vendrá!
3. ¿Dónde trabaja?
4. ¿Ya ha vuelto a Taiwán?
5. ¡Que ha ido a correr!
6. ¿Se ha engordado diez kilos?
7. Ya ha vuelto a Taiwán.
8. ¿Ha ido a correr?
9. ¡Que todavía no ha llegado!
10. Está muy cansado.
11. ¿Ellos dónde viven?
12. ¿Verdad que se ha casado?
13. ¿Ya ha terminado de comer?
14. ¡Es que está muy cansado!
15. ¿Por qué está cansado?
16. No ha llegado todavía.
17. ¿Cuándo vendrá él?
18. ¿No ha llegado todavía?
19. Te puedo ayudar mañana.
20. Yo sé dónde trabaja.
21. ¿Cuántos niños tiene?
22. ¡Se ha engordado 10 kilos!
23. ¿Quién puede ayudarme mañana?
24. ¡Ya ha terminado de comer!
SEGUNDA LISTA DE ENUNCIADOS: INFORMANTE B
25. ¿Ellos dónde viven?
26. Está muy cansado.
27. ¿Dónde trabaja?
28. ¿Se ha engordado 10 kilos?
29. ¡Es que está muy cansado!
30. ¿Ya ha vuelto a Taiwán?
31. Yo sé dónde trabaja.
32. ¿Ha ido a correr?
33. Ya ha terminado de comer.
34. ¡Que todavía no ha llegado!
35. ¿Cuántos niños tiene?
36. ¡Ya ha terminado de comer!
37. ¿Verdad que se ha casado?
38. ¿Por qué está cansado?
39. Ya ha vuelto a Taiwán.
40. ¿Cuándo vendrá él?
41. Te puedo ayudar mañana.
42. No ha llegado todavía.
43. ¿Ya ha terminado de comer?
44. ¡Y yo qué sé cuándo vendrá!
45. ¿No ha llegado todavía?
46. ¡Que ha ido a correr!
47. ¿Quién puede ayudarme mañana?
48. ¡Se ha engordado 10 kilos!
Notas
Información adicional
BIODATA: Daniel Barajas de Santiago es magíster en Enseñanza del español como segunda lengua por la Universidad Nacional de Educación a Distancia (UNED) y profesor asistente del Departamento de Español de la Hankuk University of Foreign Studies (HUFS). Sus artículos académicos tratan sobre fonética aplicada a la enseñanza / aprendizaje del ELE con alumnos hablantes nativos de coreano, habiendo investigado estrategias correctivas verbotonales para la pronunciación de vocales y consonantes, la percepción del acento prosódico en clases de nivel inicial, intermedio y avanzado, la interpretación auditiva de enunciados declarativos, enfáticos e interrogativos directos en cursos de nivel básico, intermedio y avanzado, así como la interpretación auditiva de enunciados interrogativos directos pronominales con y sin matiz de cortesía en grupos de nivel básico.